






この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第79回)では、自分の動きに応じてキャラクターの顔をリアルタイムに動かせる動画生成AI「RAIN」、400万トークンを処理できる大規模言語モデル「MiniMax-01」を取り上げます。
また、タスクに応じて自らの設定を“動的”に調整できる自己適応型AIモデル「Transformer²」、手書きスケッチや領域ドラッグなどで直感的に画像編集できるAI「FramePainter」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、世界初のAIチャットボット「ELIZA」(イライザ)が60年ぶりに復活した研究を単体記事で掘り下げています。

400万トークンを処理できる大規模言語モデル「MiniMax-01」
中国企業「MiniMax」は、新しいAIモデルシリーズ「MiniMax-01」を発表し、オープンソース化しました。このシリーズには、基盤言語モデルの「MiniMax-Text-01」とビジョンマルチモーダルモデルの「MiniMax-VL-01」が含まれています。
このモデルシリーズの最大の特徴は、従来のTransformerアーキテクチャとは異なる、新しい「Lightning Attention」メカニズムを大規模に実装したことです。
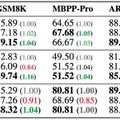
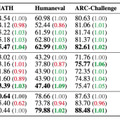
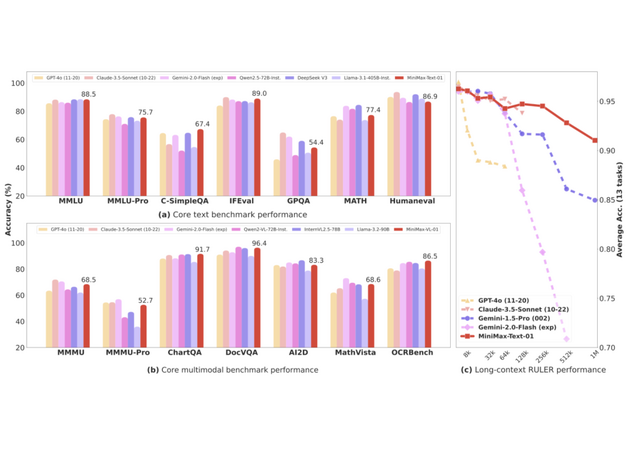
モデル全体で4560億という膨大なパラメータを持ち、実際の処理時には459億のパラメータが活性化される仕組みとなっています。特筆すべきは、GPT-4やClaude-3.5-Sonnetに匹敵する性能を示しながら、他の主要なAIモデルの20~32倍となる400万トークンという最長のコンテキスト長を効率的に処理できることです。これは、長い文章や複雑な情報を一度に理解し処理できる能力が大幅に向上したことを意味します。
価格面では、入力テキスト100万トークンあたり0.2ドル、出力テキスト100万トークンあたり1.1ドルという標準価格を提供します。これらのサービスはMiniMax Open Platformを通じて、企業から個人まで誰でも利用できます。

