







Metaは「Llama」の最新バージョン「Llama 3.2」を発表しました。このモデルにはマルチモーダルLLM(11Bと90B)と、エッジデバイスや携帯端末で動作する軽量テキストのみのモデル(1Bと3B)が含まれています。
OpenAIが音声モード「Advanced Voice Mode」をPlusとTeamユーザー向けに提供を開始しました。応答が速く、感情豊かで、まるで人間と会話しているかのような音声による対話機能です。

Googleが新型バージョン「Gemini 1.5 pro 002」と「Gemini 1.5 Flash 002」を発表しました。新モデルでは、全体的な品質が向上し、特に数学、長文脈理解、視覚タスクで大きな進歩が見られます。MMMLUやMATHなどのベンチマークで7~20%の性能向上が確認されています。
さて、この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第66回)では、2つの新しいマルチモーダルモデル「Emu3」と「Molmo」を取り上げます。Emu3は拡散アーキテクチャを使用しないモデルで、Molmoは人間が画像を見て音声でラベル付けした独自データセットを使用したモデルです。
また、PDFの内容をポッドキャストや講義、要約形式などの音声に変換する「PDF2Audio」、画像内のキャラクターに滑らかな動きを付与できるビデオ合成モデル「MIMO」をご紹介します。
そして、AIで編集された画像や動画によって人間の記憶をどれだけニセの記憶に上書きできるかを調査した、MIT主導の研究を単体で掘り下げます。

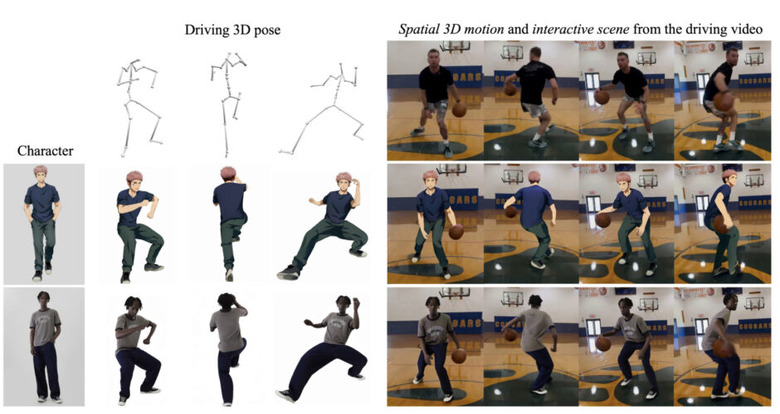
1枚の画像から多様なキャラクターを制御可能な3Dアニメーションビデオに変換するAIフレームワーク「MIMO」
「MIMO」は、制御可能なキャラクタービデオ合成のためのフレームワークです。このシステムは、単一画像の参照キャラクターを使用して、モーションデータセットから取得した3Dポーズや実世界の動画から抽出したポーズでアニメーション化されたアバターを合成することができます。
例えば、1枚の写真と動きのデータを入力するだけで、その写真の人物が自然に動くビデオを作成することができます。さらに、背景となる実際の風景の中に、その人物を自然に溶け込ませ、オブジェクトとの相互作用も表現できます。
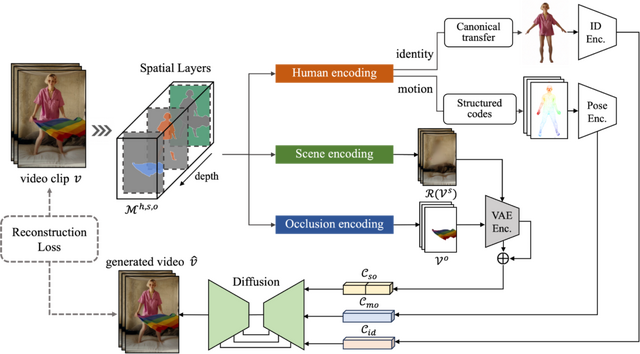
MIMOの特徴は、ビデオを3つの空間的要素(主要な人物、背景となるシーン、オクルージョンする前景オブジェクト)に分解して処理することです。これらを3D空間で考慮することで、柔軟なユーザー制御、複雑な3Dモーション表現、およびシーンの相互作用のための3D対応の合成が可能になります。
ユーザーは、キャラクター、モーション、シーンに対して非常に簡単な入力(例えば、キャラクターには単一の画像、モーションにはポーズシーケンス、シーンには単一の動画/画像)を提供するだけで、望みの属性を持つキャラクタービデオを生成することができます。





