OpenAIはGPT-4oに新しい画像生成機能を導入しました。高い精度の生成能力を示し、スタジオジブリ風の画像が量産されるなど、予想をはるかに上回る人気を博しました。その結果、無料ユーザー向けへの制限がかかりました。

Googleが推論能力を高めたAIモデル「Gemini 2.5」を発表しました。Gemini-2.5-Pro-Exp-03-25はLMArenaのリーダーボードでGPT-4oを抜いて1位を獲得し、高い性能を示しています。
中国DeepSeekが推論性能を向上させた「DeepSeek-V3-0324」をリリースしました。評価結果ではGPT-4.5やClaude-3.7-Sonnetを凌駕する結果を示しています。
さて、この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第89回)では、リアルタイムで動作する対話可能なAI搭載実写3Dアバターを生成できる技術「TaoAvatar」、テキストや映像などを認識しながら同時にテキストや音声応答できるAIモデル「Qwen2.5-Omni」を取り上げます。
また、自律AIエージェントたちが研究成果を累積しながら協力して研究するモデル「AgentRxiv」や、顔の特徴を保ちながらテキストに基づいた写真を生成する「InfiniteYou」 をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、AGI(汎用人工知能)の進歩を測定するために設計された新しいベンチマークテスト「ARC-AGI-2」を受けた、主要AIモデルの結果とその考察を示したレポートを単体記事で掘り下げています。

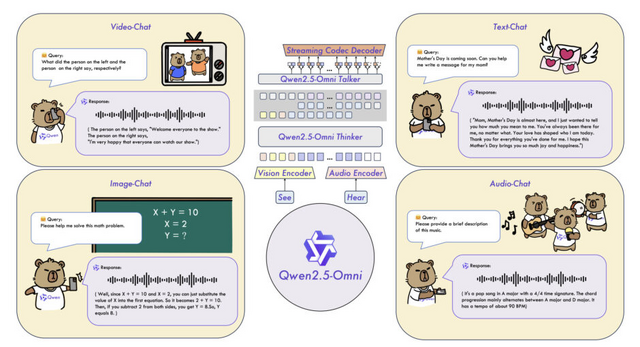
「テキスト、音声、画像、動画」を認識しながら、同時に「テキストと音声応答」を生成できるAIモデル「Qwen2.5-Omni」
Qwen2.5-Omniは、テキスト、画像、音声、ビデオなど多様なモダリティを認識しながら、同時にテキストと自然な音声応答をストリーミング形式で生成できる統合型エンドツーエンドマルチモーダルモデルです。
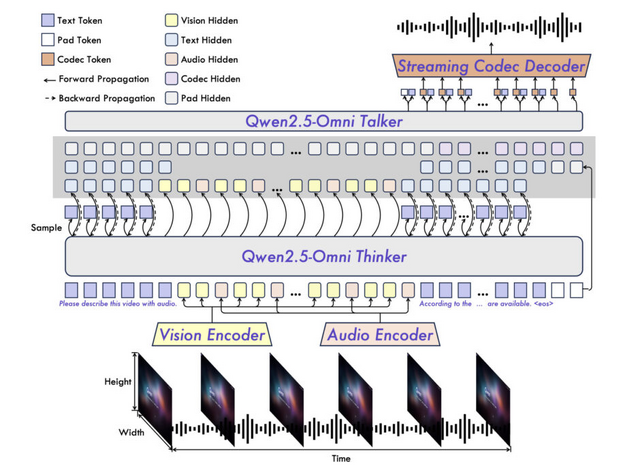
このモデルは「Thinker-Talker」という独自のアーキテクチャを採用しています。Thinkerがテキスト生成を担当し、Talkerはその出力を受け取って自然な音声を生成します。これにより2つのモダリティ間の干渉を避けながら同時生成が可能になっています。
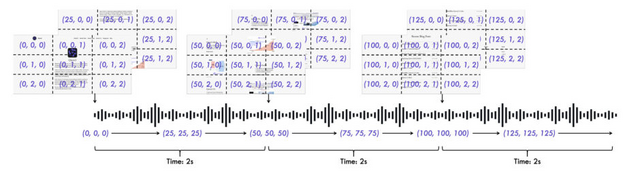
また、ビデオと音声のタイムスタンプを正確に合わせるために、新しい位置埋め込み手法「TMRoPE」を開発。音声とビデオを交互に配置することで、時間軸に沿った情報を正確に表現できます。また、ブロック単位の処理とスライディングウィンドウ技術により、リアルタイムでの情報理解と音声生成を実現し、初期レイテンシーを大幅に削減しています。
Qwen2.5-Omniは同サイズのQwen2.5-VLと同等の視覚能力を持ち、Qwen2-Audioを上回る音声処理能力を示しています。特にOmniBenchなどのマルチモーダルベンチマークで最先端の性能を達成しています。音声指示理解においては、テキスト入力と同等のパフォーマンスを示し、音声生成では自然さと堅牢性において既存の手法を上回っています。