MiniMax-01: Scaling Foundation Models with Lightning Attention
MiniMax, Aonian Li, Bangwei Gong, Bo Yang, Boji Shan, Chang Liu, Cheng Zhu, Chunhao Zhang, Congchao Guo, Da Chen, Dong Li, Enwei Jiao, Gengxin Li, Guojun Zhang, Haohai Sun, Houze Dong, Jiadai Zhu, Jiaqi Zhuang, Jiayuan Song, Jin Zhu, Jingtao Han, Jingyang Li, Junbin Xie, Junhao Xu, Junjie Yan, Kaishun Zhang, Kecheng Xiao, Kexi Kang, Le Han, Leyang Wang, Lianfei Yu, Liheng Feng, Lin Zheng, Linbo Chai, Long Xing, Meizhi Ju, Mingyuan Chi, Mozhi Zhang, Peikai Huang, Pengcheng Niu, Pengfei Li, Pengyu Zhao, Qi Yang, Qidi Xu, Qiexiang Wang, Qin Wang, Qiuhui Li, Ruitao Leng, Shengmin Shi, Shuqi Yu, Sichen Li, Songquan Zhu, Tao Huang, Tianrun Liang, Weigao Sun, Weixuan Sun, Weiyu Cheng, Wenkai Li, Xiangjun Song, Xiao Su, Xiaodong Han, Xinjie Zhang, Xinzhu Hou, Xu Min, Xun Zou, Xuyang Shen, Yan Gong, Yingjie Zhu, Yipeng Zhou, Yiran Zhong, Yongyi Hu, Yuanxiang Fan, Yue Yu, Yufeng Yang, Yuhao Li, Yunan Huang, Yunji Li, Yunpeng Huang, Yunzhi Xu, Yuxin Mao, Zehan Li, Zekang Li, Zewei Tao, Zewen Ying, Zhaoyang Cong, Zhen Qin, Zhenhua Fan, Zhihang Yu, Zhuo Jiang, Zijia Wu
Paper | GitHub | Blog
タスクに応じて自らの設定を“動的”に調整できる自己適応型AIモデル「Transformer²」をSakana AIなどが開発
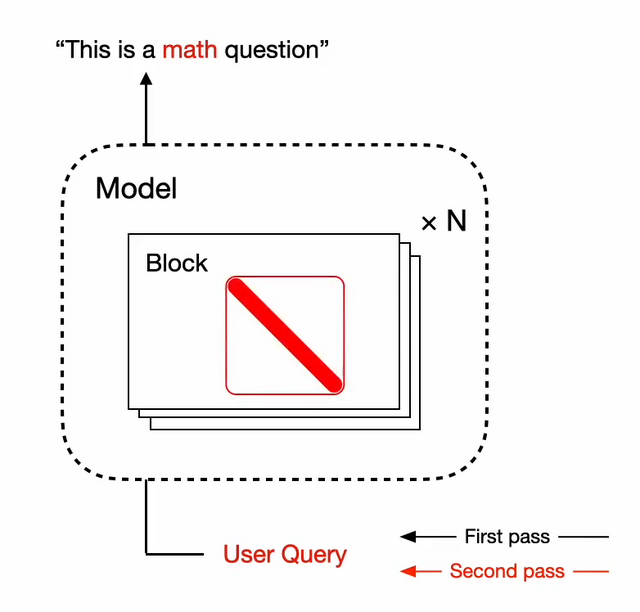
Transformer²は、与えられたタスクに応じて自らの設定を動的に調整できる自己適応型AIモデルです。これは、従来の微調整手法が計算コストが高く、多様なタスクへの対応が静的であるという課題を解決することを目指しています。
Transformer²という名称は、入力されたタスクの要件を分析し、その後タスク固有の適応を適用して最適な結果を生成するという2段階のプロセスを反映しています。
中核となる技術は、大規模言語モデルの重み行列を特異値分解(SVD)によって分析し、各タスクに最適な形に調整することです。訓練時にはSVFという手法を導入し、強化学習を用いて様々な種類のタスクに対して構成要素の信号を強化または抑制する方法を学習させます。
推論時には、タスクの種類を検出し、モデルの重みを適切に調整するために3つの異なる戦略を採用しています。具体的には、プロンプトベースの適応、分類器ベースの適応、少数ショット適応という方法を用いています。
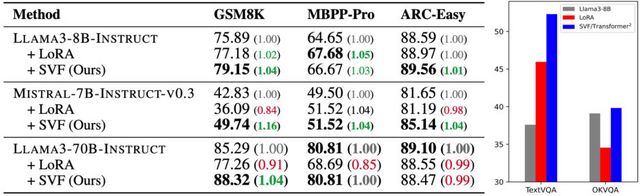
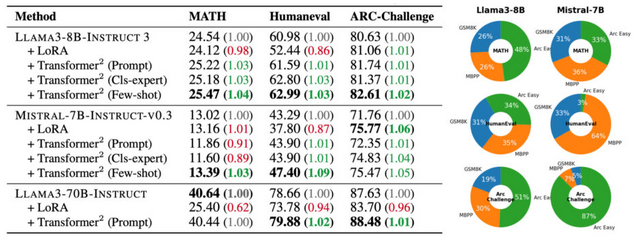
この手法により、従来のLoRAなどの手法と比較して、必要なパラメータ数を大幅に削減しながら、同等以上の性能を達成することができます。研究チームは、LlamaとMistralという2つの大規模言語モデルでTransformer²を検証し、数学、プログラミング、論理的思考などの課題で性能向上を確認しました。

自分の動きに応じてキャラクターの顔をリアルタイムに動かせる動画生成AI「RAIN」
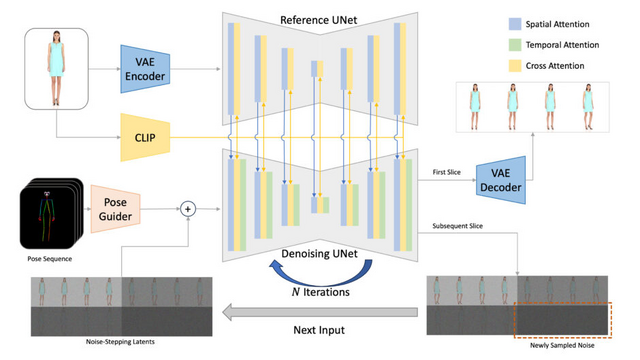
従来の拡散モデルを使用したアニメーション生成では、数秒の映像を生成するのに数分かかり、実用的なライブアニメーションには適していませんでした。「RAIN」は、単一のRTX 4090 GPUを使用して、リアルタイムで無限の長さの動画ストリームを低遅延で生成することができます。
RAINの核となる技術は、異なるノイズレベルと長時間の間隔にわたってフレームトークンの注意を効率的に計算し、同時に従来のストリームベースの手法よりも大幅に多くのフレームトークンを処理することです。これにより、より短い遅延とより高速な生成速度を実現しながら、長時間のビデオストリームに対する一貫性と連続性を向上させています。
その結果、RAINで数エポックだけファインチューニングされたStable Diffusionモデルは、品質や一貫性をあまり損なうことなく、無限に長いビデオストリームをリアルタイムかつ低遅延で生成することができます。
実験では、キャラクターのリアルタイムアニメーション、クロスドメイン顔変形、スタイル変換など、様々なタスクでの有効性が示されました。特に、単一のRTX 4090 GPUで512×512の解像度の動画を18FPSで生成できることが確認されています。



