




Googleはテキストや画像、動画など、複数の形式の情報を理解・処理できるマルチモーダル言語モデル「Gemini 2.0」を発表しました。開発者と一部のテスターに向けて公開され、すべてのGeminiユーザーには試験運用版の「Gemini 2.0 Flash」を利用できるようになります。Gemini 2.0 FlashはリアルタイムのAPIも公開されています。
またGoogleは、コードを生成するAIエージェント「Jules」も発表しました。これはPythonとJavaScriptのコーディングタスクを自動で処理し、GitHubと連携してバグ修正やプルリクエストまで行えます。

OpenAIは、動画生成AI「Sora」を公開しました。最大1080pで20秒の動画生成がテキストと画像からできます。
米スタンフォード大学の学生2人で設立したAIチーム「Pika」が、動画生成AI「Pika 2.0」を発表しました。複数枚の写真を入力すると、それらを調和させた一貫性のある映像を出力します。例えば、人と人だと、この2人が絡みあった映像に仕上げます。
さて、この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第75回)では、Microsoftの新しい言語モデル「Phi-4」や、カメラ越しに映る現実をリアルタイムに理解するAIモデル「IXC2.5-OL」を取り上げます。
また、複数視点からの同期した映像を生成できるAIモデル「SynCamMaster」と、ビデオ内の人が見ている視線を推定するモデル「Gaze-LLE」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、AIたちが「答えが分からない」と自身の無知を認識できるかを検証した研究を掘り下げています。

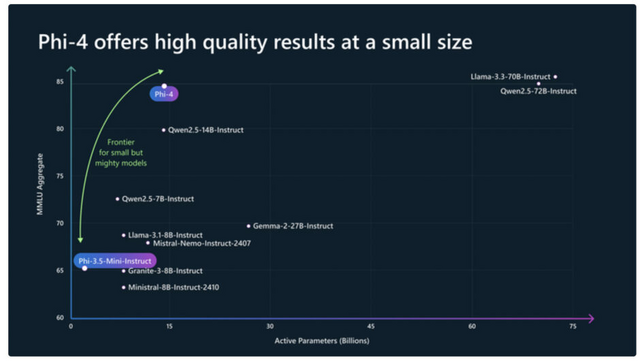
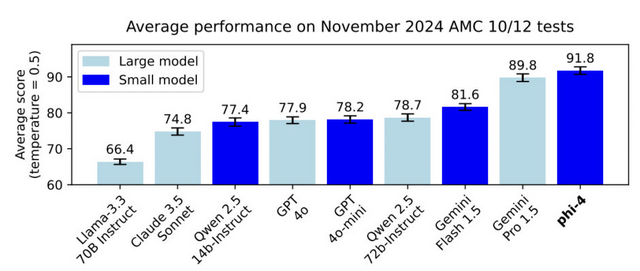
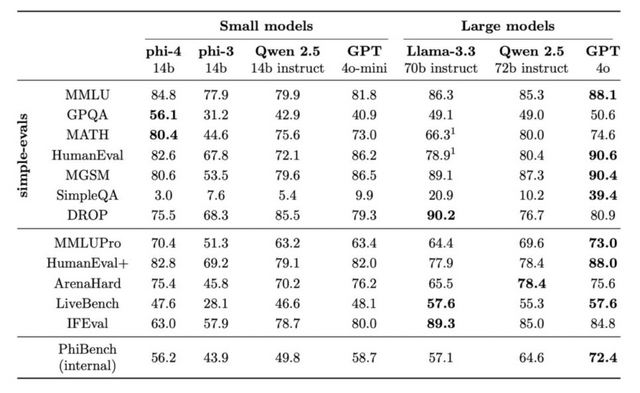
Microsoft、GPT-4oを上回る140億パラメータの小型言語モデル「Phi-4」発表
Microsoft Researchが140億パラメータの言語モデル「Phi-4」を発表しました。
Phi-4は、データ品質を重視して開発された軽量な言語モデルです。従来の言語モデルが主にWebコンテンツやコードなどの生のデータを用いて事前学習を行うのに対し、Phi-4は学習プロセス全体を通じて合成データを戦略的に活用しています。
