




OpenAIが新たに強力な推論モデル「OpenAI o1」と、高速で安価な推論モデル「 OpenAI o1-mini」を発表しました。o1は従来モデルより時間をかけて考えることで、複雑なタスクの正答率が大幅に向上します。
国際数学オリンピック予備試験での正答率はGPT-4oの13%から83%に上昇し、安全性テストでも3倍以上の高いスコアを記録しました。o1は ChatGPT PlusとTeamユーザーに提供され、APIでもプレビュー版の利用が可能となります。
Adobeが動画生成AI「Adobe Firefly Video」を発表しました。テキストや画像から動画を生成するだけでなく、角度、モーション、ズームなどの豊富なカメラコントロールを活用して、生成されたビデオに別の視点を作成できます。
例えば、虫眼鏡で花を見る少女の動画から、虫眼鏡越しに映る花のズームシーンを生成することができます。Adobe Firefly Videoは、使用許可を得たコンテンツのみでトレーニングされるため、商業的に安全になるように設計されていると言います。今年後半にベータ版として利用可能になる予定です。
Googleは、AIの幻覚に対処するため、実世界のデータを活用する「DataGemma」を発表しました。これは、GoogleのData Commonsの膨大な統計データに基づいて大規模言語モデル(LLM)を強化するオープンモデルです。
Data Commonsは2,400億以上のデータポイントを活用し、国連やWHOなどの信頼できる組織から収集した公開情報を統合しています。
フランスのAIベンチャー「Mistral AI」は、マルチモーダルAIモデル「Pixtral 12B」を発表しました。
さて、この1週間の気になる生成AI技術・研究をピックアップして解説する「生成AIウィークリー」(第64回)では、オープンソースな音声AI技術を2つ、AIと音声対話できる「LLaMA-Omni」と、テキストを読み上げる「Fish Speech V1.4」を取り上げます。
また、活気が出てきたゲーム生成AIの新モデル、オープンワールドゲームを生成するAI「GameGen-O」をご紹介します。
そして、生成AIウィークリーの中でも、特に興味深い技術や研究にスポットライトを当てる「生成AIクローズアップ」では、LLMの幻覚はどんな対処をしても避けることができない現象を指摘した研究を単体で掘り下げます。
生成AIのハルシネーションは原理的に排除不能。不完全性定理など数学・計算機理論で説明 モデル改良や回避システムでも不可避とする論文(生成AIクローズアップ)
AIと音声対話できるオープンソースモデル「LLaMA-Omni」 応答遅延が最短で226ミリ秒
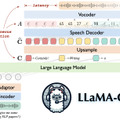
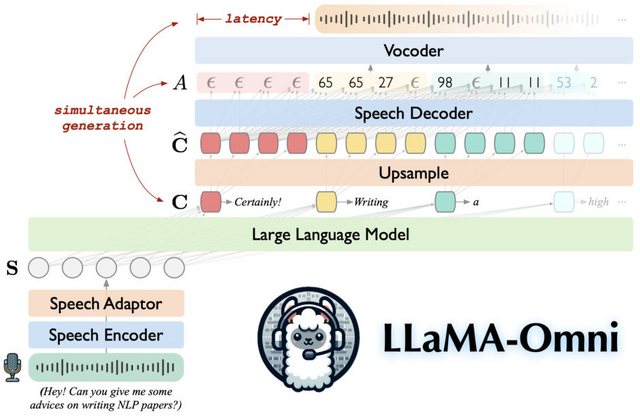
LLMとの音声対話を可能にするモデル「LLaMA-Omni」が開発されました。このモデルは、話しかけるとその内容に応じた音声を出力してくれる、低遅延で高品質な音声対話システムです。
LLaMA-Omniは、Llama-3.1-8B-Instructモデルをベースに構築されており、音声エンコーダー、音声アダプター、LLM、ストリーミング音声デコーダーで構成されています。このアーキテクチャにより、音声認識を介さずに直接音声指示からテキストと音声の応答を同時に生成することが可能になります。
このモデルは、音声エンコーダーを用いて音声理解を行い、ストリーミング音声デコーダーを使ってテキストと音声の応答を同時に生成します。これにより、テキスト応答の生成を待たずに音声応答の再生を開始できるため、ユーザーとの対話における応答性が向上します。
音声対話シナリオに適応させるため、研究チームは「InstructS2S-200K」というデータセットを作成しました。これには20万件の音声指示とそれに対応する音声応答が含まれています。
実験結果によると、LLaMA-Omniは従来の音声言語モデルと比較して、内容とスタイルの両面で優れた応答を提供し、応答遅延は最短で226ミリ秒という速さを達成しました。

