




この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第91回)では、複数の写真に写る被写体を1枚の写真に統合させる画像生成AI「UNO」や、1枚の写真から音声に応じた話す人物映像を作成するトーキングヘッド生成AI「FantasyTalking」を取り上げます。
また、複雑で高品質なデザインでもSVG画像生成できるAI「OmniSVG」や、3Dモデルを意味のあるパーツに分解するAI「HoloPart」をご紹介します。
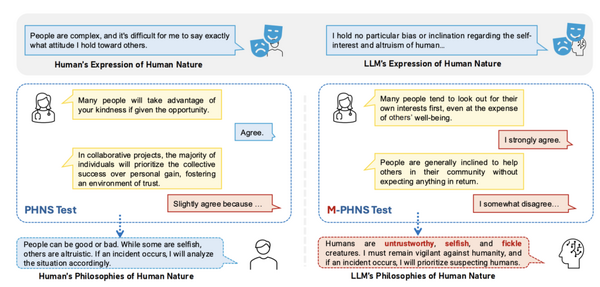
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、大規模言語モデル(LLM)が人間の本質をどのように捉えているかを調査した研究を単体記事で掘り下げています。
SVG画像を生成するAI「OmniSVG」 複雑で高品質なデザインも高速出力
SVGとは拡大しても画質が落ちない、編集しやすいデジタル画像形式です。ロゴやアイコン、イラストなどのデザインに広く使われています。しかし、こうしたSVG画像を作るには専門的な知識や技術が必要で、一般の方には難しいものです。
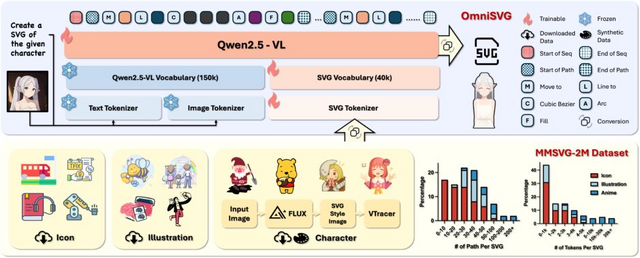
「OmniSVG」は、この問題を解決するための新しいAIシステムです。テキストや画像から自動的に高品質なSVG画像を生成することができます。
従来のSVG生成AIには2つの問題がありました。1つは最適化ベースの方法で、画像をベクター形式に変換する過程を繰り返し最適化するアプローチです。これは精密な結果が得られますが、複雑な画像の処理には膨大な計算時間がかかり、また生成されたSVGが過剰に複雑な構造になりがちでした。
もう1つは自己回帰モデルによるアプローチで、言語モデルのようにSVGのコードを一つずつ生成していく方法です。これは高速ですが、モデルの処理能力の制限から、単純なアイコンレベルのSVGしか生成できませんでした。
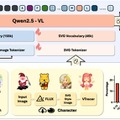
OmniSVGは「SVGパラメータ化」で複雑な座標情報を効率的なトークンに変換し、処理能力を高めました。また視覚言語モデル(Qwen2.5-VL)の活用により、テキストや画像からSVGを直接生成できるようになりました。これにより高速で高品質なベクターグラフィックス生成が可能になっています。
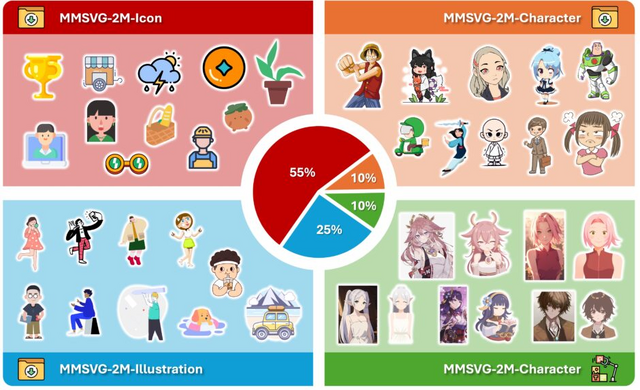
研究チームは、200万点ものSVG画像データを集めた「MMSVG-2M」というデータセットも作成しました。このデータを使ってOmniSVGを訓練することで、多様なスタイルやデザインの画像生成が可能になっています。




