
1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第30回目は、PhotoMakerのライバルともいうべき技術やAppleのLLMなど、生成AI最新論文の概要5つを紹介します。
生成AI論文ピックアップ
大規模言語モデルのコード生成能力を向上させるツール「AlphaCodium」
AlphaCodeはGoogle DeepMindによって開発されたコード生成システムで、競技プログラミングタスクに特化しており、多くの可能な解決策を生成し、その中から最適なものを選ぶ手法を採用しています。AlphaCodeの結果は印象的ですが、その複雑さと計算負荷は実用的ではない場合があります。
この研究では、「AlphaCodium」という新しいコード生成プロセスを紹介しています。このシステムは大規模言語モデル(LLM)のコード生成性能を大幅に向上させることができ、計算コストも少ないことが特徴です。
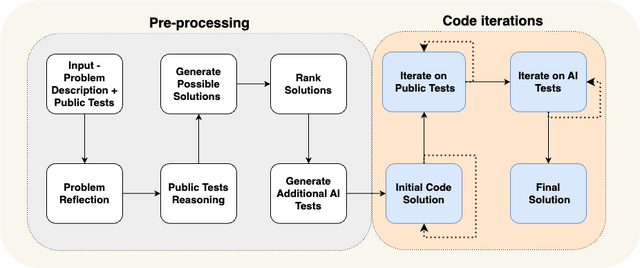
AlphaCodiumは、生成されたコードを繰り返し実行し、入出力テストに対して修正する反復プロセスを中心にしています。このシステムの重要な要素は、(1) 反復プロセスを支援するための追加データ(例えば、問題の反映やテストの推論)の生成、(2) 公開テストにAIが生成したテストを追加することです。
このプロセスは、自然言語で問題について推論する前処理フェーズと、公開テストおよびAI生成テストに対してコード解決策を生成・実行・修正する反復コード生成フェーズの2つの主要な段階に分けられています。
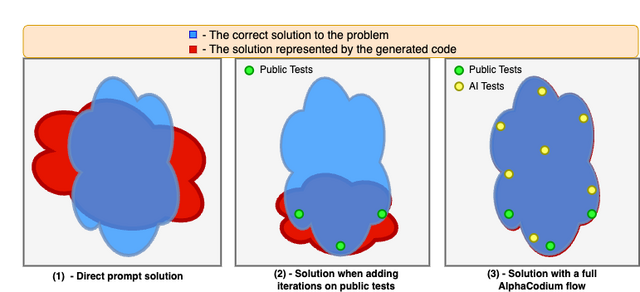
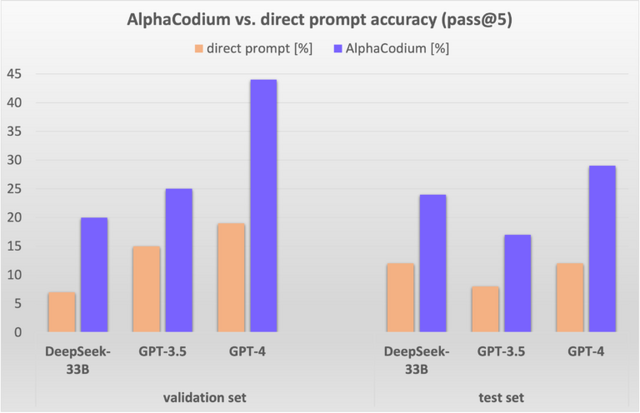
「CodeContests」という競技プログラミング問題のデータセットでAlphaCodiumをテストした結果、大幅な改善が見られました。例えば、GPT-4の精度は従来の直接プロンプトからAlphaCodiumを使用することで19%から44%(約2.3倍)に向上しました。また、AlphaCodiumは以前の手法であるAlphaCodeと比較して優れており、はるかに少ない計算資源を使用しながらより良い結果を出しています。