RAIN: Real-time Animation of Infinite Video Stream
Zhilei Shu, Ruili Feng, Yang Cao, Zheng-Jun Zha
Project | Paper | GitHub
手書きスケッチや領域ドラッグなどで直感的に画像編集できるAIモデル「FramePainter」
「FramePainter」は、ユーザーがスケッチを描いたり、点をクリックしたり、領域をドラッグしたりするような直感的な操作で画像を編集できるシステムです。従来の手法とは異なり、画像編集を画像から動画を生成する問題として捉え直すことで、ビデオ拡散モデルの持つ強力な事前知識を活用することができます。
このアプローチの特徴は、Stable Video Diffusionをベースに、編集信号を注入するための軽量な制御エンコーダーを組み合わせている点です。また、2つのフレーム間の大きな動きを扱うために、編集された画像と元画像のトークン間の密な対応関係を促進する「マッチング注意機構」を導入しています。
実験では、高品質な動画から数千組の画像ペアを構築して評価を行いました。その結果、FramePainterは既存の最先端手法と比較して、はるかに少ない学習データでありながら、優れた編集性能を示しました。例えば、コップの反射を自動的に調整したり、クマノミをサメのような形に変形したりするような、現実世界の動画には存在しないシナリオでも優れた汎化性能を発揮しています。

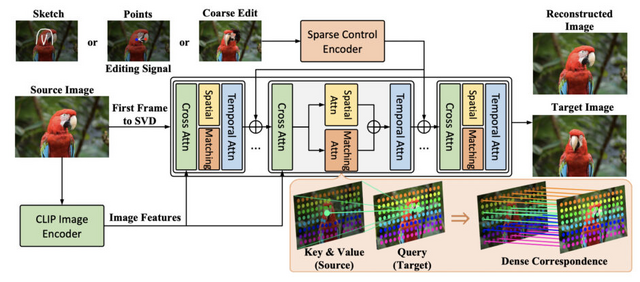

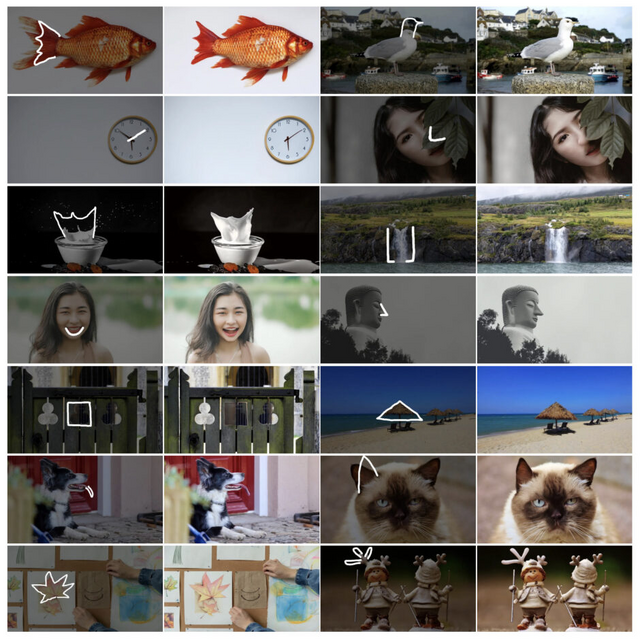
FramePainter: Endowing Interactive Image Editing with Video Diffusion Priors
Yabo Zhang, Xinpeng Zhou, Yihan Zeng, Hang Xu, Hui Li, Wangmeng Zuo
Paper | GitHub














![【DL版】【初期費用3,300円が無料 ※1契約者1回線/年に限り】IIJmioえらべるSIMカード エントリーパッケージ 月額利用(音声SIM/SMS)[ドコモ・au回線]・(データ/eSIM/プリペイド)[ドコモ回線]IM-B327 image](https://m.media-amazon.com/images/I/51Q3vrxdLFL._SL160_.jpg)







