





東京大学 松尾・岩澤研究室が、フルスクラッチで開発のオープンソースな大規模言語モデル(LLM)「Tanuki-8×8B」を発表しました。日本語レベルを評価するベンチマークで、GPT-3.5 Turboと同等レベルのスコアを達成しています。
Googleは、最新の画像生成AI「ImageFX」(Imagen 3)を発表しました。実写系や人物画像において、写実的で高品質に出力すると話題になっています。
動画生成AI「Runway Gen-3」が、40秒の映像を作り出せるようになりました。Gen-3 Alphaのみですが、5秒か10秒の映像生成からプロンプトを加えて最大40秒まで一貫性を維持して繋げる仕様です。

さて、この1週間の気になる生成AI技術をピックアップして解説する「生成AIウィークリー」(第62回)では、主要LLMでは制限がかかるような内容でも精度高く出力できるローカルLLM「Command R+」の最新バージョンや、論文などのドキュメントとチャットできるAIインタフェース「kotaemon」を取り上げます。
他にもアリババグループの新しい視覚言語モデル「Qwen2-VL」や、FPSタイトル「DOOM」のプレイ画面をリアルタイムで画像生成するGoogle開発のゲームエンジン「GameNGen」などをご紹介します。
■ローカルLLM「Command R」と「Command R+」の最新バージョンが登場
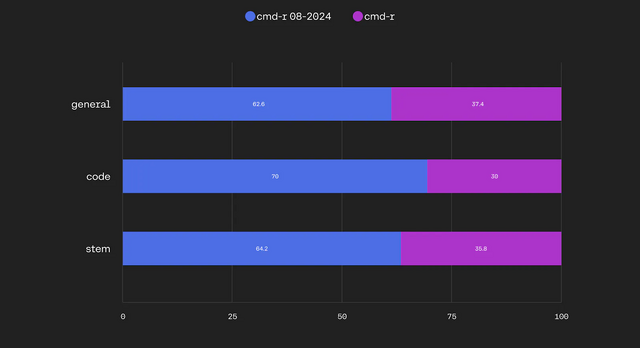
Cohereは、大規模言語モデルであるCommand RシリーズのCommand R(35B)とCommand R+(104B)のアップデート版をリリースしました。これらのモデルは、12万8000トークンのコンテキストウィンドウを備え、検索拡張生成(RAG)、日本語含む10言語以上の多言語に対応しています。
Command Rシリーズは、主要なLLM(GPT、Claude、Geminiなど)では生成できない、成人向けコンテンツなどの制限されている内容でも出力できることでも知られています。新バージョンでは、それらの分野を含め、コーディング、数学、推論、レイテンシーなどで進歩が見られます。
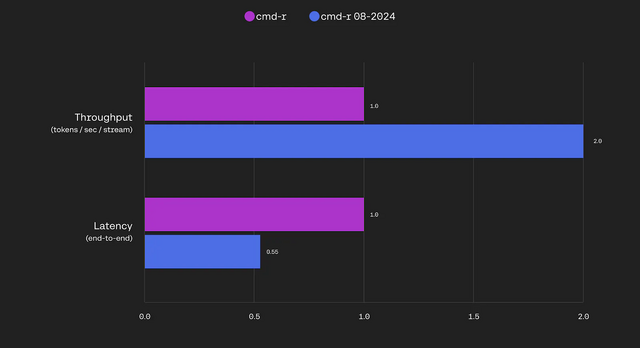
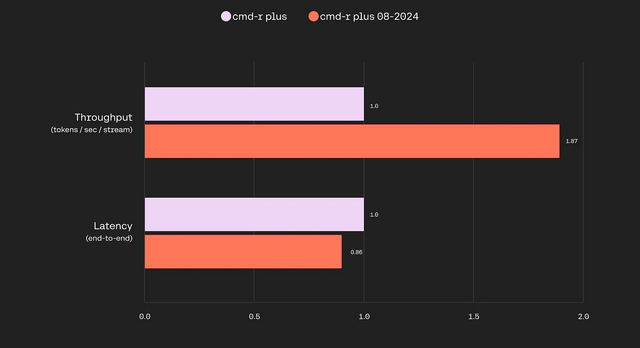
