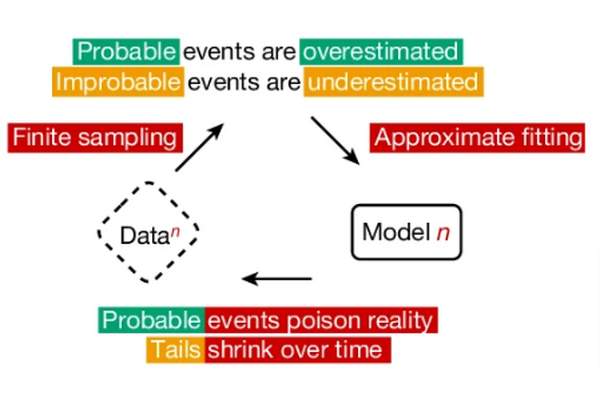







xAIは、大型の言語モデル「Grok-2」と軽量モデル「Grok-2 mini」をベータ版でリリースしました。評価基準の一つであるChatbot Arenaにおいて、Grok-2はGPT-4o miniやClaude 3.5 Sonnetを上回る性能を示しました。また、最近話題の画像生成AI「FLUX.1」が有料で利用できます。

動画生成AI「Runway」が「Gen-3 Alpha Turbo」という新しいモデルを発表しました。生成速度が速く、10秒の動画で2分かかっていたところを17秒で生成できると言います。
さて、この1週間の気になる生成AI技術をピックアップして解説する「生成AIウィークリー」(第60回)では、2万語を一度に出力するモデル「LongWriter」、Googleの画像生成AI「Imagen 3」、そして科学研究を支援する「The AI Scientist」と「OpenResearcher」などを取り上げます。The AI Scientistは論文執筆から査読までのプロセス全体の自動化が特徴で、一方OpenResearcherは検索エンジンと組み合わせて最新論文とやり取りできるのが特徴です。
生成AI論文ピックアップ
AIが生成の画像や動画を細かく制御できるようにする軽量モジュール「ControlNeXt」
より細かな制御可能な生成を実現するため、最近の研究では、深度、人体のポーズ骨格、エッジマップなどの追加の制御を導入しています。現在の制御可能な生成手法は、通常、ControlNet、T2I-Adapter、ReferenceNetなどに見られるように、並列ブランチやアダプターを追加して制御情報を処理します。しかし、この方法では計算コストが大幅に増加します。
本研究では、AIによる画像や動画の生成結果を細かく制御できるようにする軽量なモジュール「ControlNeXt」を提案します。このモジュールは、ControlNetのアーキテクチャ設計を改良しており、並列ブランチを軽量な畳み込みネットワークに置き換えています。これにより、計算コストと追加パラメータを大幅に削減しています。
さらに、新たに提案された「Cross Normalization」技術により、事前学習済みモデルと新しく導入されたパラメータ間のデータ分布の違いを調整します。この工夫により、トレーニングの安定性と収束速度が向上しました。従来手法では数千ステップの学習が必要でしたが、ControlNeXtは数百ステップで制御能力を獲得できるようになり、学習時間を大幅に短縮しています。
ControlNeXtは、さまざまな基本モデルやLoRA(Low-Rank Adaptation)と容易に統合できるプラグアンドプレイ機能を備えています。これにより、追加のトレーニングなしで生成スタイルを変更することが可能になりました。研究チームは、Stable Diffusion 1.5、Stable Diffusion XL、Stable Diffusion 3、Stable Video Diffusionなど、さまざまな画像・動画生成モデルでControlNeXtの有効性を実証しています。