MIMO: Controllable Character Video Synthesis with Spatial Decomposed Modeling
Yifang Men, Yuan Yao, Miaomiao Cui, Liefeng Bo
Project | Paper | GitHub
拡散モデルを使用しない、新しいマルチモーダルAIモデル「Emu3」、画像生成はSDXLと同等以上の性能
「Emu3」は、画像・動画・テキストを統合的に扱う新しいマルチモーダルモデルです。モデルのアーキテクチャは、既存の大規模言語モデルの枠組みを踏襲しつつ、視覚トークンを扱えるように拡張されています。8Bパラメータ、32層、4096次元の隠れ層を持つTransformerモデルとなっています。
Emu3の特徴は、「次のトークン予測」という単一のタスクで学習を行う点にあります。従来の手法とは異なり、画像や動画をトークン化して離散的な空間に変換し、単一のTransformerモデルを一から学習させることで、拡散モデルや複合的なアプローチ(CLIPなど)を必要としない設計となっています。
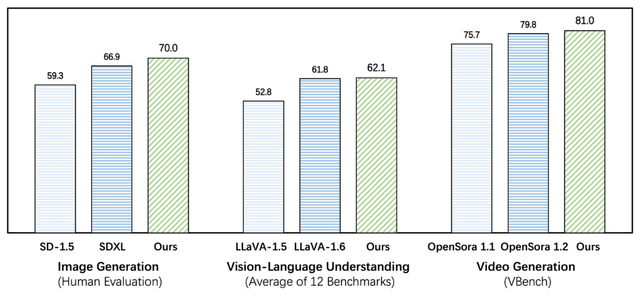
Emu3の評価結果は、画像生成、動画生成、画像理解の3つの主要な分野で行われました。画像生成タスクでは、複数のベンチマークで評価され、Stable Diffusion XLやDALL-E 3といった最先端のモデルと同等以上の性能を達成しました。
動画生成タスクでは、ベンチマークにおいて、OpenSora-1.2を含む拡散モデルベースの最新モデルと競争力のある結果を示しました。
画像理解タスクでは、多岐にわたるベンチマークで評価され、事前学習済み言語モデルや特殊なエンコーダーを使用せずに、既存の視覚言語モデル(LLaVA-1.6など)を上回る性能を達成しました。


PDFの内容をポッドキャストに変換するオープンソースAIツール「PDF2Audio」
Googleは先日、自分用に最適化できるAIノート「NotebookLM」に新機能「Audio Overview」を追加しました。この機能は、ドキュメントやスライドなどの資料を対話形式の音声に変換できるという技術です。
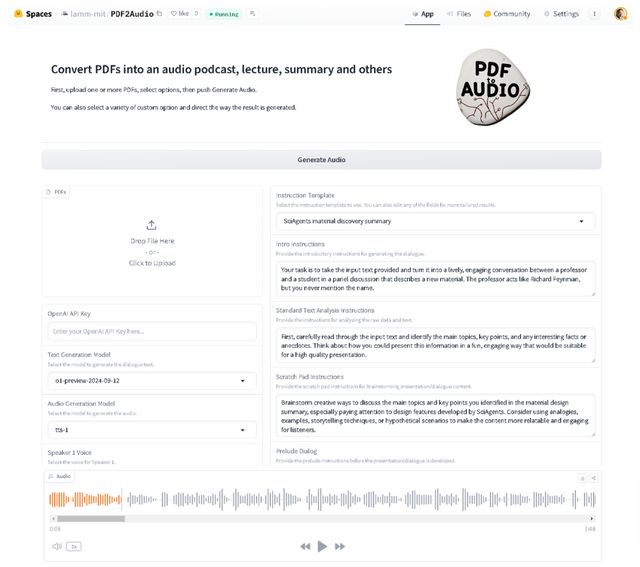
「PDF2Audio」も類似した技術で、PDFファイルの内容を音声に変換し、ポッドキャスト、講義、ディスカッション、短編・長編要約など様々な形式で聞くことができるオープンソースツールです。技術書や学術論文など、複雑な内容を音声に変換してインプットすることができます。
PDF2Audioは、OpenAIのGPTモデル(o1含む)を使用してテキスト生成とテキスト読み上げを行います。単にPDFを音声に変換するだけでなく、生成された音声の編集や声の選択、フィードバックに基づいた改善も可能で、ユーザーの好みに合わせてカスタマイズできます。
主な機能には、複数のPDFファイルの一括アップロード、音声出力形式の選択(ポッドキャスト・講義・要約など)、指示テンプレートのカスタマイズ、テキスト生成と音声モデルのカスタマイズ、話者に応じた声の選択、ドラフトの編集とフィードバックなどがあります。