軽量型のCommand Rは、応答速度向上など全体的な性能が大きく向上し、以前のCommand R+の性能に匹敵するレベルになりました。大型のCommand R+では、前バージョンと比べてスループットが87%向上し、レイテンシも14%低減しています。


Updates to the Command R Series
Blog
■2枚の画像から高品質な3Dシーンを生成するAIモデル「ReconX」
「ReconX」は、少数の視点画像(最小2枚)から高品質な3Dシーンを生成することを目的としています。清華大学と香港科技大学の研究者らによって開発されました。
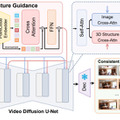
従来の3D再構築手法では、見えていない領域でアーティファクトや歪みが生じやすい課題がありました。ReconXはこの問題に対し、3D再構築タスクを時系列生成タスクとして再定式化するという新しいアプローチを取っています。
具体的には、画像をアニメーション化する事前学習されたビデオ拡散モデル「DynamiCrafter」の生成能力を活用し、少数の入力画像から一貫性のある多視点画像を生成します。この際、入力画像から大域的な点群を構築し、これを3D構造の条件として符号化します。
この条件付けによって、ビデオ拡散モデルは詳細を保持しつつ3D一貫性の高いビデオフレームを生成できるようになります。最後に、生成されたビデオから3D Gaussian Splattingを用いて3Dシーンを復元します。
実験では、RealEstate10KやACIDなどの実世界データセットにおいて、ReconXが既存手法を大きく上回る性能を示しました。特に入力視点間の角度が大きい難しい設定でも、ReconXは高品質な結果を維持できています。また、学習データと異なるデータセットでの評価でも優れた汎化性能を示しました。

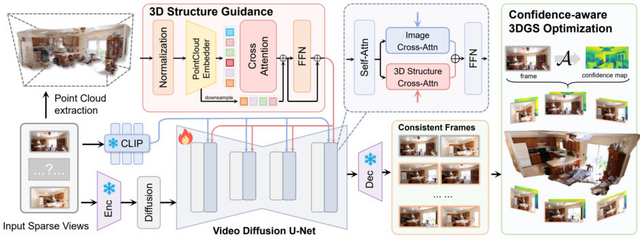
ReconX: Reconstruct Any Scene from Sparse Views with Video Diffusion Model
Fangfu Liu, Wenqiang Sun, Hanyang Wang, Yikai Wang, Haowen Sun, Junliang Ye, Jun Zhang, Yueqi Duan
Project | Paper | GitHub | Demo
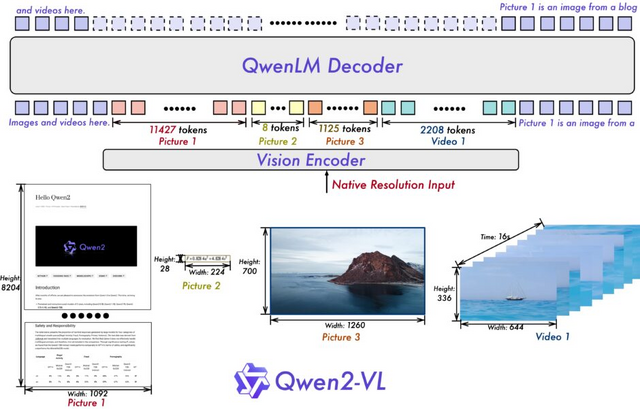
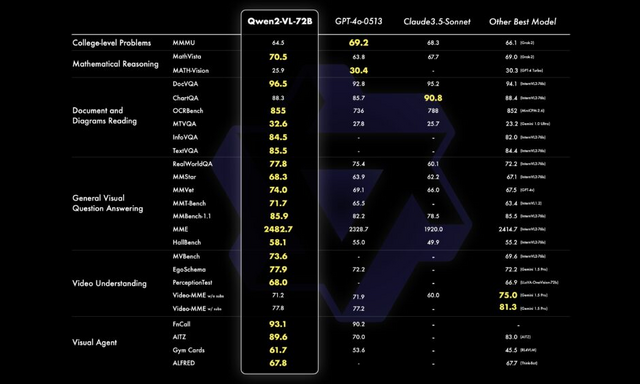