ControlNeXt: Powerful and Efficient Control for Image and Video Generation
Bohao Peng, Jian Wang, Yuechen Zhang, Wenbo Li, Ming-Chang Yang, Jiaya Jia
Project | Paper | GitHub
質を維持した“2万語”を一度に出力するオープンソースAIモデル「LongWriter」
現在の大規模言語モデル(LLM)は、10万トークンを超える長い入力を処理できるようになりましたが、出力の長さは2000語程度に制限されています。研究者たちは、この制限の原因を調査し、教師あり微調整(SFT)データセットの特性に起因することを発見しました。
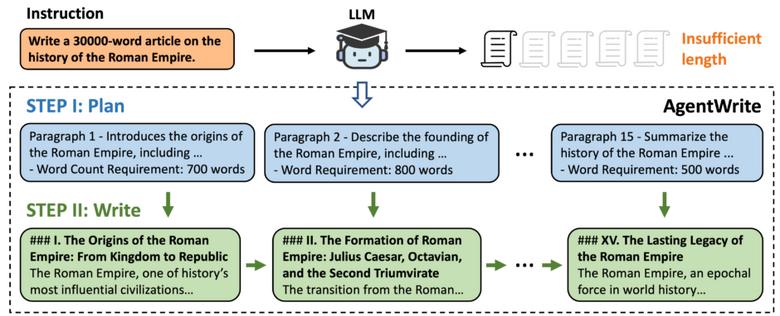
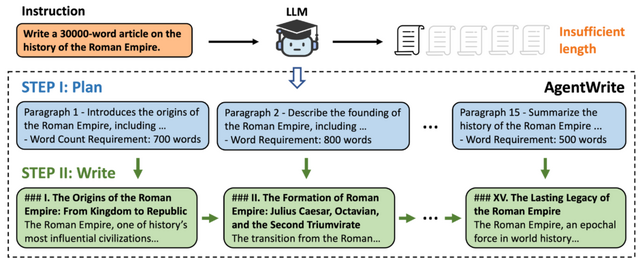
この問題に対処するため、研究チームは「AgentWrite」という新しいエージェントベースのパイプラインを導入しました。AgentWriteは、既存のLLMを活用して、拡張された一貫性のある出力を自動的に構築するように設計されています。このパイプラインは2段階で動作し、まずユーザーの入力に基づいて詳細な執筆計画を作成し、次にその計画に従って各段落のコンテンツを順次生成します。実験により、AgentWriteが最大2万語の高品質で一貫性のある出力を生成できることが確認されました。
AgentWriteパイプラインを基に、研究チームは2000語から3万2000語の長さの出力を含む6000件の教師あり微調整データセット「LongWriter-6k」を生成しました。このデータセットをモデルのトレーニングに組み込むことで、既存のモデルの出力を1万語以上に拡張しつつ、出力の質を維持することに成功しました。
さらに、長文生成能力を評価するためのベンチマーク「LongBench-Write」も開発しました。改良された9Bパラメータのモデルは、このベンチマークで最先端の性能を達成し、大きな非公開モデルをも凌駕しました。

LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs
Yushi Bai, Jiajie Zhang, Xin Lv, Linzhi Zheng, Siqi Zhu, Lei Hou, Yuxiao Dong, Jie Tang, Juanzi Li
Paper | GitHub
論文執筆や査読など科学研究全般を自動化できる「The AI Scientist」をSakana AIが開発
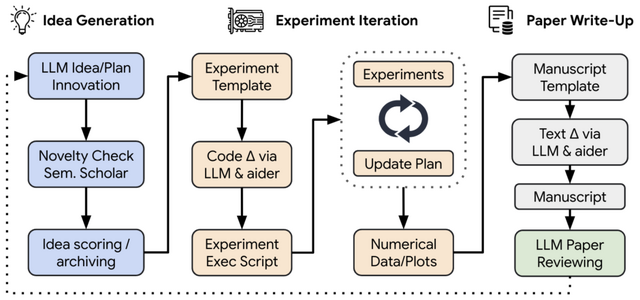
「The AI Scientist」は、新しい研究アイデアの生成から、必要なコードの作成、実験の実行、そして結果の要約、完全な科学論文の形での成果発表まで、研究のライフサイクル全体を自動化します。さらに、生成された論文を評価し、フィードバックを書き、結果を改善するための自動ピアレビュープロセスも導入しています。
しかし、現在のThe AI Scientistにはいくつかの限界があります。例えば、視覚能力がないため、論文の視覚的な問題を修正したり、プロットを読み取ったりすることができません。また、アイデアを誤って実装したり、ベースラインとの不公平な比較を行ったりすることで、誤解を招く結果を生み出す可能性があります。さらに、結果の書き込みや評価において重大な誤りを犯すこともあります。
この技術は、研究者にとって有用なツールとなる可能性がある一方で、悪用の可能性も大きいです。自動的に論文を作成し投稿する能力は、審査プロセスに大きな負担をかけ、科学の質の管理を妨げる可能性があります。また、自動化されたレビュアーが広く採用されると、レビューの質を著しく低下させ、望ましくないバイアスを論文に課す可能性があります。

