









生成AIグラビアをグラビアカメラマンが作るとどうなる? 連載記事一覧
FLUX高速化その1 - FLUX.1-Turbo-Alpha
生成AI画像で一番気になるのは生成時間。SD 1.5/SDXLはRTX 30系/40系を使えば比較的速いものの、FLUX.1 [dev] になって随分時間がかかるようになってしまった。
もちろんFLUX.1以前でもLCMなど高速化する技術はいろいろあったが、ありと無しでは出てくる絵のテイストも随分変わってしまい、結局実践では使わないことが多かったように思う。
同様にFLUX.1でもHyperやTurboなどいろいろ呼び方があり統一されていないものの、LoRAを使って高速化する技術がある。いくつかある中、筆者お気に入りが FLUX.1-Turbo-Alpha 。単純にLoRAとしてstrength 1.0でセットすればOK。step数は8。
生成時間はstep数に比例するため半分程度の時間で生成可能になる。以下、Promptなどstep数以外は同一設定で比較してみたい。
 |  |
LoRA無し 20 steps / 34.35秒
LoRAあり 8 steps / 14.89秒
使ったのは RTX 4060 Ti(16GB)。先日RTX 50系が発表されたので今後価格はどうなるか分からないが、今のところ16GB搭載としては最安値で7万円を切る。
かかった時間は 34.35秒 vs 14.89秒。LoRAありの方が圧倒的に速くなってる。またLCM方式のように絵が大雑把になる感じも無い。欠点としてはご覧のように20 stepsとは全く構図が異なること。
とは言え、20 stepsを生成しなければ構図の違いは気にならず、特に劣化した感じも無いので筆者が好んで使っているスピードアップLoRAだ。Xにアップロードしている画像のほとんどは(FLUXの場合)、このLoRAを使用している。
FLUX高速化その2 - Comfy-WaveSpeedとComfyUI-TeaCache
上記のLoRAは生成時のstep数を減らしての高速化だが、最近、step数は同じのまま高速化する Comfy-WaveSpeed と ComfyUI-TeaCache が登場した。
どの様な仕掛けで高速化しているか?は不明だが、どちらもNode 1つ使うパターン、2つ使うパターンと2種類あり、うまく動くケースだと2つ使う方がより高速になる。
ComfyUIへの組み込み方は簡単で custom_nodes に移動し以下のURLで git clone すればOK。
https://github.com/chengzeyi/Comfy-WaveSpeed
https://github.com/welltop-cn/ComfyUI-TeaCache
Workflow的にはLoad CheckpointのMODELと、KSamplerのmodelの間に入れるだけと簡単だ。実際のWorkflowを掲載するので参考にしてほしい。
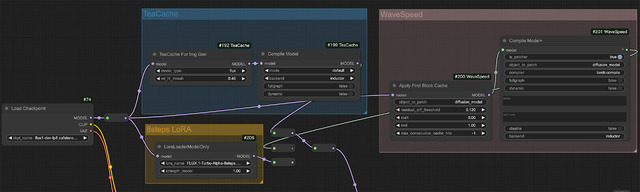
背景緑がTeaCache、赤がWaveSpeed、黄色が先に書いた8steps LoRA。どれも左側にあるLoad CheckpointのMODELからそれぞれのmodelに入り、どれか一つを選んで(中央紫の線の先にある)KSamplerに渡せるよう、rerouteしてある。
Nodeを1つ使う場合は左側Nodeのみ(右側はBypass)、2つ使う場合はどちらもONの状態にしておく。但し右側のCompileを使った時は、初めの1回目だけCompileする時間がかかる。
以下、無しとあり、それぞれの比較だ。
|  |
|  |
無し
WaveSpeed
無し
TeaCache
いかがだろうか? 全く同じではないが少し違う程度に収まっている。WaveSpeedは顔が丸くなる、TeaCacheは背景が変わる……といった感じだろうか。
832x1216 / 20 stepsの生成時間(単位: 秒)をまとめてみた。
RTX 4060 Ti(16GB) | RTX 3090(24GB) | RTX 4090(24GB) | |
無し | 34.16 | 25.31 | 7.66 |
Comfy-WaveSpeed | 23.08 | 20.78 | 4.79 |
Comfy-WaveSpeed (+Compile) | 16.46 | error | 3.31 |
ComfyUI-TeaCache | 19.61 | 17.78 | 4.39 |
