









13回分のまとめ
7月からはじまったこの連載。当初、編集長から月4本と言われていたが、流石にそれは厳しく平均月2本となっている。
生成AIは技術の進歩/進化が凄まじいペースで数ヶ月前はもうかなり古い話になることもあり、今回はこれまでの13回分をまとめてみたい。
第一回~三回



ここまではSDXLが出る以前。Negative Promptの重要性、ポーズ/構図の話が中心になっている。使っているModelはSD 1.5だが、これらの内容はSDXLでも共通。知っていて損は無い。
ただSDXLで少し変わったのは、from below(下から)、from behind(後ろから)の効きが悪くなったことだろか。from belowは単に極端なローアングルを一般的なModelでは学習していないだけで、Sexy系のModelだと普通に出る。
from behindはちょうど先日、X(そう言えばこのタイミングではまだTwitterだった)でも話題になったがback viewと書くと後ろ向きの打率が上がる。同じくfrom sideもside viewと書いた方が出易い。
第三回では骨の形でポーズを指定するOpenPoseにも触れている。体だけでなく、手(指を含む)や顔も指定可能なのだが、特に手は例の指問題(生成AIは指が苦手)を低減するのに有効な手段だ。ただあくまでも低減だけであって、根本的に0にはならない。
この件に関しては、そもそもStable Diffusionが「指/手とは何か?」を理解する機能が無く、単独では解決できない。おそらく今後他の技術との合わせ技で解決することになるだろう。
第四回

SDXLは速報も兼ねて発表日に記事を掲載している。特にSDXLはBaseとRefiner、2パス式になっており、AUTOMATIC1111ではどうするの?的な話で当時は混乱していた。
結局AUTOMATIC1111 v1.5ではimage-2-imageでRefinerを…と、変則的な対応をしたが、v1.6で正式対応となり、text-2-imageのメニューにRefinerの項目が増えている。
が、大した効果が無いのと、RefinerもModelの一種で西洋系を中心に学習しており、東洋系の顔に適応するとおかしくなる、そして2パス式なのでそもそも生成に時間がかかる…と良いところ無しで、現在、少なくともアジア系リアルModelでは全く使われていない(笑)。
第五回~六回


この2回は、絵を作るにあたっての基本となるSD 1.5のModelとLoRA(小型の後付Model的なもの)の話が中心。SDXLも基本同じなのだが、まだ出たばかりと言うこともあり、紹介するほどの数も無く、またあってもクオリティがイマイチだったと記憶している。
第七回~九回



この3回は実際に生成AI環境を構築しつつ、AUTOMATIC1111、Fooocus、Fooocus-MREの違い、そしてimage-2-imageとControlNetにも触れている。
AUTOMATIC1111に関してはv1.5、v1.6を経て、現在v1.7RC。おそらく今年中にv1.7が出ると思われる。FooocusからフォークしたFooocus-MREは開発停止となり、現在Fooocusに一本化している(Fooocus-MREの作者も参加)。
本連載であまり取り上げなかった生成AIアプリとして、ComfyUIと言うのがある。ご覧のようにNodeをつなぎ合わせて一つのWorkflowを作り上げる仕掛けなのだが、どうみても玄人向け。初心者だけでなく中級者でも難しそうだ。
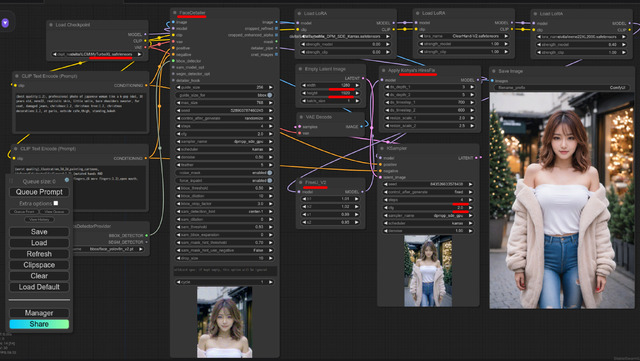
にも関わらず最近人気急上昇中。これには理由があり、LCM、SD/SDXL Turbo、Stable Video Diffusion、AnimateDiff(の新技)など、ここのところ最新技術ラッシュ。これに即(に近いタイミングで)対応するからだ。
一刻も早く新技術を使いたければ、難しいのを承知でComfyUIに挑むことになる。筆者もその内の一人なのだが、一刻も早く!が勝っている間(笑)は、まぁ見様見真似で何とかなる。興味のある人は是非チャレンジして欲しい。
第10回

