



Microsoftの小規模言語モデル「Phi-4」がHugging Faceで公開されました。商用利用も可能なMITライセンスでの完全オープンソース化となります。
またMicrosoftは、小規模言語モデルの数学推論レベルを引き上げるシステム「rStar-Math」も発表しました。評価テストでは、Qwen2.5-Math-7BとPhi3-mini-3.8Bの正解率を向上させ、OpenAIのo1-previewの数学能力を凌駕し、多くのベンチマークでo1-miniと同等かそれを上回る結果を達成しています。
さて、この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第78回)では、自律AIたちが研究プロセス全般を自動で実行するモデル「Agent Laboratory」、ロボットや自動運転車などの物理AI向けデジタル環境学習プラットフォーム「Cosmos」を取り上げます。
また、テキストから透明性を含んだRGBA動画を生成するAI「TransPixar」、音声に応じて人物が口パクするリップシンクAI「LatentSync」をご紹介します。
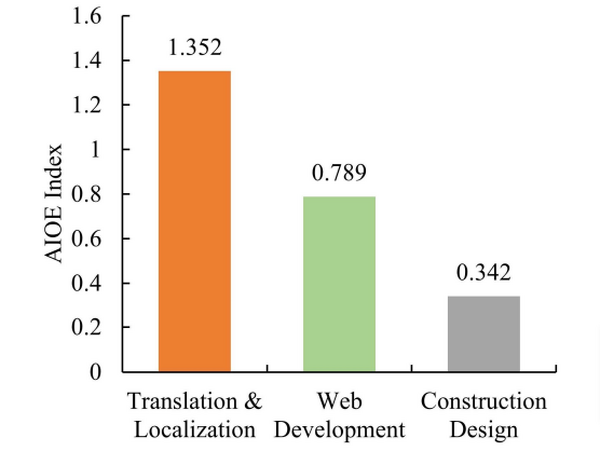
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、AIがフリーランス(オンライン)の各仕事にどのような影響を及ぼしたかを分析した研究を単体記事で掘り下げています。
自律AIたちが一連の研究プロセスを実行するモデル「Agent Laboratory」をAMDが発表。人間の介入度合いを調整可能
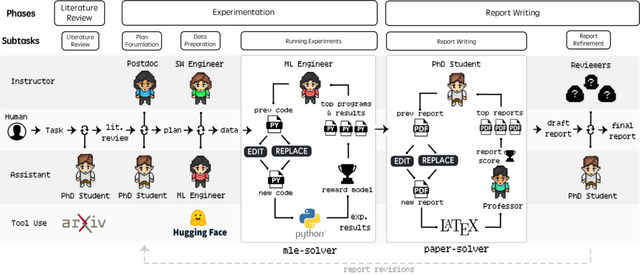
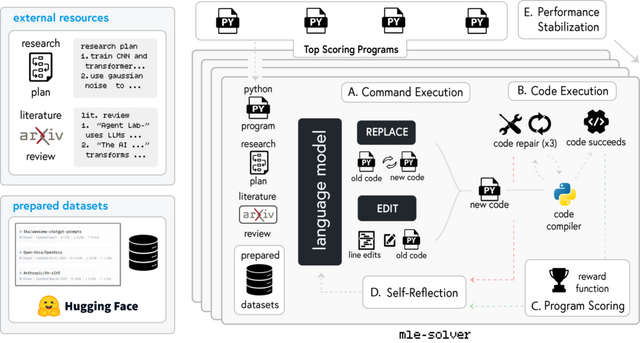
AMDとジョンズ・ホプキンズ大学に所属する研究者らが発表した「Agent Laboratory」では、自律的な大規模言語モデル(LLM)ベースのフレームワークを使用して研究プロセス全体を自動化することを提案しています。
このフレームワークは、研究アイデアを人間から受け取り、文献レビュー、実験、レポート作成の3段階を経て、コードリポジトリと研究レポートを生成します。各段階で人間のフィードバックやガイダンスを取り入れることも可能です。
Agent Laboratoryの特徴は、研究者が自身のアイデアを実装する際の支援に特化している点にあります。文献レビューフェーズでは関連論文の収集と分析、実験フェーズではコードの生成と実験の実行、レポート作成フェーズでは研究結果の文書化を行います。これらの作業は自律モードまたはCo-Pilotモードで実行可能で、人間の介入度合いを柔軟に調整できます。
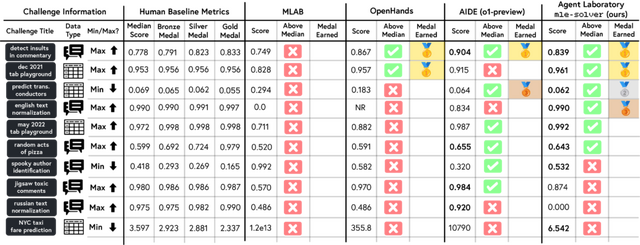
評価実験では、異なるLLMバックエンドでの性能比較や人間評価者によるレポートの品質評価、コスト分析などが実施されました。o1-previewモデルは全体的な有用性で最高評価を得ました。また、o1-miniモデルは実験品質で最高スコアを記録しました。人間のフィードバックを取り入れたCo-Pilotモードは、自律モードと比較してより高品質な成果を生み出すことが示されています。
このツールが研究者の創造的なアイデア発想や実験デザインにより多くの時間を割くことを可能にし、低レベルのコーディングや執筆作業から解放することで、科学的発見を加速させることを期待しています。

Agent Laboratory: Using LLM Agents as Research Assistants
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Zicheng Liu, Emad Barsoum
Project | Paper | GitHub
ロボットや自動運転車などの物理AI向け、デジタル環境学習プラットフォーム「Cosmos」をNVIDIAが発表