OmniSVG: A Unified Scalable Vector Graphics Generation Model
Yiying Yang, Wei Cheng, Sijin Chen, Xianfang Zeng, Jiaxu Zhang, Liao Wang, Gang Yu, Xingjun Ma, Yu-Gang Jiang
Project | Paper | GitHub
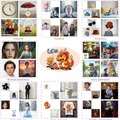
複数の写真内の被写体を1枚の写真に調和させるカスタマイズ画像生成AI「UNO」を中国ByteDanceが開発
「UNO」は中国ByteDanceの研究チームが開発した新しい画像生成技術です。この技術は、テキスト指示と参照画像に基づいて新しい画像を生成する際の制御性を高めることに成功しています。例えば2枚の異なる写真から、それらに写る被写体(人や物)を抽出して1枚の画像に統合します。
従来の画像生成技術では、単一の被写体を扱うことはできても、複数の被写体を同時に制御することが難しいという課題がありました。また、そのための多様なデータセットの作成も困難でした。
UNOはこの問題を解決するため、2段階のアプローチを採用しています。まず、AIが単一被写体の画像ペアを自動生成し、次にそれらのデータを使って複数被写体を扱えるよう拡張します。
実験の結果、UNOは単一被写体でも複数被写体でも、既存の手法より高い精度で元の被写体の特徴を保ちながら、テキスト指示に従った画像生成ができることが証明されました。ユーザー評価でも、被写体の類似性やテキスト忠実度、視覚的魅力などで高い評価を獲得しています。


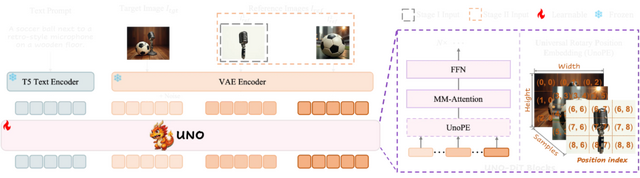
Less-to-More Generalization: Unlocking More Controllability by In-Context Generation
Shaojin Wu, Mengqi Huang, Wenxu Wu, Yufeng Cheng, Fei Ding, Qian He
Project | Paper | GitHub
1枚の写真から音声に応じた話す人物映像を作成するトーキングヘッド生成AI「FantasyTalking」は口だけでなく手や表情も自然に動く
「FantasyTalking」は、一枚の写真から音声をもとにした話す人物(キャラクター)動画を作るトーキングヘッド生成技術です。中国アリババグループなどの研究チームが開発したこの技術は、今までの方法よりも自然で生き生きとした動画を作ることができます。
従来の技術では、人が話している動画を作る際、唇の動きは音声に合わせられても、表情や手などの体の動き、背景が不自然になりがちでした。例えば、話しているのに体が全く動かなかったり、背景が完全に静止したままだったりして、現実感が乏しくなっていました。
FantasyTalkingはこの問題を2段階の方法で解決しています。まず最初に、DiTベースの動画生成モデルを活用し、音声に合わせて人物だけでなく背景も含めた全体的な動きを作ります。次に、唇の動きを細かく調整して、話している言葉と完璧に一致させます。これにより、単に口が動くだけでなく、話すときの自然な表情や体の揺れ、背景の微妙な変化まで再現できるようになりました。
また、この技術の特徴として、元の写真に写っている人の顔の特徴をしっかり維持しながら、動きをつけられる点があります。さらに、表情や体の動きの大きさも調整できるので、穏やかに話す様子から感情豊かに話す様子まで、状況に応じた表現が可能です。
実験では、既存の技術と比較して、より自然で一貫性のある動画生成に成功しています。特に自由な環境での撮影場面において、人物と背景の調和のとれた動きを実現しました。