第一回では学習したModelでの画像をご紹介したが、この回では顔LoRAの作り方を説明している。LoRAの作り方は以下の2つで(Fine tuning方式は難しいので省く)、それぞれ特徴がある。
class+identifier方式
キャプション方式
用意する画像は同じなのだが(顔だと10~15枚、SD 1.5は512x512/SDXLは1024x1024)、1だと例えば akane00 womanと1箇所configに書けば、この識別子(Trigger Word)/属性で学習する。
2は、画像1つ1つに例えば、1girl, camisole, shorts, cafe, など、内容を書いたtextファイルを用意する。これによって、顔以外にも衣装や場所などもPromptを別け学習し、生成する時に顔以外を分離し易くなる。
逆に1だと衣装も場所も全部1つのPromptにまとまってしまうので出てくる画像は学習したものに結構引っ張られる。
と、理屈的にはそうなのだが、何故か1の方が顔は似る(笑)。またSD 1.5よりSDXLの方が激似となるため、筆者は1でSDXLのパターンを好んで使用。加えて簡単なのでこちらをご紹介したと言う経緯となる。
どちらの方式もオプションとして”正則化画像”がある。これは使用するModel素(LoRA無し)の状態でTrigger WordをPromptとして入れた時、出てくる画像の事だ。これを学習させる画像の数倍用意し、「この絵は違うよ!」と合わせて学習。これによってより精度が向上する。
効果はあるにはあるのだが、学習する画像の枚数が大幅に増え、かかる時間が大変なことになる。その割に…なので筆者は初期に試した以降使用していない。
但し、2も正則化画像も顔LoRA作りに限定してイマイチ、1で十分と言っているだけで、他の学習ではまた違った結果になると思われる。
第11回~12回


第11回は以前(二/五/六回)の改訂版。第12回はそのSDXL版となる。SD 1.5かSDXLかどちらがと言う話は、作業環境だったり(SDXLの方が重い)、頑張らないSDXLより頑張ったSD 1.5の方が絵がいい…など、いろいろな要因があり、絶対こっち的な話でもない。
筆者はたまたま爆速の環境があり、絵柄的にSDXLが好み、顔LoRAが似易いなどが理由でSDXLをメインに使っているだけだが、たまにSD 1.5を使うと「お!」な絵が出て関心する時もある。
第13回