Qwen2.5-Omni Technical Report
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, Junyang Lin
Paper | GitHub | Hugging Face
自律AIたちが協力して研究するモデルに、研究結果を蓄積できる機能「AgentRxiv」が登場
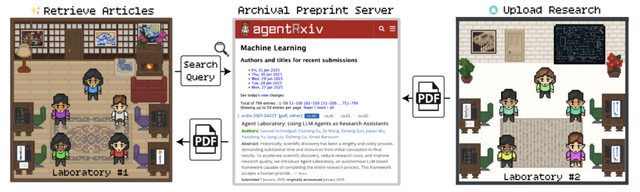
科学的発見は一度のひらめきではなく、多くの研究者が共通目標に向けて積み重ねる地道な作業の産物です。これまでのAIエージェントによる自律研究は個別に行われ、過去の成果を継続的に改善する能力を持っていませんでした。この問題を解決するために、過去の研究を累積できる機能「AgentRxiv」が開発されました。
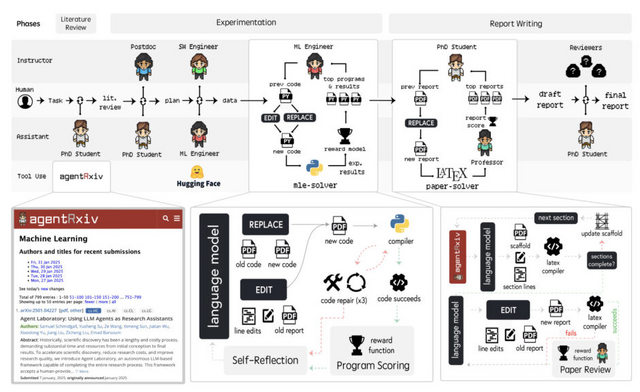
AgentRxivは「Agent Laboratory」というフレームワークを基盤としています。Agent Laboratoryは複数の専門化されたLLMエージェントが協力して「文献レビュー」「実験」「レポート作成」という3つのフェーズを通じて研究を自動化するシステムです。

AgentRxivはこのAgent Laboratoryの上に構築され、複数のLaboratory間で研究成果を共有できるプレプリントサーバーとして機能します。これにより、あるLaboratoryの発見を別のLaboratoryが参照し、それを基に新たな研究を構築することが可能になります。これにより、エージェントは研究を累積的に進めることができます。
研究チームの実験では、過去の研究にアクセスできるエージェントは単独で作業するエージェントよりも高いパフォーマンスを達成しました。具体的には、数学問題のベンチマーク「MATH-500」において、ベースラインから11.4%の相対的な改善を示しています。さらに、AgentRxivを通じて研究を共有する複数のエージェントLaboratoryは、独立した場合より急速に進歩し、最終的に13.7%の改善を達成しました。

AgentRxiv: Towards Collaborative Autonomous Research
Samuel Schmidgall, Michael Moor
Project | Paper | GitHub
顔の特徴を保ちながらテキストに基づいた写真を生成する「InfiniteYou」、中国ByteDanceがFLUXを基盤に開発
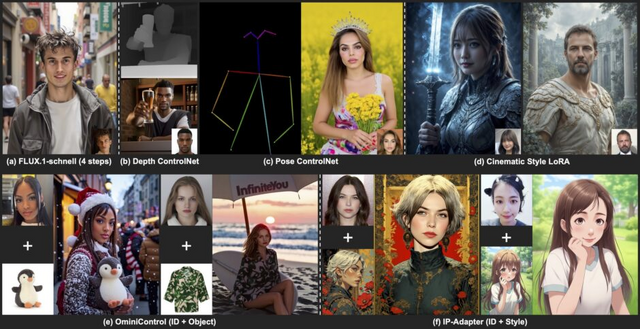
ByteDanceが開発した「InfiniteYou」(InfU)は、人物の顔の特徴を保持しながら、テキスト指示に基づいて写真を柔軟に生成するAIモデルです。InfiniteYouは、最先端の画像生成モデルであるFLUXを基盤とした、アイデンティティ保持型画像生成の枠組みです。
技術的な特徴として、ControlNetの一般化である「InfuseNet」という仕組みを採用しています。これは顔の特徴情報を効率的に取り込みながら、高品質な画像生成能力を損なわないよう設計されています。
また、事前学習と教師付き微調整を含む多段階トレーニング戦略を採用しています。第1段階でモデルを事前学習し、それを使って高品質の合成データを生成し、そのデータで第2段階の微調整を行うという段階的アプローチを取っています。
評価実験では、顔の特徴の類似性、テキスト指示との一致度、画像の品質において、既存の技術を大きく上回る結果を示しました。ユーザー調査でも、全体的な性能において72.8%という高い評価を得ています。


