









生成AIグラビアをグラビアカメラマンが作るとどうなる? 連載記事一覧
10月22日待望のStable Diffusion 3.5登場!
以前Stable Diffusion 3 Mediumのクオリティ問題で、数週間後に修正版を出すと発表があったが、10月22日、遂にその修正版がStable Diffusion 3.5 Largeとなって登場した。
Largeなので8B(Mediumは2B)と、大幅にパワーアップしてのリリースとなる。同時に蒸留版で高速生成可能なStable Diffusion 3.5 Large Turboもリリース。
加えて10月29日にはStable Diffusion 3.5 Medium(2.8B)も公開予定だ。今回はこの中からStable Diffusion 3.5 Largeで生成した画像中心にご紹介したい。
まずcheckpointは ここ にあるので、ダウンロードする。clip/t5/vaeはStable Diffusion 3もしくはFLUX.1 [dev]と共通となる。
確認した生成環境はComfyUI。公式が出しているWorkflowは以下の通り(bypassしているのはLoRA)。Forgeは元々Stable Diffusion 3に対応しているので動くかも知れないが、申し訳ない、未確認。
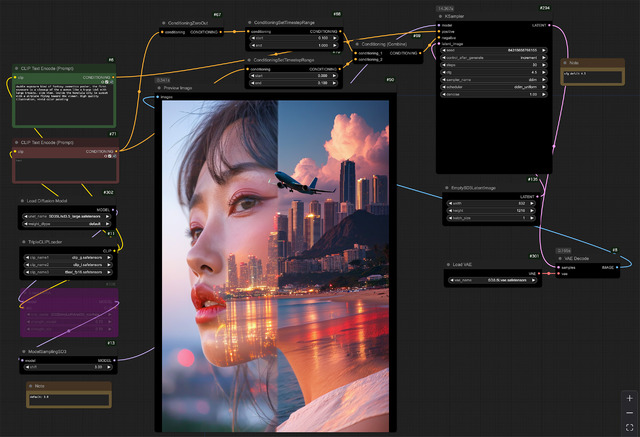
Workflowの中をザックリ見ると、checkpoint、clip/t5/vaeがバラバラのunet式だ。clipはclip_lとclip_g、そしてt5xxlの3つを使用。
Clip TextはNegativeも含め2つあり、Negative側はちょっと複雑な経路になっているが、ConditioningZeroOutがつながっているのでそもそも使えない。Promptのみの入力となる。
加えてcheckpointのMODELとKSamplerのmodelの間にModelSamplingSD3が3.0で入っている。
違いはこの程度で、KSamplerの設定は
steps: 40
cfg: 4.5
sampler: dpmpp_2m (eulerでも行ける)
scheduler: sgm_uniform
となる。この時点でお分かりだと思うがsteps 40は結構遅い(試した範囲だと30でも大丈夫)。またcfgが1より大きいので、1の時より倍の時間がかかる。
以降、掲載している画像は832×1,216、steps: 30、cfg: 4.5、sampler: eulerとしているものの、RTX 4090でも15秒ほどかかる。同じ環境でFLUX.1 [dev]が約8秒。ここはちょっと残念な部分だ。
まずありがちなパターンを4つ。文字出し、リアル系、イラスト系、リアル+イラスト混合系。ご覧の様に無難に生成できている。
指や体が崩れる問題は、随分良くなったものの、やはりあるにはある。ただFLUX.1 [dev]でもダメな時があるので、同レベルは仕方ないところだろう。
 |  |
 |  |
ここで気になるのは顔つき、肌の発色や質感。Stable Diffusion 3 Mediumとは随分違う。以前Stable Diffusion 3 Mediumのサンプルを掲載した以下の記事から1枚持ってきたのと(左)、

 |  |
Stable Diffusion 3.5 Largeを使い(ほぼ)同じPromptで生成した画像で比べるとこんな感じとなる。前者の方が自然と言えば自然。Stable Diffusion 3.5 Large (右)はいかにもAIっぽい顔/肌となる。
ただこれはPromptの書き方や西洋系か東洋系などでも随分変わるので、あくまでも参考程度として見て欲しい。
 |  |
この画像は全く同じ設定で、一つはwoman (左)、もう一つはjapanese woman (右)としての違いとなる。この手の感じだと然程AIっぽくない顔つきだ。
いずれにしても体が崩れる問題で、datasetの人の部分は大幅に入れ替えたと思われ、その影響が良い意味でも悪い意味でも出ているのだろう。
 |  |
 |  |
次の4枚はリアル系とイラスト系の融合やファンタジー系的な作例となる。扉やWorkflowにある二重露光も含め、この手の画風はStable Diffusion 3.5 Large得意かな!?と言った感じだ。
Stability AIのベースモデルはSD 1.5でもSDXLでもそうだった様に、学習したLoRAやcheckpointで大きく変わる。ベースモデルでここまで出来ているのだから、今後に期待したいところ。
今回締めのグラビア
今回の締めのグラビアはもちろんStable Diffusion 3.5 Largeを使い、10月末なので、前回に引き続きハロウィーンネタとなる。

何時もと違うのはUpscaleがうまく動かず、Photoshopで832×1,216を1,280×1,920(両サイド少しトリミング)へ拡大補完していること。
前回のFLUX.1 [dev]の絵柄と比較して、あまりカッチリ出ず、少しマイルドで色に透明感があるのが特徴と言ったところだろうか!?
次回はStable Diffusion 3.5 Large Turboと、きっと出ているであろうStable Diffusion 3.5 Mediumについて書く予定。お楽しみに!