実際の性能評価では、例えば、大学院レベルのSTEM(科学・技術・工学・数学)に関する質問応答や数学コンテストの問題では、教師モデルとして使用したGPT-4を上回る成績を達成しています。これは、単に大きなモデルの知識を真似ているだけではなく、独自の理解力を獲得していることを示唆しています。
また、プログラミングのテストでも優れた性能を発揮し、より大規模なLlamaモデルを含む他のオープンソースモデルを上回る結果を示しています。
モデルアーキテクチャ自体はPhi-3からほとんど変更されていませんが、改良されたデータ、トレーニングカリキュラム、そして学習後の調整手法により、そのサイズに比して優れた性能を達成しています。
Phi-4 Technical Report
Marah Abdin Jyoti Aneja Harkirat Behl S´ebastien Bubeck Ronen Eldan Suriya Gunasekar Michael Harrison Russell J. Hewett Mojan Javaheripi Piero Kauffmann James R. Lee Yin Tat Lee Yuanzhi Li Weishung Liu Caio C. T. Mendes Anh Nguyen Eric Price Gustavo de Rosa Olli Saarikivi Adil Salim Shital Shah Xin Wang Rachel Ward Yue Wu Dingli Yu Cyril Zhang Yi Zhang
Project | Paper | Blog | Hugging Face
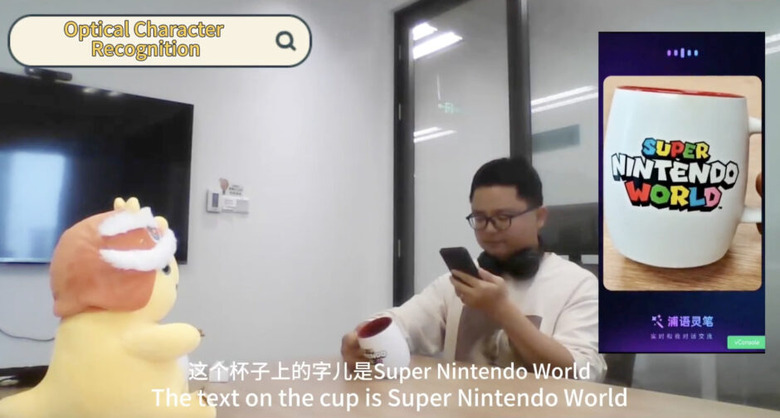
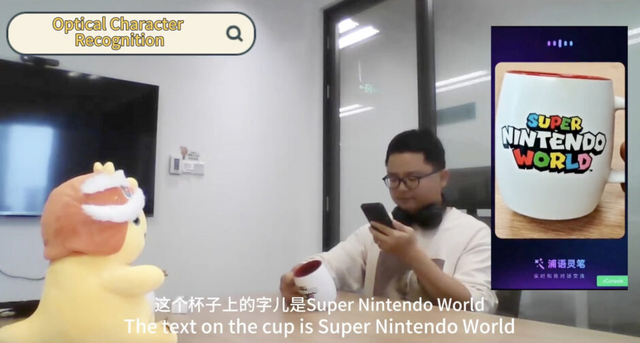
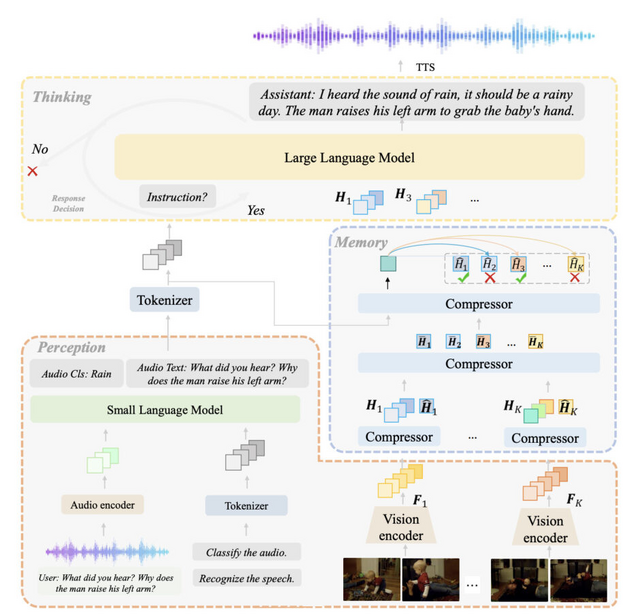
カメラ越しに映る現実をリアルタイムで理解するオープンソースAI「IXC2.5-OL」
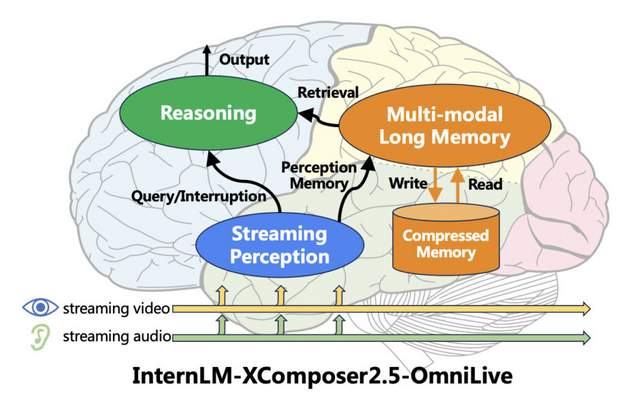
カメラ越しに映るストリーミングビデオをリアルタイムで理解できる新しいAIシステム「InternLM-XComposer2.5-OmniLive」(IXC2.5-OL)を開発しました。
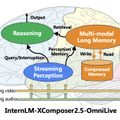
このシステムは3つの主要なモジュールで構成されています。1つ目は「ストリーミング認識モジュール」で、リアルタイムで映像や音声を処理し、重要な情報をメモリに保存します。
2つ目は「マルチモーダル長期メモリモジュール」で、短期記憶と長期記憶を統合し、より効率的な情報検索を可能にします。3つ目は「推論モジュール」で、ユーザーからの質問に対して記憶と認識の情報を組み合わせて回答を生成します。