第九回でFooocus-MREと共にControlNetの話を軽くしているが、セミナーを行った結果、ControlNetの関心が高いことが分かり、まず一番使われるであろうCanny、Depth、OpenPoseの話を書いた。次回第15回目は続きでReference、Revision、IP-Adapterの話をする予定だ。
この指定した絵(写真)で生成する画像の構図/ポーズや内容や絵柄、Promptなどを固定するControlNet。面白い技術なのだが、生成AIグラビアを作ると言う意味では、似たりよったり的な絵になるため、個人的にはほとんど使っていなかったりする。
+αはModelのマージ、そして今回締めのグラビア
連載の第四回目にはじめてSDXLに対応したリアル系ModelとしてDreamShaper XL1.0 Alpha2、第12回目に個人的に好きなModelとしてCherryPickerXL v2.7をご紹介したが、先日DreamShaper XLとCherryPickerXLが久々にUpdate。しかもTurbo版での登場だ。
このLCMやTurboと呼ばれているModelやLoRA。最大の特徴は通常画像生成する時のStep数は20~30。それを1~8程度に減らす技術。Step数は生成時間に直結するため、少ないほど早く出来るのだが、普通のModelで1~8だと絵にならない。実例をPromptや他の設定は全て同じで下に並べると
 |  |
 |  |
CherryPickerXL v2.7 / Step 4, CFG 5.0 / 1秒
CherryPickerXL v2.7 / Step 20, CFG 5.0 / 5秒
CherryPickerXL-LCM Step4 / Step 4, CFG 2.0 / 1秒
DreamShaper XL Turbo DPMpp SDE / Step 4, CFG 2.0 / 1秒
CherryPickerXL v2.7はStep 4だとまだ絵にならず20でやっと正常の状態。対してLCM/Turboな2つは4 Stepでちゃんとした絵になるのが分かる。当然生成時間はStep 4が圧倒的に速い(RTX 4090)。
が、よく見るとCherryPickerXL-LCM Step4はリアル系と言うよりイラスト寄り、DreamShaper XL Turbo DPMpp SDEは質感はいいものの、Promptでjapanese womanとしているがアジア系は苦手っぽい。
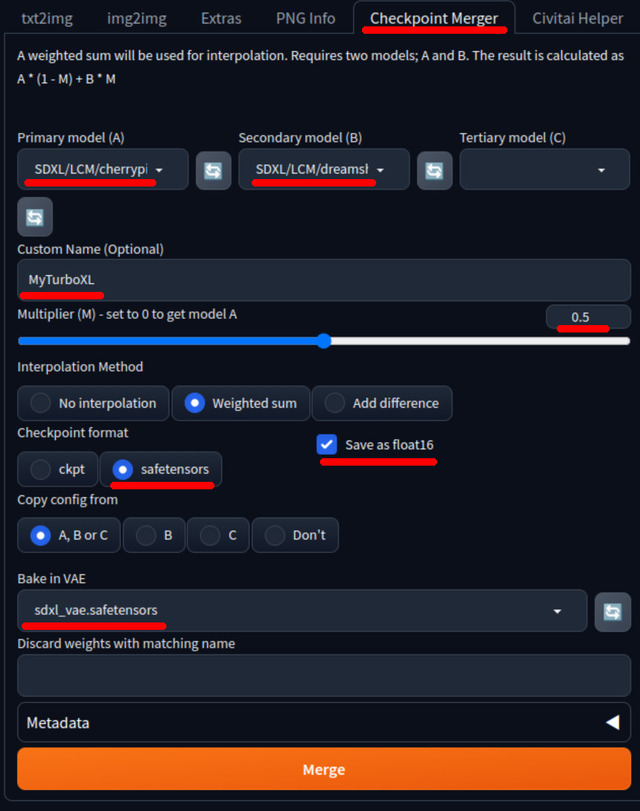
うまく行く保証は無いのだが2つのいいところを取ってマージすれば?と言うことでやってみた。Modelのマージとは、複数のModelを1つのModelにまとめる事を指す。
AUTOMATIC1111の設定方法などは画面キャプチャを参考にして欲しいが、単純にベースCherryPickerXL-LCM Step4に0.5でDreamShaper XL Turbo DPMpp SDEをマージしているだけ。特に難しいことはしていない。マージする時間も大してかからず、指定したファイル名で保存され直ぐ終わる。
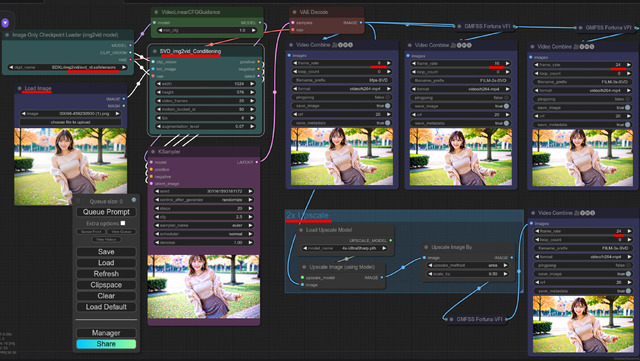
そして結果が今回のグラビアとなる(扉の写真も)。少し工夫したのは先のComfyUIで筆者独自のWorkflowを使っていること。と言ってもキャプションにある通り、大したことはしていない。
なおKohya's HiresFixは第13回で解説したDeep Shrink Hires.fixと同じもの。いきなり1,280x1,920が作れるのでUpscaleするより質感が上がる。
これだけのことをしてもRTX 4090だと4秒を切る。RTX 3060だと約5倍かかるが、それでも20秒切る計算となり、Step 4の威力は絶大と言える。

実際出た絵は如何だろうか。両者のいいところ取りが出来てる感じだ。もちろんどんなModelとでもマージしてうまく行くわけではなく、勘で何となく…と言うところ(笑)。AUTOMATIC1111があれば簡単なので是非試して欲しい。
次回は、ControlNetの続き、Reference、Revision、IP-Adapterの予定だ。おそらく3回目のセミナー後半も同じネタになると思う。