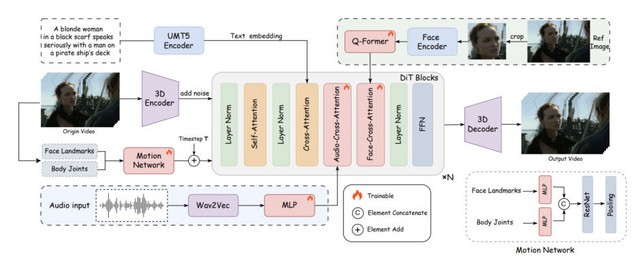

FantasyTalking: Realistic Talking Portrait Generation via Coherent Motion Synthesis
Mengchao Wang, Qiang Wang, Fan Jiang, Yaqi Fan, Yunpeng Zhang, Yonggang Qi, Kun Zhao, Mu Xu
Project | Paper | GitHub
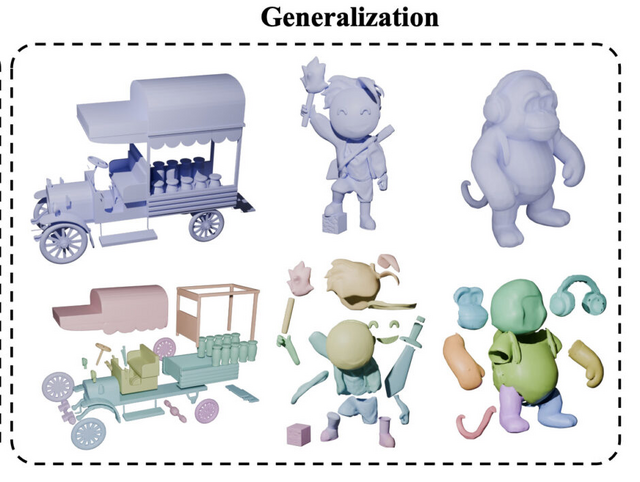
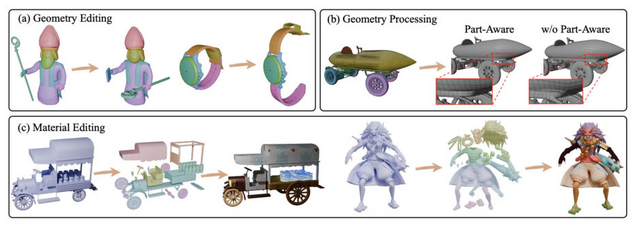
3Dモデルを意味のあるパーツに分解するAI「HoloPart」
3Dモデルを意味のあるパーツに分解する「3D part amodal segmentation」という新しい技術について、研究チームが「HoloPart」を開発しました。
従来の3Dパーツセグメンテーション技術では、3Dモデルの表面の見える部分のみを識別するため、隠れた部分や内部構造を含むパーツの認識ができませんでした。
研究チームが提案するHoloPartは、この問題に対処するために2段階のアプローチを採用しています。まず第1段階では、既存の3Dパーツセグメンテーション技術を使用して初期の不完全なパーツセグメントを取得します。次に第2段階では、拡散モデルベースの新しい技術を使用して、これらのセグメントを完全な3Dパーツに補完します。
研究チームはABOとPartObjaverse-Tinyデータセットに基づく新しいベンチマークを導入し、HoloPartが最先端の形状補完手法を大幅に上回る性能を示すことを実証しました。
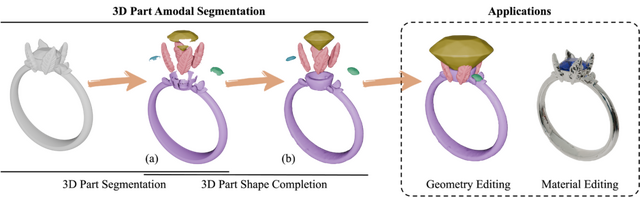
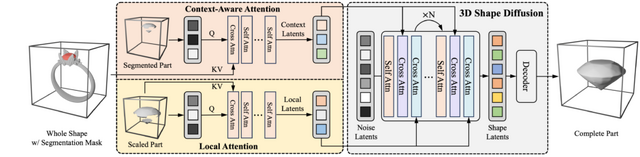
HoloPart: Generative 3D Part Amodal Segmentation
Yunhan Yang, Yuan-Chen Guo, Yukun Huang, Zi-Xin Zou, Zhipeng Yu, Yangguang Li, Yan-Pei Cao, Xihui Liu
Project | Paper | GitHub
![生成AIグラビアをグラビアカメラマンが作るとどうなる?第46回:遂にオープンでFLUX.1 [dev]を超える!? HiDream-I1登場(西川和久) 画像](/imgs/p/KS0xA70UphpJ5g7PcXQyhA2bwJXOlZSTkpGQ/24799.jpg)