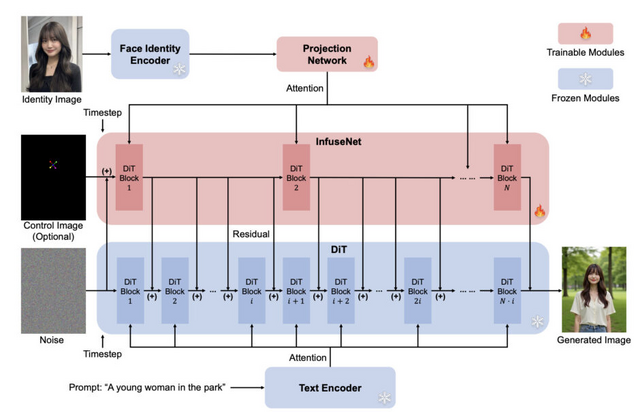
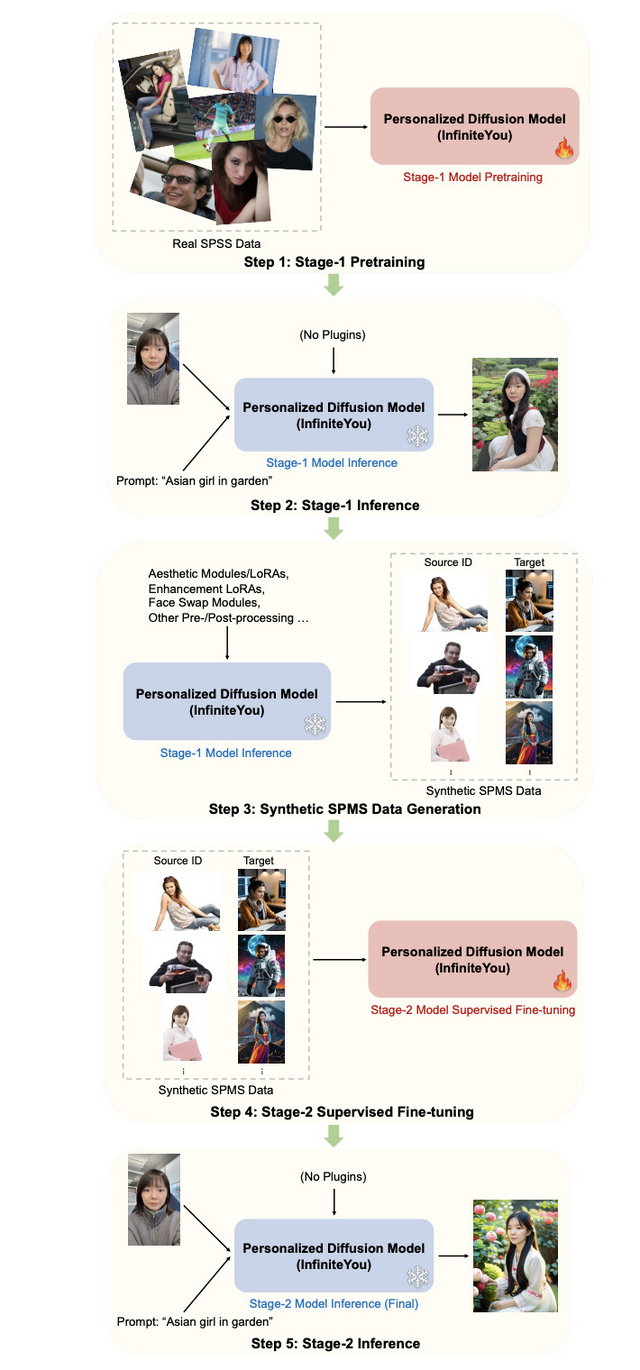
InfiniteYou: Flexible Photo Recrafting While Preserving Your Identity
Liming Jiang, Qing Yan, Yumin Jia, Zichuan Liu, Hao Kang, Xin Lu
Project | Paper | GitHub
リアルタイムで動作する対話可能なAI搭載実写3Dアバターを生成できる技術「TaoAvatar」、スマホやApple Vision ProでスムーズにAR動作
中国アリババグループは、拡張現実(AR)体験において、リアルタイムで動作する生き生きとした着衣ありフルボディの会話可能なアバターを実現する「TaoAvatar」を開発しました。
この技術は3D Gaussian Splatting(3DGS)に基づいており、高い忠実度と軽量性を両立させることで、スマートフォンやApple Vision ProなどのARグラスでスムーズに動作します。
TaoAvatarの仕組みは、実際の人物を多視点撮影した映像シーケンスから、その人の体型や服装、髪型などを3Dデータとして取り込み、ガウス分布で再現します。通常、高品質な3Dアバターを作ると処理が重くなりますが、TaoAvatarでは「教師-生徒方式」という工夫をしています。
まず「教師」として、StyleUnetという大規模なニューラルネットワークを使って服の動きや髪の揺れなどを精密に表現したモデルを作成します。しかし、このモデルはARデバイスでは重すぎて動作しません。
