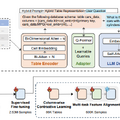


ソフトバンクグループの「SB Intuitions」が4000億パラメータ規模の日本語言語モデル「Sarashina2-8x70B」を公開し、日本語性能テストで最高性能を達成しました。
Anthropicは、高速処理が特徴の新しいAIモデル「Claude 3.5 Haiku」を発表しました。前世代の最上位モデルであるClaude 3 Opusを多くのベンチマークで上回りながら、Claude 3 Haikuと同等の処理速度を実現しています。
さて、この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第71回)では、1枚の画像から3D/4Dシーンを生成するAIモデル「DimensionX」や、テンセント開発の巨大オープンソース大規模言語モデル「Hunyuan-Large」を取り上げます。
また、PDFなどのドキュメントをデジタルデータに変換するAIツール「Docling」や、表形式データ特化で高性能に処理できるAIモデル「TableGPT2」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深い生成AI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、生成AIが科学的発見とイノベーションにどのような影響を与えるのかについて、研究者1000人以上に生成AIツールを使わせて、その効果を検証した研究を単体で掘り下げます。
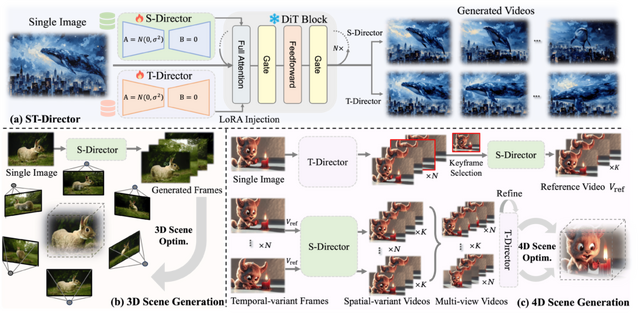
1枚の画像から動く3Dシーンを生成するAIモデル「DimensionX」
「DimensionX」は、単一の画像から写実的で制御可能な3次元および4次元シーンを生成する新しいフレームワークです。このアプローチは、3Dシーンの空間構造と4Dシーンの時間的な変化の両方が、ビデオフレームの連続によって表現できます。
近年のビデオ拡散モデルは鮮やかな映像生成で大きな成果を上げていますが、生成時の空間的・時間的な制御が限られているため、3D/4Dシーンを直接復元することには課題がありました。
これを解決するため、研究チームは「ST-Director」を提案しました。これは次元ごとに異なるデータからLoRAを学習することで、ビデオ拡散における空間的・時間的要素を切り離すものです。この制御可能なビデオ拡散手法により、空間構造と時間的な動きを正確に操作することができ、空間・時間次元を組み合わせてフレームから3Dおよび4D表現の両方を再構築できます。
また、生成されたビデオと実世界のシーンの違いを埋めるため、3D生成のための軌道認識の仕組みと4D生成のためのアイデンティティを保持するノイズ除去戦略を導入しました。実世界および合成データセットでの幅広い実験により、DimensionXは制御可能なビデオ生成に加えて、3Dおよび4Dシーン生成においても従来の手法を上回る結果を達成することが示されています。

DimensionX: Create Any 3D and 4D Scenes from a Single Image with Controllable Video Diffusion
Wenqiang Sun, Shuo Chen, Fangfu Liu, Zilong Chen, Yueqi Duan, Jun Zhang, Yikai Wang
Project | Paper | GitHub
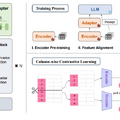