LLaMA-Omni: Seamless Speech Interaction with Large Language Models
Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui Ma, Shaolei Zhang, Yang Feng
Paper | GitHub
テキストを読み上げる日本語対応のオープンソースモデル「Fish Speech V1.4」
自然な音声でテキストを読み上げるText to Speech(TTS)のオープンソースモデル「Fish Speech V1.4」がリリースされました。 商用利用はできませんが、低遅延のコンパクトモデル(約1GBの重み)です。
今回のアップデートでは、学習データが大幅に増加し、70万時間の多言語データを用いて学習が行われました。これは以前の20万時間から大きく増加しております。また、対応言語も拡大され、英語、中国語、ドイツ語、日本語、フランス語、スペイン語、韓国語、アラビア語の8言語をサポートするようになりました。

Fish Speech 1.4
GitHub | Hugging Face | Demo
制御可能なオープンワールドビデオゲームを生成するAIモデル「GameGen-O」
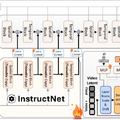
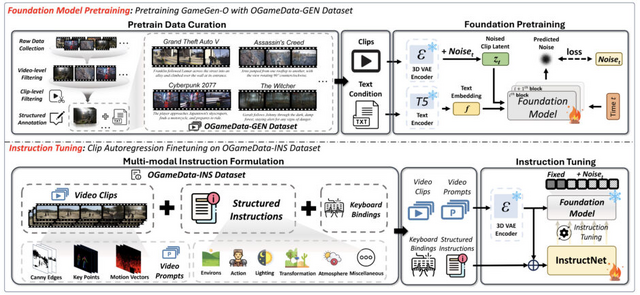
「GameGen-O」は、オープンワールドビデオゲームの生成に特化した拡散モデルです。このモデルは、キャラクター、動的な環境、複雑なアクション、多様なイベントなど、幅広いゲームエンジン機能をシミュレートすることで、高品質かつオープンドメインの生成を可能にします。さらに、インタラクティブな制御性を提供し、ゲームプレイのシミュレーションを可能にしています。
例えば、「アーサー・モーガン」のようなキャラクター、四季の変化や様々な地形などの環境、バイク走行や飛行などのアクション、雨や雪、雷などのイベントを生成できます。さらに、「中華街を歩くサイバーモンク」や「火星を歩く旅人」のような独創的なシーンも生成可能です。
指示プロンプト、操作信号、ビデオプロンプトなどを用いて、生成されるコンテンツを制御できます。例えば、「空に火が現れる」や「霧が発生する」といった指示や、左右へのキャラクターの移動命令などが可能です。
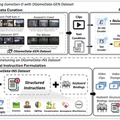
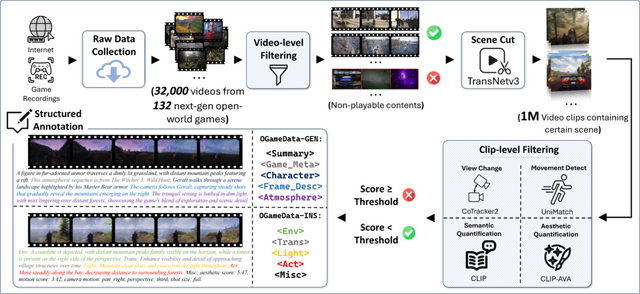
研究チームは、「Open-World Video Game Dataset」(OGameData)と呼ばれるオープンワールドビデオゲームデータセットを構築しました。OGameDataは、3万2000以上の動画から厳選された4000時間以上の高品質ビデオクリップを含む包括的なデータセットです。150以上の次世代ゲームをカバーし、様々なジャンル、視点、スタイルを網羅しています。