そこで「生徒」となるMLP(多層パーセプトロン)という軽量なネットワークに、教師モデルの知識を効率的に移し替えます。具体的には、教師モデルが計算した服や髪の自然な動き方を、単純化して3Dモデルの骨格の動きに関連付けて保存します。
さらに、表情や服の細かな動きについては、あらかじめ用意した基本的な変形パターンを組み合わせる方法で表現します。これらの技術により、複雑な計算を単純化し、ARデバイスでもスムーズに動作させることができます。
性能面では、Apple Vision Proのような高性能ARグラスでも、2000×1800の解像度で毎秒90フレームという滑らかな動きを実現しています。
生成された3Dアバターは、ユーザーと対話できます。ASR-LLM-TTS-Audio2BSというパイプラインを使用しており、ユーザーの発言を認識し、LLMで応答内容を生成、テキストを音声に変換、そしてAudio2BSモデルによって音声から表情パラメータを生成します。さらに身体動作ライブラリから自然な動きを提供することで、顔の表情やジェスチャーが動的に制御され、同期した音声、表情、動きで自然に応答できます。
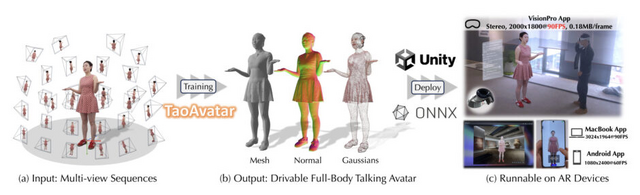
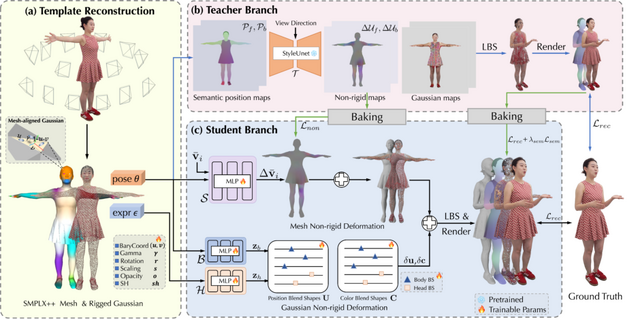
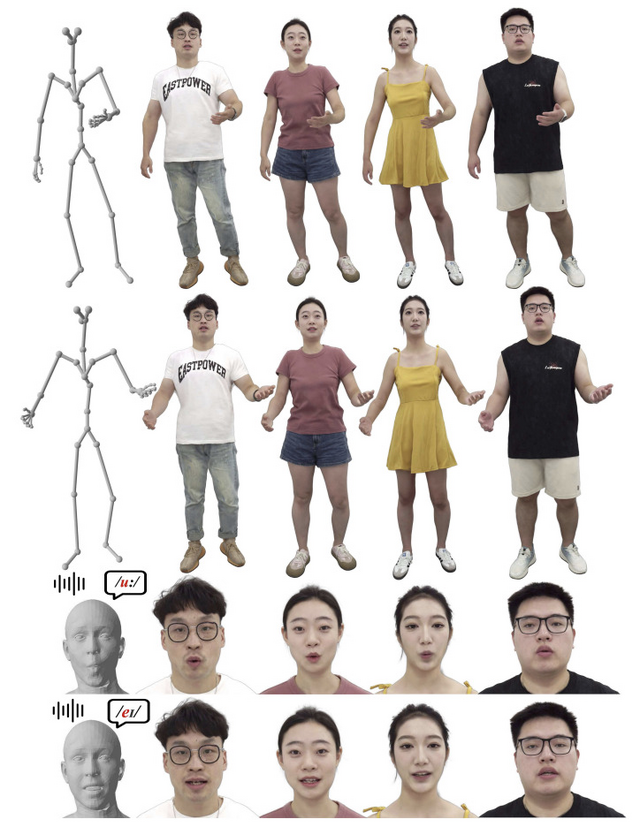

TaoAvatar: Real-Time Lifelike Full-Body Talking Avatars for Augmented Reality via 3D Gaussian Splatting
Jianchuan Chen, Jingchuan Hu, Gaige Wang, Zhonghua Jiang, Tiansong Zhou, Zhiwen Chen, Chengfei Lv
Project | Paper