新しい視覚言語モデル「Molmo」は人間が画像を見て音声でラベル付けを行う独自データセット「PixMo-Cap」が特徴
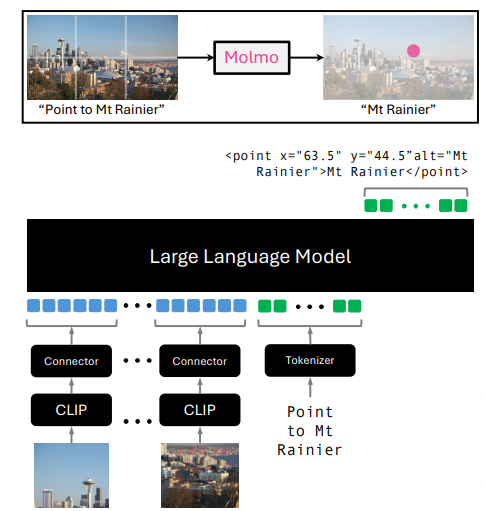
Allen Institute for AIとワシントン大学の研究チームが、新しいオープンソースの視覚言語モデル(VLM)ファミリー「Molmo」を発表しました。Molmoは、画像と言語を組み合わせて処理できる人工知能モデルで、これまでの最高性能のVLMが非公開だったのに対し、モデルの重み、トレーニングデータ、コードなどをすべて公開しているのが特徴です。
Molmoの開発において、研究チームはデータセットの作成に拘りました。人間のアノテーターに画像を見せ、60~90秒間音声で詳細に説明してもらうという方法です。この手法により、高品質で密度の高い画像キャプションデータセット「PixMo」を作成することができました。音声での説明は、タイピングよりも短時間で詳細な情報を得られ、また他のAIモデルを使用して回答をコピーペーストするリスクも避けられます。
Molmoの構造は、既存の画像エンコーダーと言語モデルを組み合わせたシンプルなものです。まず、PixMo-Capを使ってキャプション生成を学習し、その後、さまざまなタスクに対応できるよう微調整を行います。
Molmoファミリーは、1Bから72Bまでの異なるサイズのモデルを含んでいます。性能評価では、11のベンチマークと人間による評価の両方で優れた結果を示しました。最も効率的なMolmoE-1BはGPT-4Vにほぼ匹敵する性能を、7Bモデル(Molmo-7B-OとMolmo-7B-D)はGPT-4VとGPT-4oの間の性能を示しました。最高性能の72Bモデルは、ベンチマークで最高スコアを達成し、人間による評価でもGPT-4oに次ぐ2位にランクインしています。Molmo-72BはGemini 1.5 ProやFlash、Claude 3.5 Sonnetなどの最新の非公開システムを上回る性能を示しています。

Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, Jiasen Lu, Taira Anderson, Erin Bransom, Kiana Ehsani, Huong Ngo, YenSung Chen, Ajay Patel, Mark Yatskar, Chris Callison-Burch, Andrew Head, Rose Hendrix, Favyen Bastani, Eli VanderBilt, Nathan Lambert, Yvonne Chou, Arnavi Chheda, Jenna Sparks, Sam Skjonsberg, Michael Schmitz, Aaron Sarnat, Byron Bischoff, Pete Walsh, Chris Newell, Piper Wolters, Tanmay Gupta, Kuo-Hao Zeng, Jon Borchardt, Dirk Groeneveld, Jen Dumas, Crystal Nam, Sophie Lebrecht, Caitlin Wittlif, Carissa Schoenick, Oscar Michel, Ranjay Krishna, Luca Weihs, Noah A. Smith, Hannaneh Hajishirzi, Ross Girshick, Ali Farhadi, Aniruddha Kembhavi
Project | Paper
