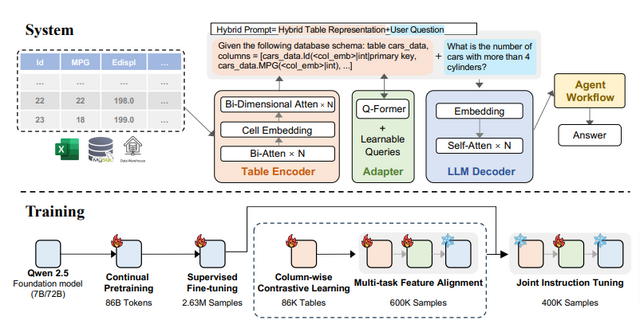
表形式データを高精度で処理できるAIモデル「TableGPT2」
大規模言語モデル(LLM)が様々な分野で活用されていますが、企業のデータ分析やビジネスインテリジェンス(BI)における表形式データの取り扱いには課題が残されています。この課題に対応するため、研究チームは「TableGPT2」を開発しました。
TableGPT2は、実世界の表形式データを高精度で処理できるAIモデルです。このモデルは、7Bパラメータと72Bパラメータの2つのバージョンが用意されており、Qwen2.5モデルファミリーをベースに開発されています。
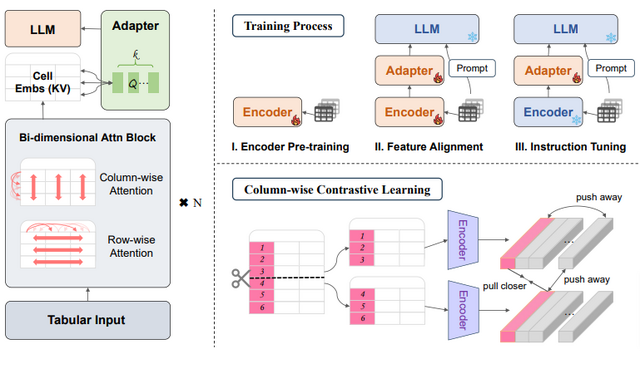
TableGPT2の特徴的な点は、表形式データに特化した独自のエンコーダーを採用していることです。このエンコーダーは、表の構造や内容を効率的に理解し、曖昧な質問や不完全なデータにも対応できるように設計されています。
また、訓練データとして59万以上のテーブルと236万件以上のクエリ・テーブル・出力のペアを使用しており、これは同様の研究分野では大規模です。
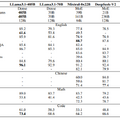
性能評価では、23の異なるベンチマーク指標を用いて既存のモデルと比較を行いました。その結果、7Bモデルで平均35.20%、72Bモデルで49.32%の性能向上を達成しています。
TableGPT2: A Large Multimodal Model with Tabular Data Integration
Aofeng Su, Aowen Wang, Chao Ye, Chen Zhou, Ga Zhang, Gang Chen, Guangcheng Zhu, Haobo Wang, Haokai Xu, Hao Chen, Haoze Li, Haoxuan Lan, Jiaming Tian, Jing Yuan, Junbo Zhao, Junlin Zhou, Kaizhe Shou, Liangyu Zha, Lin Long, Liyao Li, Pengzuo Wu, Qi Zhang, Qingyi Huang, Saisai Yang, Tao Zhang, Wentao Ye, Wufang Zhu, Xiaomeng Hu, Xijun Gu, Xinjie Sun, Xiang Li, Yuhang Yang, Zhiqing Xiao
Paper | GitHub | Hugging Face
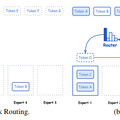
3890億パラメータのオープンソース大規模言語モデル「Hunyuan-Large」を中国テンセントが発表
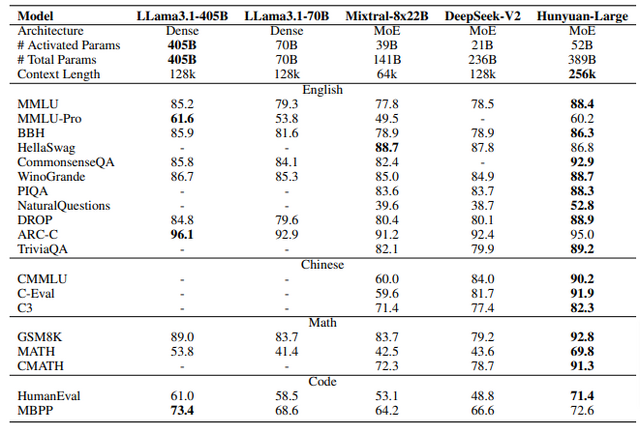
テンセントは、全パラメータ数3890億、活性化パラメータ数52億という「MoE」(Mixture of Experts)を活用したオープンソースモデル「Hunyuan-Large」を発表しました。モデルは一度に25万6000トークンまでの処理が可能です。
学習には合計7兆個のトークンを使用し、そのうち1.5兆個は生成した合成データです。合成データの質を確保するため、指示文の生成から回答の生成、品質フィルタリングなどの厳密なプロセスを経ています。