GameGen-O: Open-world Video Game Generation
Haoxuan Che, Xuanhua He, Quande Liu, Shengju Qian, Cheng Jin, Xin Wang, Hao Chen
Project | GitHub
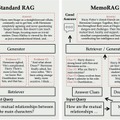
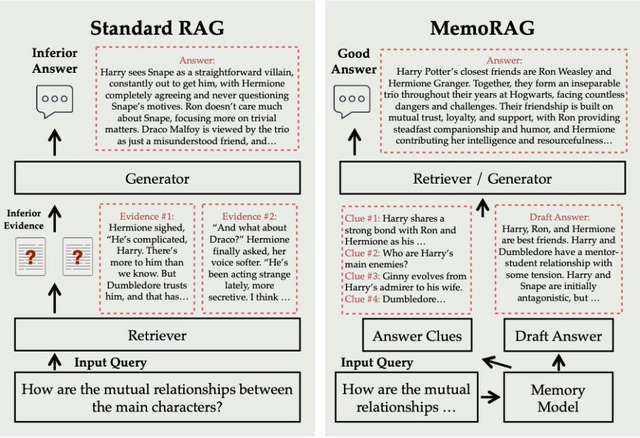
曖昧で複雑な質問も検索して答えてくれるRAG系AIモデル「MemoRAG」
「MemoRAG」は、LLMがより賢く情報を検索し、回答を生成できるようにする新しい方法です。
従来の検索拡張生成(RAG)システムは、はっきりした質問に対して整理された情報を探すのは得意でしたが、曖昧な質問や整理されていない情報を扱うのは苦手でした。
MemoRAGは、人間の記憶メカニズムを模倣したデュアルシステムアーキテクチャにあります。このシステムは、軽量ながら長期処理が可能なLLMを使用してデータベース全体のメモリを形成します。
これは人間の長期記憶に似た機能を果たし、与えられたタスクに対して概略的な回答を生成します。この概略回答は、より詳細な情報を検索するための手がかりとして機能します。
同時に、MemoRAGは高度な表現力を持つLLMを採用し、検索された詳細情報に基づいて最終的な回答を生成します。この2段階プロセスにより、システムは複雑な質問や長い文脈タスクに対しても、より正確で洞察力のある回答を提供することが可能になります。
MemoRAGの性能を評価するために、「ULTRADOMAIN」と呼ばれる包括的なベンチマークを開発しました。実験結果は、MemoRAGの優位性を明確に示しました。
従来のRAGシステムが困難を感じる複雑なタスクだけでなく、RAGが一般的に得意とする単純なタスクにおいても、MemoRAGは卓越したパフォーマンスを発揮しました。特筆すべきは、金融や法律などの専門分野におけるタスクでの顕著な性能向上です。
さらに、MemoRAGは最大100万トークンという非常に長い文脈を効果的に処理する能力を実証しました。これは、教科書、金融レポート、法律文書など、大規模かつ複雑なテキストデータを扱う際の強力な利点となります。
MemoRAG: Moving towards Next-Gen RAG Via Memory-Inspired Knowledge Discovery
Hongjin Qian, Peitian Zhang, Zheng Liu, Kelong Mao, Zhicheng Dou
Paper | GitHub









![【DL版】【初期費用3,300円が無料 ※1契約者1回線/年に限り】IIJmioえらべるSIMカード エントリーパッケージ 月額利用(音声SIM/SMS)[ドコモ・au回線]・(データ/eSIM/プリペイド)[ドコモ回線]IM-B327 image](https://m.media-amazon.com/images/I/51EBpYkc-DL._SL160_.jpg)