IXC2.5-OLは、従来のAIシステムが抱えていた「認識と思考を同時に行えない」という制限を克服し、人間のように同時並行で処理できることを目指しています。
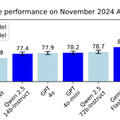
IXC2.5-OLは、長時間の映像理解においても優れた性能を発揮し、オープンソースモデルの中で最高水準の結果を達成しています。具体的な性能評価では、中国語音声認識のWenetspeech、英語音声認識のLibriSpeechといったベンチマークで競争力のある結果を示しました。また、映像理解のベンチマークMLVUでは66.2%、StreamingBenchでは73.79%という高いスコアを記録し、オープンソースモデルとしては最高性能を達成しています。
InternLM-XComposer2.5-OmniLive: A Comprehensive Multimodal System for Long-term Streaming Video and Audio Interactions
Pan Zhang, Xiaoyi Dong, Yuhang Cao, Yuhang Zang, Rui Qian, Xilin Wei, Lin Chen, Yifei Li, Junbo Niu, Shuangrui Ding, Qipeng Guo, Haodong Duan, Xin Chen, Han Lv, Zheng Nie, Min Zhang, Bin Wang, Wenwei Zhang, Xinyue Zhang, Jiaye Ge, Wei Li, Jingwen Li, Zhongying Tu, Conghui He, Xingcheng Zhang, Kai Chen, Yu Qiao, Dahua Lin, Jiaqi Wang
Paper | GitHub
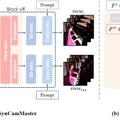
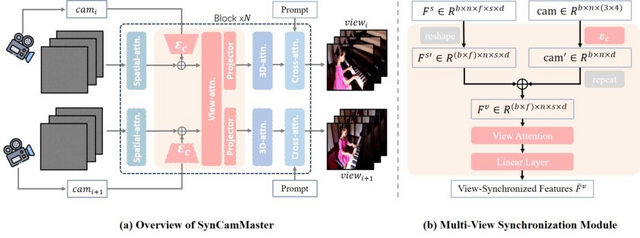
複数視点からの同期した映像を生成できるAIモデル「SynCamMaster」
これまでの動画生成AIは主に単一のカメラ視点からの生成に限られていましたが、「SynCamMaster」は複数のカメラ視点から同期した動画を生成できるモデルです。同じシーンを異なる角度から撮影したような複数の動画を一度に生成できます。
SynCamMasterは、事前学習された動画生成モデルをベースに、複数視点間の一貫性を保つための新しいモジュールを導入しています。具体的には、カメラの位置や角度などの外部パラメータをエンコードし、各視点間の特徴量に注意を向けるマルチビュー同期モジュールを実装しています。