The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, David Ha
Paper | GitHub | Blog
Googleがテキストから画像を生成するAIモデル「Imagen 3」発表
この研究報告は、GoogleのImagenファミリーに属する最新のモデル「Imagen 3」のトレーニングと評価について述べています。Imagen 3は、テキストプロンプトから高品質な画像を生成する潜在拡散モデルであり、特に写真のリアリズムや複雑なプロンプトへの対応で優れた性能を発揮します。標準設定では1024×1024ピクセルの画像を生成し、さらに2倍、4倍、8倍のアップサンプリングも可能です。
Imagen 3は、写実的な画像や芸術的な画像など、様々なスタイルの高品質な画像を作成できるだけでなく、画像内の物体の数や文字を正確に表現する能力も向上しています。さらに、生成される人物画像において、性別、年齢、肌の色などの多様性が改善されており、より公平な表現が可能になっています。
Imagen 3のトレーニングには、品質と安全性を確保するために、いくつかの段階を経てフィルタリングされています。まず、暴力的な画像や低品質な画像が除外され、AIによって生成された画像が排除されています。これにより、モデルがトレーニング中に不正確なパターンやバイアスを学習するのを防いでいます。また、重複した画像を削除し、同様の画像はデータセット内で重みを減らすことで、過学習を防いでいます。
評価では、Imagen 3は他の最先端モデル(DALLE 3、Midjourney v6、Stable Diffusion 3 Largeなど)と比較して、テキストと画像の整合性、ビジュアルの魅力、詳細なプロンプトと画像の整合性、数的推論能力などの点で優れた性能を示しました。特に詳細なプロンプトに対する対応力や、複数のオブジェクトを正確に描写する能力において優れていました。
また、Imagen 3には、画像のピクセルにデジタル透かしを埋め込むことで、識別可能でありながら人間の目には見えない透かし技術「SynthID」が搭載されています。


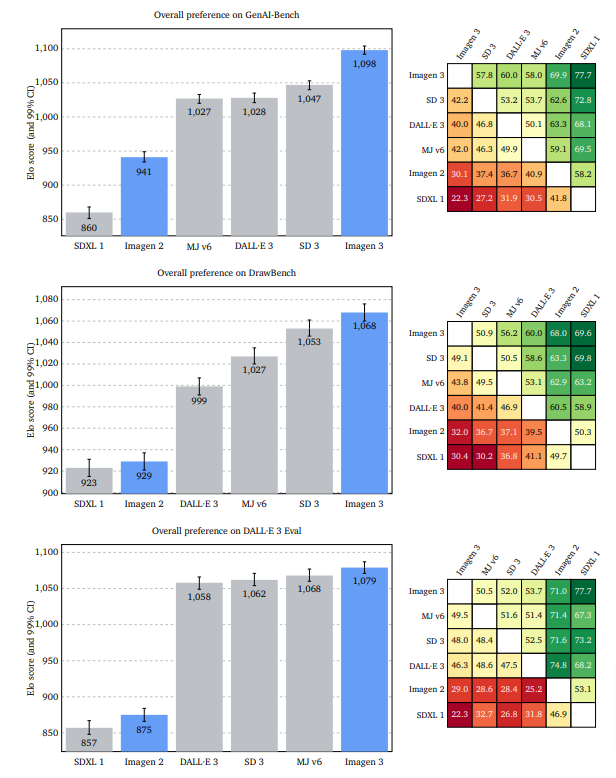
Imagen 3
Imagen-Team-Google: Jason Baldridge, Jakob Bauer, Mukul Bhutani, Nicole Brichtova, Andrew Bunner, Kelvin Chan, Yichang Chen, Sander Dieleman, Yuqing Du, Zach Eaton-Rosen, Hongliang Fei, Nando de Freitas, Yilin Gao, Evgeny Gladchenko, Sergio Gómez Colmenarejo, Mandy Guo, Alex Haig, Will Hawkins, Hexiang Hu, Huilian Huang, Tobenna Peter Igwe, Christos Kaplanis, Siavash Khodadadeh, Yelin Kim, Ksenia Konyushkova, Karol Langner, Eric Lau, Shixin Luo, Soňa Mokrá, Henna Nandwani, Yasumasa Onoe, Aäron van den Oord, Zarana Parekh, Jordi Pont-Tuset, Hang Qi, Rui Qian, Deepak Ramachandran, Poorva Rane, Abdullah Rashwan, Ali Razavi, Robert Riachi, Hansa Srinivasan, Srivatsan Srinivasan, Robin Strudel, Benigno Uria, Oliver Wang, Su Wang, Austin Waters, Chris Wolff, Auriel Wright, Zhisheng Xiao, Hao Xiong, Keyang Xu, Marc van Zee, Junlin Zhang, Katie Zhang, Wenlei Zhou, Konrad Zolna, Ola Aboubakar, Canfer Akbulut, Oscar Akerlund, Isabela Albuquerque, Nina Anderson, Marco Andreetto, Lora Aroyo, Ben Bariach, David Barker, Sherry Ben, Dana Berman, Courtney Biles, Irina Blok, Pankil Botadra, Jenny Brennan, Karla Brown, John Buckley, Rudy Bunel, Elie Bursztein, Christina Butterfield, Ben Caine, Viral Carpenter, Norman Casagrande, Ming-Wei Chang, Solomon Chang, Shamik Chaudhuri, Tony Chen, John Choi, Dmitry Churbanau, Nathan Clement, Matan Cohen, Forrester Cole, Mikhail Dektiarev, Vincent Du, Praneet Dutta, Tom Eccles, Ndidi Elue, Ashley Feden, Shlomi Fruchter, Frankie Garcia, Roopal Garg et al. (151 additional authors not shown)
Paper | Blog
検索エンジンと組み合わせた科学研究アシスタントAI「OpenResearcher」
科学研究の世界では、日々膨大な量の論文が発表され、研究者たちは最新の情報を追跡するのに苦労しています。この課題に対応するため、「OpenResearcher」というAIアシスタントが開発されました。このシステムは、研究者の多様な質問に答え、効率的に情報を提供することで研究プロセスを加速させることを目指しています。
OpenResearcherの核心となる技術は「検索拡張生成」(RAG)と呼ばれるものです。この技術は、大規模言語モデルの持つ広範な知識と、最新の科学論文データベースからリアルタイムで取得される情報を組み合わせます。これにより、システムは常に最新かつ正確な情報を提供することができます。
このシステムの特筆すべき点は、単に受動的に質問に答えるだけでなく、ユーザーと対話的にやり取りを行う能力です。例えば、研究初心者が曖昧な質問をした場合、OpenResearcherは追加の質問を投げかけ、ユーザーの意図をより明確に理解しようとします。これにより、より的確で有用な回答を提供することが可能になります。
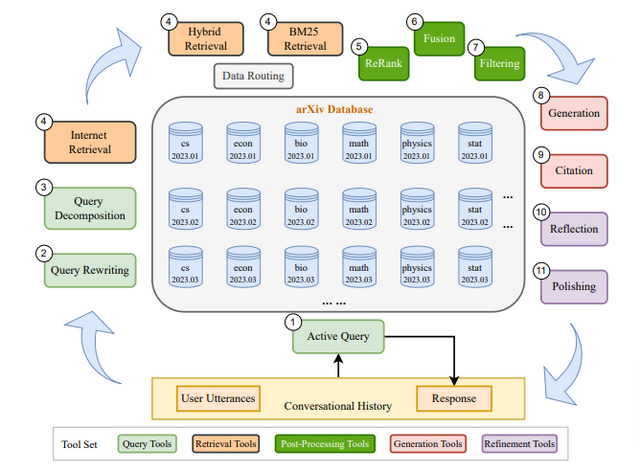
システムの中核となるのは、クエリ理解、情報検索、フィルタリング、回答生成、回答改善などの様々なツールです。OpenResearcherはこれらのツールを柔軟に組み合わせることで、各質問に最適化されたワークフローを構築し、効率的に高品質な回答を生成します。
システムの性能評価のため、開発チームは大学院生から収集した109の研究質問を用いて実験を行いました。これらの質問は、科学論文のおすすめ、科学論文の要約、その他の研究関連の質問をカバーしています。評価は人間の専門家とGPT-4の両方によって行われ、OpenResearcherは情報の正確性、関連性、豊富さの面で既存の産業用アプリケーションを上回る結果を示しました。