■画像内の日本語を高度に理解するオープンな視覚言語モデル「Qwen2-VL」 GPT-4oやClaude 3.5-Sonnetを上回る性能
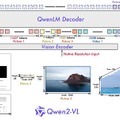
Qwen2-VLは、アリババグループが開発するQwenモデルファミリーの中でQwen2をベースにした最新の視覚言語モデルです。前バージョンのQwen-VLと比較して、Qwen2-VLは様々な解像度と比率の画像を理解する能力において最先端の性能を発揮します。
20分以上の長さの動画を理解し、複雑な推論や意思決定能力を持ちます。また、日本語を含め、英語、ヨーロッパで使われる主な言語、中国語、韓国語、アラビア語、ベトナム語など、画像内の様々な言語のテキストを理解することができます。
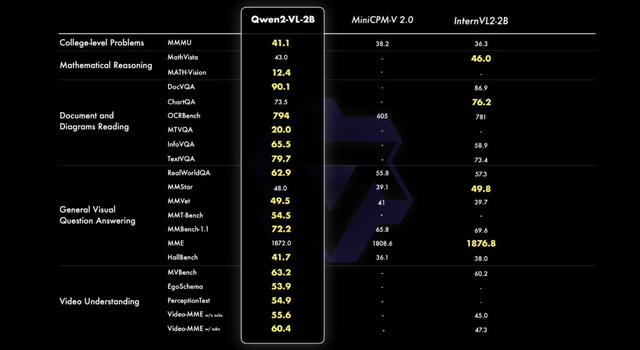
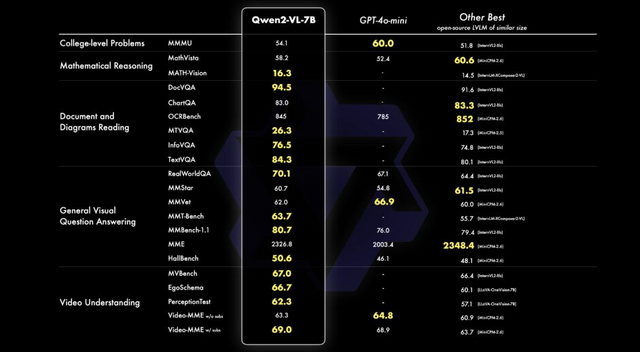
Qwen2-VLの性能は、数学的能力、文書や表の理解、画像理解、質問応答、動画理解、エージェントベースの相互作用など、様々な分野で評価されています。72Bモデルは、ほとんどの指標で最高レベルの性能を示し、多くの場合、GPT-4oやClaude 3.5-Sonnetなどの非公開モデルを上回っています。
Qwen2-VL-2BとQwen2-VL-7Bは、Apache 2.0ライセンス下でオープンソース化されており、Qwen2-VL-72BのAPIも公開されています。

■生成AI搭載ゲームエンジン「GameNGen」をGoogleが開発 ゲーム「DOOM」のプレイ画面をリアルタイムに画像生成
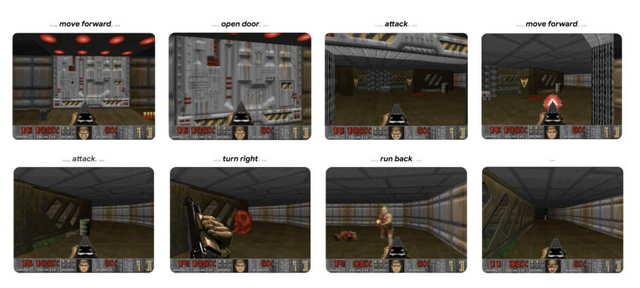
Googleは、ニューラルモデルで構成されたゲームエンジン「GameNGen」を開発しました。複雑な環境とリアルタイムでインタラクティブに対話できる生成能力を持っています。
デモでは、一人称シューティングゲーム「DOOM」をシミュレートし、1台のTPU上で1秒間に20フレーム以上の速度で動作させることに成功しました。
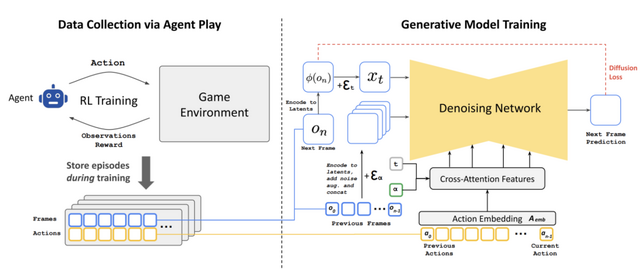
具体的には、プレイヤーの移動や視点移動、アクションなどの入力に応じて、プレイ画面の画像を瞬時に生成します。これは「Stable Diffusion v1.4」の拡張版を基に生成しています。また、プレイヤーの体力と弾薬の計算、敵への攻撃、オブジェクトへのダメージ、ドアの開閉などのゲーム内でのイベントもAIが管理し更新します。