ComfyUI-TeaCache (+Compile) | 14.06 | error | 3.01 |
注目ポイントとしてはRTX 3090(24GB)ではどちらも+Compileがエラーで動かず、結果、RTX 4060 Ti(16GB)に負けてしまうこと。無しの状態では10秒近く差があるのに、ソフトウェアの力はハードウェア性能より効くということなのだろう。また全般的にTeaCacheの方がスコアが良い。
いずれにしても無しとありの差は最大約2倍。RTX 4070 Ti(16GB)では先の8 steps LoRAよりも速い。加えてRTX 4090(24GB)の3秒は驚異的だ。NVIDIAの発表によるとRTX 5090(32GB)はRTX 4090(24GB)の約2倍速い(FLUX.1 [dev] 画像生成時)とされているので、その速度を先取りした形になる。そしてRTX 5090(32GB)に買い換えると…1.5秒!(笑)。
▲一番右がFLUX.1 [dev] の比較
Windows環境でのtritonとtorch.compile
ここまでサラッと書いているが実はWindows環境で+Compileを動かすには結構ハードルが高い。と言うのもWindowsではtriton及びtorch.compileは(正式には)未対応なのだ。
従ってmake済みのWindows用tritonを探してpip installしたり、torch.compileを動かすため、Visual StudioやCUDA Toolkitをインストールしなければならない。以下やったことのメモ書きとなる(CUDA Toolkitは事前にインストール済み)。
Windows版triton
https://github.com/woct0rdho/triton-windows/releases/tag/v3.1.0-windows.post5
python_embeded/python.exe -m pip install https://github.com/woct0rdho/triton-windows/releases/download/v3.1.0-windows.post5/triton-3.1.0-cp311-cp311-win_amd64.whl
※ cp311-cp311。この部分がpythonのversionに相当する。cp311だとpython 3.11.x
ComfyUI Windows Portable対応
https://github.com/woct0rdho/triton-windows/releases/download/v3.0.0-windows.post1/python_3.11.9_include_libs.zip
※ python_embededへ解凍したlibsとincludeをコピー
※ 参照: https://github.com/woct0rdho/triton-windows/issues/30
Visual Studio Community 2022
https://visualstudio.microsoft.com/ja/vs/features/cplusplus/
※ [C++ の Visual Studio]をダウンロード / Community 2022
これでRTX 4070 T(16GB)は動いたが、全く同じことをしているにもかかわらず RTX 3090(24GB)では動かなかった。RTX 4090(24GB)はOSがUbuntuなので何もせずにOK。Windows環境でのAI関連はいろいろ鬼門があり、できればUbuntuに逃げたいところ。
今回締めのグラビア
今回締めのグラビアは、解説したどれかにからめても単にFLUX.1 [dev] の絵なので面白さに欠ける。そこでFLUX.1 [schnell] のcheckpointを使い、扉とグラビアを掲載、巳年なので軽く蛇も入れてある(笑)。
FLUX.1 [schnell] は4 stepsで生成可能なので速度的にはかなり速い。にも関わらずあまり使われていないのは絵がイマイチだから。特に実写/ポートレート系だと肌色が土色、構図も中途半端…と正直見るに耐えないものが出てくることが多い。
ところが少し前に公開された schnellMODE を使うとご覧の通り。かかる時間もRTX 4060 Ti (16GB)でたった5.73秒と爆速だ。

使い方のコツとしては、LoRA無しでもそこそこ綺麗な絵が出るのだが、肌色の発色がいいLoRAを軽く当てる(0.2~0.4)といい感じに仕上がるのでお試しあれ!