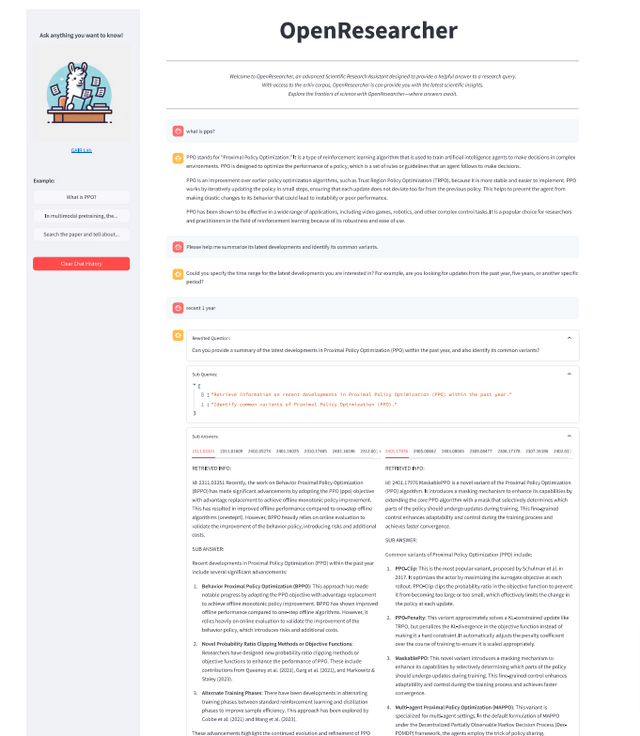
OpenResearcher: Unleashing AI for Accelerated Scientific Research
Yuxiang Zheng, Shichao Sun, Lin Qiu, Dongyu Ru, Cheng Jiayang, Xuefeng Li, Jifan Lin, Binjie Wang, Yun Luo, Renjie Pan, Yang Xu, Qingkai Min, Zizhao Zhang, Yiwen Wang, Wenjie Li, Pengfei Liu
Paper | GitHub