人間の評価者がシミュレーションと実際のゲームの短いクリップを区別するテストでは、ランダムな選択とほぼ同程度の結果となり、シミュレーションの高い品質が示されました。
このシステムは2段階で学習されます。まず、強化学習エージェントがゲームのプレイ方法を学習し、そのセッションが記録されます。次に、拡散モデルが過去のフレームとアクションの系列を条件として、次のフレームを生成するよう学習します。
Diffusion Models Are Real-Time Game Engines
Dani Valevski, Yaniv Leviathan, Moab Arar, Shlomi Fruchter
Project | Paper
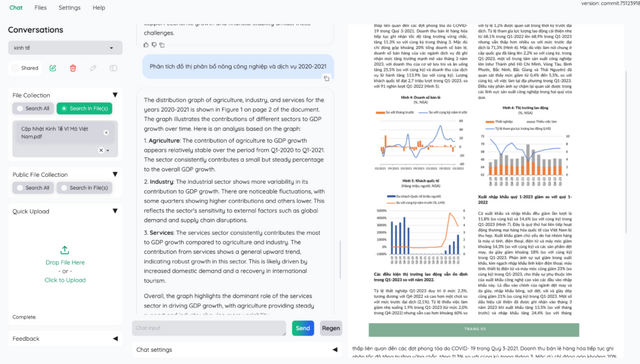
■論文などのドキュメントとチャットで対話できるオープンソースなAIインタフェース「kotaemon」
kotaemonは、ユーザーが任意のドキュメントとチャットできる検索拡張生成(RAG)ベースのAIインタフェースです。kotaemonは、ドキュメントに対するQ&Aを行いたいエンドユーザーと、独自のRAGパイプラインを構築したい開発者の両方にサービスを提供します。
エンドユーザー向けには、RAGベースのQ&AのためのUIを提供し、OpenAI、AzureOpenAI、CohereなどのLLM APIプロバイダーや、ollamaやllama-cpp-pythonを介したローカルLLMをサポートしています。
開発者向けには、独自のRAGベースのドキュメントQ&Aパイプラインを構築するためのフレームワークを提供しています。Gradioで構築されたUIを使用して、RAGパイプラインをカスタマイズし、実際の動作を確認することができます。
kotaemonの主な特徴には、ドキュメント内の文章や図へのQ&A、ローカルLLMとAPIプロバイダーのサポート、LLM回答の正確性を保証するために詳細な引用を提供などが挙げられています。



















![グッドスマイルカンパニー[GOOD SMILE COMPANY] PLAMATEA 如月ハニー 組み立て式プラモデル ノンスケール image](https://m.media-amazon.com/images/I/416Sue5uTYL._SL160_.jpg)