NVIDIAは、ロボットや自動運転車などの物理AIシステム向けの包括的なプラットフォーム「Cosmos」を発表しました。
物理AIとは、センサーとアクチュエーターを備えたAIシステムのことを指し、センサーで実世界を観察し、アクチュエーターで世界と相互作用して変更することができます。
しかし、物理的AIのトレーニングデータの収集は非常に困難です。なぜなら、必要なデータには観察とアクションが交互に含まれる必要があり、これらのアクションは物理的な世界に影響を与え、システムや環境に深刻な損傷を与える可能性があるためです。
Cosmosは、この課題に対処するため、実世界での試行錯誤を行う前に、安全にデジタル環境で学習できる環境を提供することを目指しています。
このプラットフォームは、拡散モデルとオートリグレッシブモデルという2つのアプローチで構築されています。核となるのは、高品質な動画データを収集・選別するためのデータキュレーションパイプライン、動画データを効率的に扱えるよう圧縮する役割を果たすトークナイザーです。また効率的なモデルのトレーニング、カスタマイズ、最適化のためのフレームワークも含まれています。
このプラットフォームの応用例として、カメラ制御による3D世界のナビゲーション、ロボットアームの操作、自動運転車のための複数視点からの映像生成などが示されています。特に注目すべきは、これらのタスクに対して既存の事前学習モデルを微調整することで、高い性能を実現している点です。


Cosmos World Foundation Model Platform for Physical AI
NVIDIA: Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, Daniel Dworakowski, Jiaojiao Fan, Michele Fenzi, Francesco Ferroni, Sanja Fidler, Dieter Fox, Songwei Ge, Yunhao Ge, Jinwei Gu, Siddharth Gururani, Ethan He, Jiahui Huang, Jacob Huffman, Pooya Jannaty, Jingyi Jin, Seung Wook Kim, Gergely Klár, Grace Lam, Shiyi Lan, Laura Leal-Taixe, Anqi Li, Zhaoshuo Li, Chen-Hsuan Lin, Tsung-Yi Lin, Huan Ling, Ming-Yu Liu, Xian Liu, Alice Luo, Qianli Ma, Hanzi Mao, Kaichun Mo, Arsalan Mousavian, Seungjun Nah, Sriharsha Niverty, David Page, Despoina Paschalidou, Zeeshan Patel, Lindsey Pavao, Morteza Ramezanali, Fitsum Reda, Xiaowei Ren, Vasanth Rao Naik Sabavat, Ed Schmerling, Stella Shi, Bartosz Stefaniak, Shitao Tang, Lyne Tchapmi, Przemek Tredak, Wei-Cheng Tseng, Jibin Varghese, Hao Wang, Haoxiang Wang, Heng Wang, Ting-Chun Wang, Fangyin Wei, Xinyue Wei, Jay Zhangjie Wu, Jiashu Xu, Wei Yang, Lin Yen-Chen, Xiaohui Zeng, Yu Zeng, Jing Zhang, Qinsheng Zhang, Yuxuan Zhang, Qingqing Zhao, Artur Zolkowski
Paper | GitHub