モデルの効率を高めるため、MoE構造において、すべてのトークンで共通して使用される1つの共有専門家と、特定分野に特化した16の専門家を組み合わせています。また、独自の圧縮技術により、メモリ使用量を従来の約5%まで削減することに成功しました。
性能評価では、英語と中国語の両方で印象的な結果を示しています。多面的な理解力を測るMMLUで88.4%、数学問題のGSM8Kで92.8%、プログラミングのHumanEvalで71.4%という高い正答率を達成しました。
これらの結果は、Llama3.1-405B、Mixtral-8x22B、DeepSeek-V2といった強力なオープンソースモデルを上回る性能を示しています。

Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Hunyuan Team
Paper | GitHub
PDF文書をデジタルデータに変えるオープンソースAI「Docling」をIBMが開発。ドキュメントをMarkdownやJSONに変換し、生成AIの学習用に
検索拡張生成(RAG)は、LLMが回答を生成する際に、外部の知識ベースから関連情報を検索して参照することで、より正確で最新の情報に基づいた応答を可能にする技術です。
近年、リアルタイム性や正確性の観点からRAGは重要になってきており、PDFなどに含まれる情報を正確に抽出する必要性も高まっています。
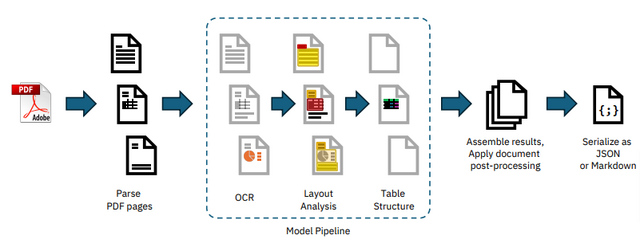
このような背景の中、IBM Researchは、ドキュメントを効率的に解析して再利用可能なデジタルデータに変換できるオープンソースなAIツール「Docling」を開発しました。
具体的な機能としては、PDF、DOCX、PPTX、Images、HTML、AsciiDoc、MarkdownなどのドキュメントをJSONやMarkdown形式に変換する基本機能に加えて、ページ内の要素を正確に認識し、適切な読み取り順序で情報を抽出できます。また、文書のタイトルや著者、参考文献といったメタデータの抽出や、スキャンされたPDFに対するOCR処理にも対応しています。
Doclingは、文書のレイアウトを分析するDocLayNetモデルや、表の構造を認識するTableFormerモデルなど、IBMが開発した最新のAI技術が組み込まれています。
処理性能については、Apple M3 Maxプロセッサを搭載したシステムで4スレッド使用時に225ページの処理に約177秒、Intel Xeon搭載システムで約375秒という結果が示されています。
Doclingの応用範囲は広く、企業における文書検索システムの構築や、学術論文のデータベース作成、さらには生成AI用の学習データセット作成まで、さまざまな用途に活用できます。開発チームは今後、図表の分類機能や数式の認識機能、プログラミングコードの認識機能などを追加する予定です。


Docling Technical Report
Christoph Auer, Maksym Lysak, Ahmed Nassar, Michele Dolfi, Nikolaos Livathinos, Panos Vagenas, Cesar Berrospi Ramis, Matteo Omenetti, Fabian Lindlbauer, Kasper Dinkla, Lokesh Mishra, Yusik Kim, Shubham Gupta, Rafael Teixeira de Lima, Valery Weber, Lucas Morin, Ingmar Meijer, Viktor Kuropiatnyk, Peter W. J. Staar
Paper | GitHub