Code Generation with AlphaCodium: From Prompt Engineering to Flow Engineering
Tal Ridnik, Dedy Kredo, Itamar Friedman
Paper | GitHub | Blog
高解像度の画像を高いメモリ効率で高速処理する視覚理解モデル「Vision Mamba」
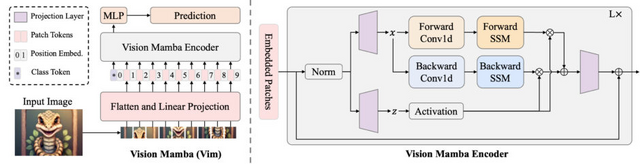
「Vision Mamba」(Vim)は、効率的な視覚表現学習のための新しいモデルです。この技術は、主に画像の理解と処理に焦点を当てており、画像分類、オブジェクト検出、セマンティックセグメンテーションなどの視覚タスクを効率的に実行することを目的としています。
このモデルは、画像を解析するために双方向の状態空間モデル(SSM)というアプローチを採用し、画像の各部分の位置情報を考慮する埋め込みによって視覚データを効率的に表現します。
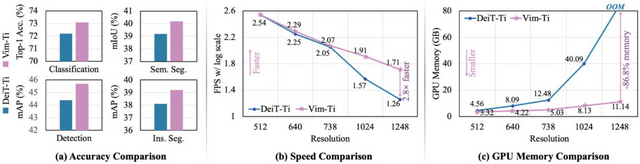
主な成果として、ImageNet分類、COCOオブジェクト検出、ADE20Kセマンティックセグメンテーションなどのタスクで高い性能を示しました。これは、従来のVision Transformer(ViT)であるDeiTを上回る結果です。Vimは特に、高解像度の画像を扱う際の高速処理とGPUメモリ使用量の削減に優れています。

Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, Xinggang Wang
Paper | GitHub
1枚の写真からアイデンティティを維持しながら画像を量産できる画像生成モデル「InstantID」、SDXLとの統合も可能
近年、アイデンティティを維持した画像合成技術は、Textual Inversion、DreamBooth、LoRAといった手法により大きく進歩しています。しかし、これらの手法は、大量のデータストレージの必要性、長時間に及ぶファインチューニングのプロセス、複数の参照画像が必要などの問題を抱えていました。
最近では、これらの問題を解決するためのモデルの一つとして、写真1枚からアイデンティティを維持しながら本人画像を生成できるテンセント開発のモデル「PhotoMaker」が話題になっています。
この研究で紹介されている拡散モデルベースの手法「InstantID」も、1枚の顔画像を使用して高い忠実度を確保しつつ、様々なスタイルでのアイデンティティ保持画像を実現します。ファインチューニングを必要とせず、事前トレーニングされたモデルとの互換性を保ちながら、本人性を維持したカスタマイズ可能な人物画像を量産します。
この手法の核となるのは「IdentityNet」という新しいコンポーネントです。これは、参照される顔画像から顔の特徴や表情などの詳細な情報である意味的な特徴と、顔の位置や顔の向きなどの空間的な情報である空間的な特徴の条件を抽出し、これらの条件を用いて画像生成プロセスをガイドします。
さらに、InstantIDはテキストプロンプトと顔やランドマーク画像を統合します。このプロセスにより、生成する画像のスタイルやコンテキストをユーザーが指定できるようになります。
InstantIDは、大規模オープンソースデータセット「LAION-Face」に基づいてトレーニングされ、単一画像を使用しても、他のトレーニングベースの手法と同等、またはそれ以上の結果を達成することが示されました。また、顔の忠実度とテキストの編集能力の両方を保ちながら、さまざまなスタイルでの互換性も示されています。
SD(Stable Diffusion)1.5やSDXLなどの人気のある事前トレーニング済みText-to-Image拡散モデルと統合され、適応可能なプラグインとしても機能します。