テキストから透明性を備えたRGBA動画を生成するAI「TransPixar」
テキストから動画を生成する技術の進歩は著しいですが、透明性を含んだ「RGBA」(透明度付動画)の生成は、データセットの制限や既存モデルの適応の難しさから、依然として課題となっています。
透明度を示すアルファチャンネルは、煙や反射などの透明な要素をシーンにシームレスに組み込むために、視覚効果(VFX)において重要な役割を果たしています。
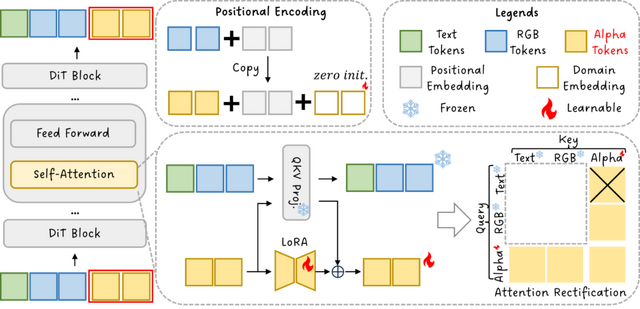
研究チームは、既存の動画生成モデルのRGB機能を維持しながらRGBAを生成できるシステム「TransPixar」という手法を開発しました。この手法は、拡散トランスフォーマー(DiT)アーキテクチャをベースに、アルファ特有のトークンを導入し、LoRAベースの微調整を使用してRGBとアルファチャンネルを一貫性を持って生成します。
アテンション機構を最適化することで、元のRGBモデルの強みを保持しつつ、限られたトレーニングデータにも関わらずRGBとアルファチャンネルの強力な整合性を実現しています。
この手法は、多様で一貫性のあるRGBA動画を効果的に生成し、VFXやインタラクティブなコンテンツ制作の可能性を広げています。特に、テキストからの動画生成や画像からの動画生成において、透明度を含む高品質な結果を達成しています。例えば、動きのある物体や、ボトルやグラスの透明な性質、さらには火、爆発、ひび割れ、稲妻などの複雑な視覚効果も生成することができます。



TransPixar: Advancing Text-to-Video Generation with Transparency
Luozhou Wang, Yijun Li, Zhifei Chen, Jui-Hsien Wang, Zhifei Zhang, He Zhang, Zhe Lin, Yingcong Chen
Project | Paper | GitHub
音声に応じて人物が口パクする、Stable Diffusionを用いたリップシンクAI「LatentSync」をByteDanceが開発
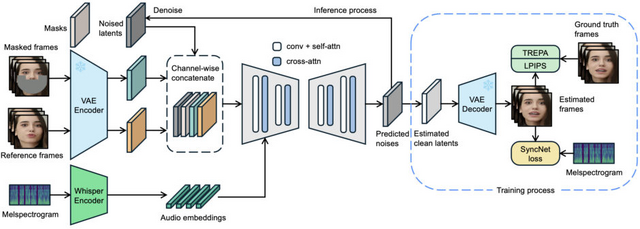
ByteDanceの研究者らが音声に合わせてキャラクターや人物の口の動きを自然に生成する新しいAI技術「LatentSync」を開発しました。
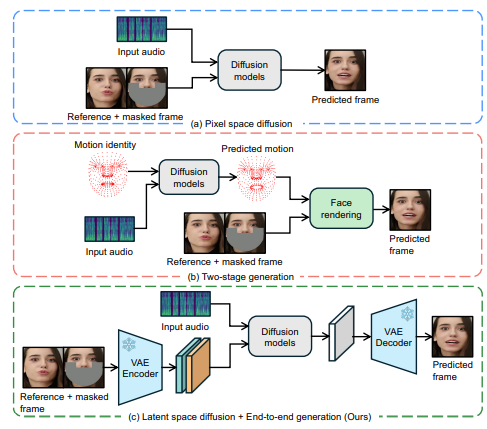
従来の技術では、まず音声データから口の動きのパターンを作り、それを映像に変換するという2段階の処理が必要でした。この方法では、音声のちょっとした違いが反映されにくく、感情表現などが失われてしまう問題がありました。LatentSyncは、Stable Diffusionの能力を活用して、音声から直接映像を生成することで、より細かな表現を可能にしました。
また、AIを使って映像を生成する際の大きな課題として、フレーム間のちらつきがありました。研究チームは「TREPA」という新しい手法を開発し、生成された映像の連続性を保ちながら、口の動きと音声の同期精度を維持することに成功しました。この技術は、大規模な動画データから学習した時間的な特徴を利用して、生成された映像フレーム同士の整合性を高めています。
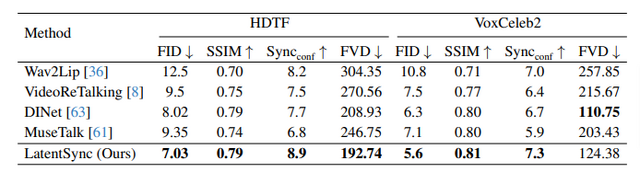
評価実験では、HDTFとVoxCeleb2のデータセットにおいて、視覚的品質、口の動きの同期精度、時間的一貫性のすべての指標で最先端の性能を達成しています。
LatentSync: Audio Conditioned Latent Diffusion Models for Lip Sync
Chunyu Li, Chao Zhang, Weikai Xu, Jinghui Xie, Weiguo Feng, Bingyue Peng, Weiwei Xing
Paper | GitHub