データセットの不足という課題に対しては、Unreal Engineでレンダリングした複数視点の動画、一般的な単視点動画、複数視点の画像を組み合わせたハイブリッドな学習方式を採用しています。
実験では、SynCamMasterが異なる視点から一貫したコンテンツを生成し、視点間の優れた同期を実現できることが示されました。また、既存の動画に対して新しい視点からの動画を生成する機能も実装されています。

SynCamMaster: Synchronizing Multi-Camera Video Generation from Diverse Viewpoints
Jianhong Bai, Menghan Xia, Xintao Wang, Ziyang Yuan, Xiao Fu, Zuozhu Liu, Haoji Hu, Pengfei Wan, Di Zhang
Project | Paper | GitHub
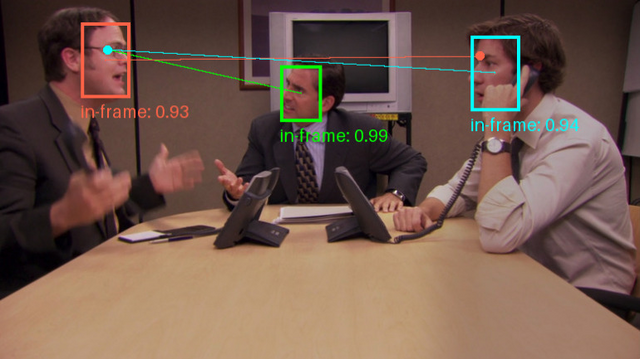
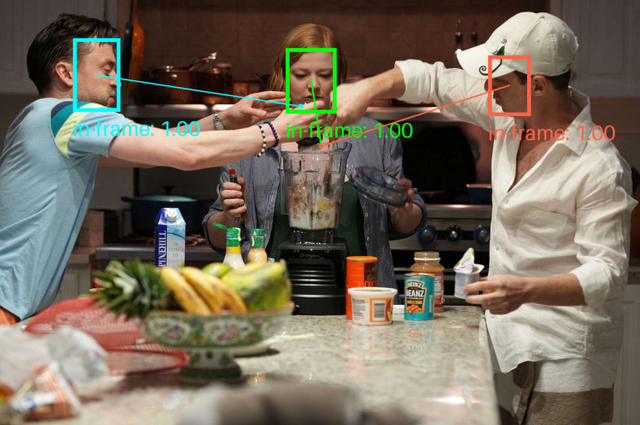
動画内にいる人の視線を推定する手法「Gaze-LLE」は複数人同時も可能
研究チームは、視線推定に関する新たな手法「Gaze-LLE」を発表しました。この手法は、映像内にいる人物の頭部位置から、その人物が見ている対象物を予測するものです。動画内の複数人を同時に視線推定することも可能です。
従来の視線推定手法では、頭部画像や全体シーン、深度、姿勢など複数の情報を組み合わせる複雑な処理が必要でした。一方、Gaze-LLEは事前学習済みの視覚特徴抽出器「DINOv2」を使用し、軽量なデコーダーモジュールと組み合わせることで、より効率的に視線推定を実現することに成功しました。
研究チームは複数のベンチマークデータセットでGaze-LLEを評価し、最先端の性能を達成。特にGazeFollowデータセットでは、従来手法と比べて約95%少ないパラメータ数でありながら、より高い精度を示しました。
さらに、Gaze-LLEは事前学習済みモデルを活用することで、異なるデータセットへの適用も容易になっています。小売店内での視線推定や子供の視線行動の分析など、様々な応用シーンでの有効性が確認されました。

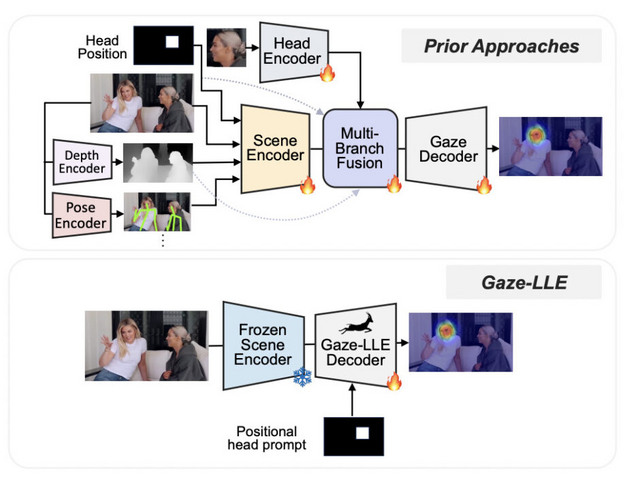
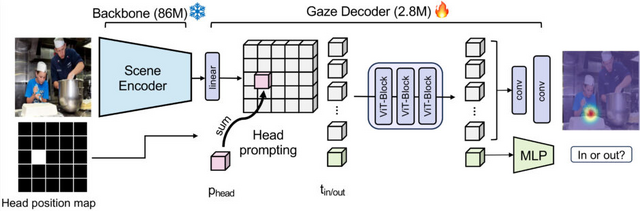
Gaze-LLE: Gaze Target Estimation via Large-Scale Learned Encoders
Fiona Ryan, Ajay Bati, Sangmin Lee, Daniel Bolya, Judy Hoffman, James M. Rehg
Paper | GitHub