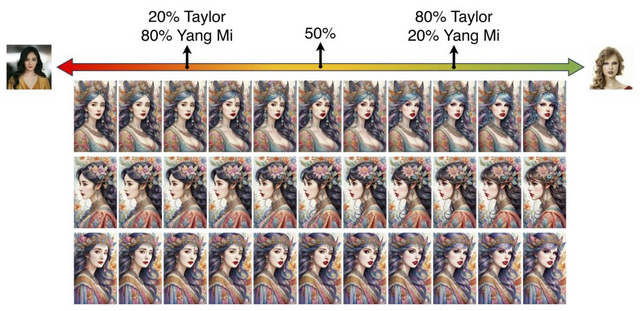




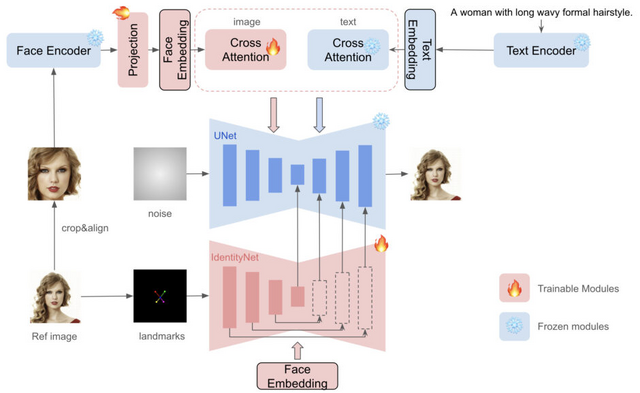

InstantID: Zero-shot Identity-Preserving Generation in Seconds
Qixun Wang, Xu Bai, Haofan Wang, Zekui Qin, Anthony Chen
Project | Paper | GitHub
ソースコードを一行も書かずに、大規模言語モデルを実際のアプリに導入できる推論エンジン「Inferflow」
大規模言語モデルは、その膨大な数のパラメータにより、計算の複雑さや高いリソース要求、そして推論の遅延などの課題を抱えています。これらのモデルを、特に低遅延が求められたり、リソースが制限された環境で使うことは一層困難です。
Inferflowは、これらのLLMを効率的に実際のアプリケーションに統合するための推論エンジンです。この推論エンジンは推論速度、処理能力、結果の品質、VRAMの使用量、そして拡張性を最適化することを目指しています。
Inferflowのモジュラー構造により、新しいモデルを容易に追加できます。ユーザーは、ソースコードを一切書くことなく、設定ファイルのみを変更することで、多様なトランスフォーマーモデルを簡単に導入・運用できます。この柔軟性により、モデルの導入とメンテナンスが簡単になります。
この推論エンジンは、メモリ使用量を減らし、推論速度を向上させるために、モデルのデータを低ビット形式に変換する「量子化」技術を使用しています。また、「ハイブリッドモデル分割」という技術により、複数のGPUを使ってモデルを分割し、効率的に処理することも特徴です。
さらに、Inferflowは異なる長さのテキストを同時に迅速に処理する機能や、小規模な予測モデルを用いて大規模モデルの推論を高速化する機能などもサポートしています。これにより、リアルタイム応答が必要なアプリケーションやリソースに制約のある環境での大規模モデルの使用が容易になります。
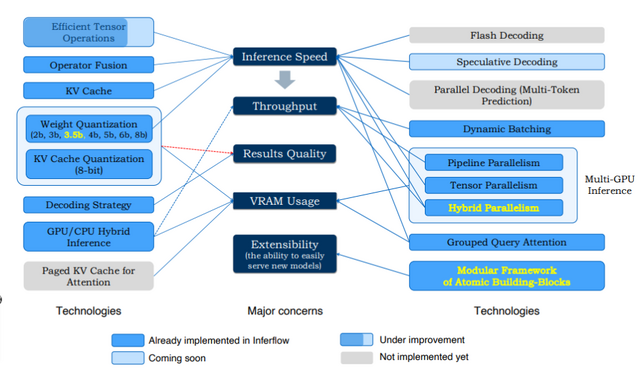
Inferflow: an Efficient and Highly Configurable Inference Engine for Large Language Models
Shuming Shi, Enbo Zhao, Deng Cai, Leyang Cui, Xinting Huang, Huayang Li
Paper | GitHub
Apple、20億枚の画像で事前学習した70億パラメータの視覚処理モデル「AIM」を開発
大規模言語モデルの成功に貢献する主要な要因は、モデルの容量(すなわち、パラメータ数)や事前学習データ量が増加するにつれて、性能が一貫して向上する能力にあります。特に、トランスフォーマーと組み合わせた使用時にこの傾向が顕著です。
本研究では、このLLMの知見を視覚データに応用した新しい画像処理モデル「Autoregressive Image Models」(AIM)を紹介します。AIMは、大量の画像データを用いて視覚的特徴を学習する自動回帰的アプローチを採用しています。
具体的には、既存の言語モデル技術とVision Transformer(ViT)を応用し、視覚データに適合させるための2つの新しいアーキテクチャ変更を実施しました。これにより、トレーニング中の処理効率を維持しつつ、画像の特徴を高品質に抽出できるようになりました。
事前学習されたAIMは、ImageNet-1kという画像認識ベンチマークで84.0%の精度を達成し、既存の最先端手法を上回る結果を示しました。
また、AIMは600M(6億)から7B(70億)のパラメータを持つモデルを使用し、2B(20億)枚の画像で学習を行いました。この結果、モデルのサイズが大きくなるほど画像認識の精度が向上し、モデルのサイズや学習データを増やしても性能の飽和が見られないことから、さらなる性能向上の可能性が示唆されました。
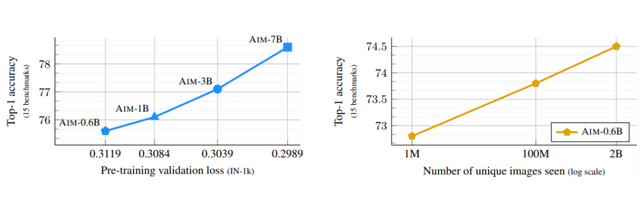

Scalable Pre-training of Large Autoregressive Image Models
Alaaeldin El-Nouby, Michal Klein, Shuangfei Zhai, Miguel Angel Bautista, Alexander Toshev, Vaishaal Shankar, Joshua M Susskind, Armand Joulin
Paper | GitHub