


現役グラビアカメラマンでありエンジニアでもある西川和久氏による生成AIグラビア連載の第21回は、画像生成モデル Stable Diffusionの最新技術がいち早く試せるインターフェース 『ComfyUI』 の応用編。
写真や線画をもとに構図やポーズを指定できる『ControlNet』の具体的な使い方を解説してゆきます。
『生成AIグラビアをグラビアカメラマンが作るとどうなる?連載』


ComfyUIでControlNet (Canny / OpenPose / Depth)を使うには?
ComfyUIでControlNet(Canny/OpenPose/Depth)を使うにはWorkflow以前に各ModelとPreprocessor、そしてカスタムNodeを用意する必要がある。
まずModelは以下からダウンロードする。SD 1.5用とSDXL用とファイルが違うので要注意!ダウンロードしたModelは[ComfyUIのホームフォルダ]/models/controlnet へ入れる。
ただし、SD 1.5用のModelは、diffusion_pytorch_modelと同じファイル名になっているため、control_v11p_sd15_canny、control_v11p_sd15_openpose、control_v11f1p_sd15_depth(など)へリネームする。
次にPreprocessorは、カスタムNodeの ComfyUI's ControlNet Auxiliary Preprocessors に入っているので、ComfyUI Manager > Install Custom Nodesで検索してインストール。これで準備完了だ。
ControlNet / Canny
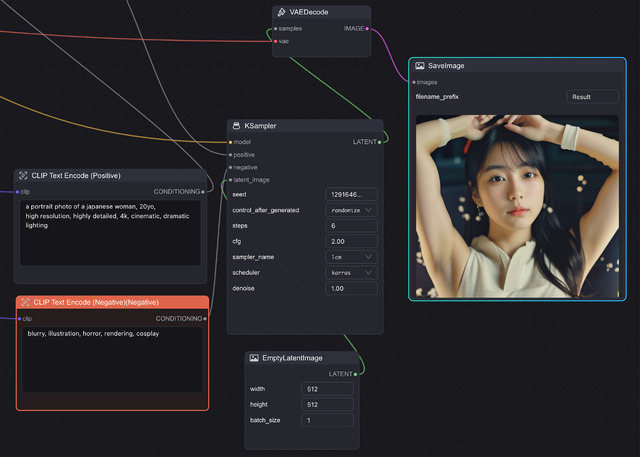
今回はせっかくなので前回ご紹介した。ComflowySpaceを使ってみたい。画面キャプチャからも分かるように、macOS(MacBook Pro 14/M1 Pro/16GB/512GB)上で使用し、Modelは速度的にストレスにならないよう、Detail Asian Realistic v6.0-LCMをSampler: LCM, Scheduler: sgm_uniform, Steps: 6, CFG: 2 で生成。512x512なら9秒と実用範囲に収まっている。
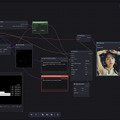
Cannyに関してはWorkflowがTemplatesにあり、それをそのまま使う。設定するのはCheckpointとControl_net_name(control_v11p_sd15_canny)、そしてKSamplerのsteps、cfg、sampler_name、schedulerとなる。
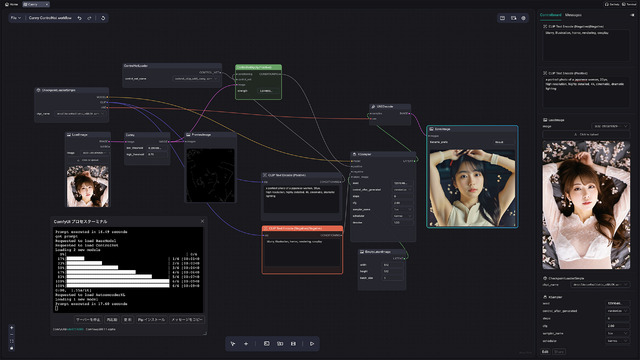
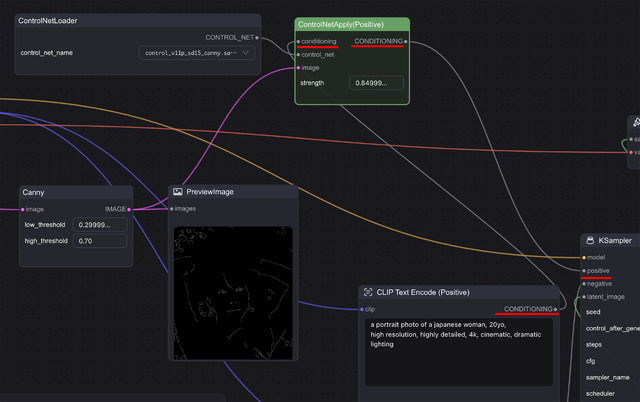
普通の画像生成WorkflowとControlNetを使う時の違いは、PromptのCONDITIONIGからKSamplerのpositiveへ行かず、ControlNetApply(Positive)のconditioningへ入り、CONDITIONIGからKSamplerのpositiveへ繋がっていることだ。加えてControlNetApply(Positive)にはPreprocessor後の画像とControlNetのModelも接続されている。
