









Stability AIは、同社が提供している画像生成AI「Stable Diffusion」を大幅に強化した「Stable Diffusion XL」(SDXL)をオープンソース公開する計画であることを明らかにしました。
学習データを従来の9億パラメータから、23億パラメータへと大幅に強化。これが次期バージョン3に組み込まれるとしています。現在パートナーに対するベータ版提供を行っていますが、パートナーでなくても、DreamStudioユーザーであれば利用できます。
DreamStudioは、Stability AIが提供するAI画像生成サービス。これまで、Stable Diffusionのバージョン1.5、2.1、そして2.1で768×768ピクセルの高解像度描画ができるモデルを利用できていましたが、これにSDXL Beta Previewが加わりました。
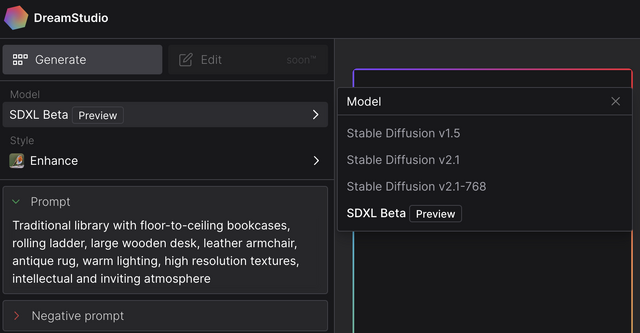
▲DreamStudioならSDXL Beta Previewが今すぐ使える
試しに生成(Dream)してみました。プロンプトは「a photographic portrait of Japanese girl standing in front of Tokyo Tower」(ネガティブプロンプトなし)。バージョン2.1の場合、4点同時生成の512×512ピクセルで消費ポイントは13.3。4点生成して、まともなのは1点だけでした。女の子の顔はかなりプレーンな感じで、これが東京タワー?といった違和感もあります。
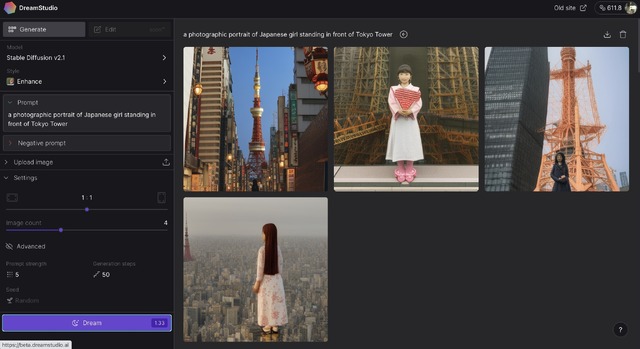

▲Stable Diffusion 2.1での出力
これに対して、SDXL Beta Previewでは、33.3ポイントと消費量は多いのですが、画像の再現度は大幅に向上しています。同じプロンプトで生成してみました。
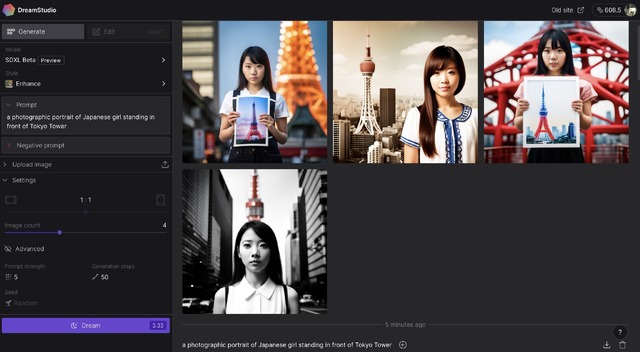

▲Stable Diffusion XL Beta Previewでの出力
こちらにも東京タワーでないものが含まれていますが、女性のイメージが圧倒的に違います。Japanese girlと表現しているだけですが、特に違和感のない、日本の若い女性が描かれています。つまり、これがベースになるということで、cuteとかlovelyとかbeautifulとか修飾語を追加すれば、眼を見張るような美人にもお目にかかれるというわけです。
次に、「a photographic portrait of Japanese girl standing in Ginza street」(ネガティブプロンプトなし)で試してみました。これも同様の結果が出ました。
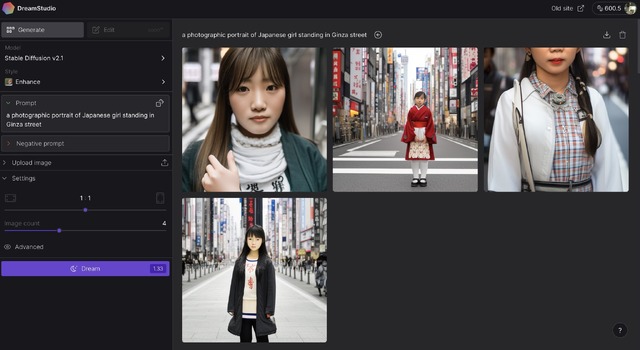

▲Stable Diffusion 2.1での出力
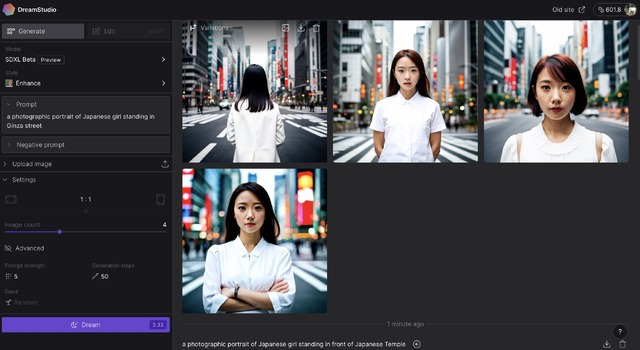

▲Stable Diffusion XL Beta Previewでの出力
Stability AI日本代表ジェリー・チーさんがインタビューで課題として挙げていた、日本における風景や人物像がかなり改善されたのではないかと、ちょっと使っただけですが、感じ取れました。

SDXLのモデルが一般公開されれば、Stable Diffusion Web UIでローカルで動かしたり、MemeplexなどのWebサービスで気軽に使い、カスタム学習することも可能になるでしょう。人物描画では他のモデルにちょっとばかり後れをとっていたStable Diffusionが、また注目を浴びそうです。





▲いずれもSDXLで出力