LoRAはCheckpoint Loader / MODELとKSampler / modelの間に入ったが、ControlNetは、PromptのCONDITIONIGとKSamplerのpositiveの間に入ると言うわけだ。つまり前者はModelの拡張、後者はPromptの拡張…と言う位置付けとなる。
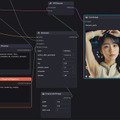
これさえ理解してしまえば、OpenPoseもDepthも基本同じ。LoadするModelとPreprocessorのNodeが違うだけとなる。
ControlNet / OpenPose
OpenPoseのWorkflowもTemplatesにあるのでそれを使用。後はCannyと基本的には同じ。簡単に使うことができる。
ControlNet / Depth
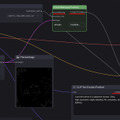
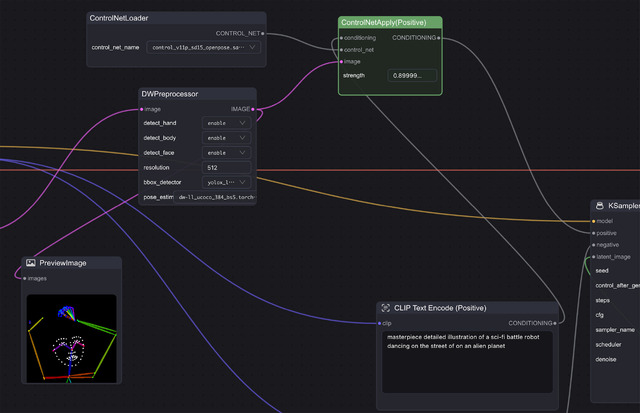
DepthのWorkflowは何故かTemplatesに無いため、上記を踏まえて自分でWorkflowを作ってみた。Nodeは何も無いところでダブルクリックすると検索パネルが出るので、depthと入れそれっぽいのを探す。Preprocessorに関しては色々あったものの、MiDaS-DepthMapPreprocessorを使った。これ以外は上2つと全く同じになる。
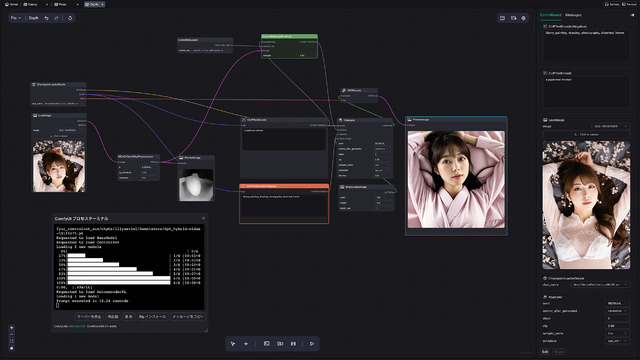
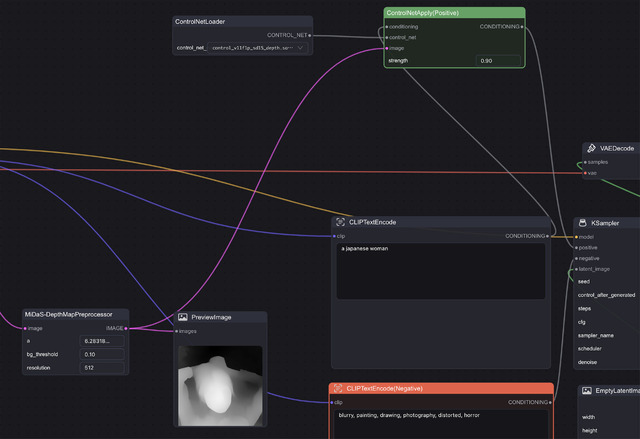
日頃、例えばAUTOMATIC1111だと、ControlNetの項目を開き、手法を選んで、画像を入れて生成…となるが、裏ではこんな感じで動いているのがお分かり頂けただろうか?LoRAなども含め、何がどのように繋がって動いているのかを(何となくでも)理解できるようになるもComfyUIの醍醐味だったりする。
今回締めのグラビア
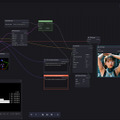
扉とグラビアは前回同様、 CyberRealistic XL v1.1 を使用。(もう終わっているが)卒業式シーズンと言うこともあり、こんな感じにしてみた。
いつもとの違いは、どちらもControlNet / Depthで実写から深度情報を得て画像生成しているところ。
参考までに生成で使用したアプリは、Stable社純正の StableSwarmUI 。これもバックエンドにComfyUIを使っており、ユーザーフレンドリーなUIとComfyUIとを切り替えて使用できる。加えてPython(のGradio)ではなく、.NETを使っているので動きも速い。

掲載した画像2点、筆者XのアカウントでLoRAっ子と呼んでる顔LoRA一号の子が、ちょうど卒業で、「写真撮って!」と言われ、卒業式当日撮影したのがDepthの元画像になっている。

扉はそのものズバリだが(卒業証書の文字…は元々文字が苦手なStable Diffusion。お許しを)、グラビアは、レンタル衣装を返却してからの私服写真を元にした。どちらもその顔LoRAを使用。知ってる人が見ると本人と思うほど似てるかも!?(笑)
さて、ComfyUIに関しては一旦これで終わりとして、次回からはまた新ネタを追ってみたい。現時点では未定。4月に何が発表されるか楽しみだ!
生成AIグラビアをグラビアカメラマンが作るとどうなる?連載一覧
