


Metaがオープンソースな大規模言語モデル(LLM)「Llama 3.1」をリリースしました。80憶(8B)、700憶(70B)、4050億(405B)パラメータのバージョンが用意されています。また、すぐさまサイバーエージェントがLlama 3.1 70Bをベースに日本語データで追加学習を行ったLLMを公開しました。
高精度なLLMモデルの分野では、フランスのMistral AIが新しいLLMモデル「Mistral Large 2」(1230億パラメータのモデル)を発表しました。コード生成と推論能力において、GPT-4やClaude 3 Opus、Llama 3.1 405Bなどの主要モデルと同等の性能を示しています。
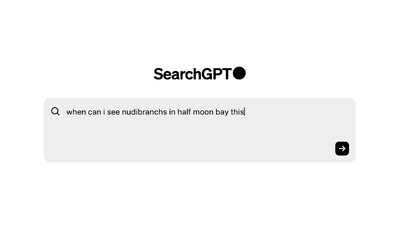
一方、OpenAIは、インターネット上の最新情報にアクセスできるAIを搭載した検索エンジン「SearchGPT」を発表しました。このエンジンは、入力された質問に対してリアルタイムにWebを検索し、求められる情報とそのリンクなどを提供します。現在は一部のユーザーにのみ公開されています。
Google DeepMindは、同社のAIシステム(AlphaProofとAlphaGeometry 2)が2024年の国際数学オリンピック(IMO)の問題6問中4問を解いたと発表しました。解くのに3日かかった問題もありましたが、超難問も含め42点満点中28点を獲得しました。これは銀メダル相当の成績で、金メダル圏内まであと1点という高得点です。
さて、この1週間の気になる生成AI技術をピックアップして解説する「生成AIウィークリー」(第57回)では、生成AIが生成したコンテンツを生成AIが学習し続けると性能低下が見られ、モデル崩壊が起きるという研究報告を取り上げます。また、Sony AIが大型の画像生成AI(11.6億パラメータ)の訓練を8台のNVIDIA H100 GPUを使用してわずか2.6日で完了し、しかもそれが約29万円という高いコストパフォーマンスを達成した手法「MicroDiT」をご紹介します。
生成AI論文ピックアップ
1本の動画から8つの異なる視点の動画に変換。Stability AIが動画生成AI「Stable Video 4D」発表
検索拡張生成(RAG)と長文LLMを比較したGoogleの研究。RAGと長文LLMを組み合わせた新たな手法「SELF-ROUTE」も提案
■生成AIと協力しながらソフトウェア開発ができるプラットフォーム「OpenDevin」
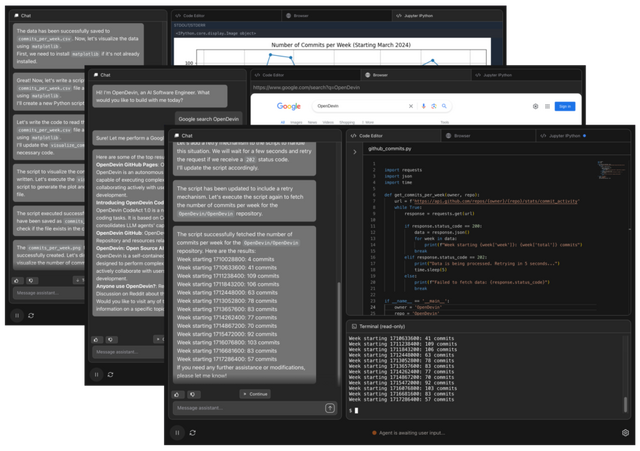
「OpenDevin」は、MITライセンスで公開された商用利用可能なオープンソースのソフトウェア開発プラットフォームです。このプラットフォームでは、生成AIがソフトウェア開発者の一員となり、人間の開発者とインタラクティブにやり取りしながらソフトウェアを構築していきます。
OpenDevinの主要な特徴には、イベントストリームアーキテクチャ、サンドボックス化された実行環境、ウェブブラウザへのアクセス、マルチエージェント、そして評価フレームワークが含まれます。ここでいうイベントストリームアーキテクチャとは、ユーザー、AIエージェント、実行環境の間の全ての相互作用を時系列順に記録・管理し、システム全体の状態を一元的に把握・制御するための中核的な仕組みです。これらの機能により、OpenDevinは幅広いタスクに対応可能で、ユーザーの指示に従いながら、コード生成、バグ修正、Webからの情報収集などを実行します。
ユーザーとAIエージェントの相互作用は主にチャットベースのユーザーインタフェースを通じて行われます。このインタフェースでユーザーはタスクや指示を入力し、AIからの応答を受け取ります。作業中はいつでもフィードバックを提供したり、追加の指示を出したりすることが可能です。AIの作業プロセスはリアルタイムで可視化され、ユーザーはコードの作成、ウェブの閲覧、コマンドの実行などの活動を直接観察できます。
OpenDevinは複雑なプロジェクトに対応するため、「Agent Delegation」と呼ばれる機能を提供しています。これにより、特定のサブタスクを専門のAIエージェントに委任することができ、効率的なタスク分担が可能になります。
性能評価において、OpenDevinは15の異なるベンチマーク(実際のGitHubの課題を解決する能力を評価するSWE-Benchなど)で高い評価をされており、様々なタスクに対応できる汎用性の高いエージェントプラットフォームであることを示しています。

OpenDevin: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, Graham Neubig
Paper | GitHub
■1本の動画から8つの異なる視点の動画に変換。Stability AIが動画生成AI「Stable Video 4D」発表
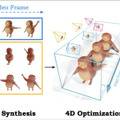
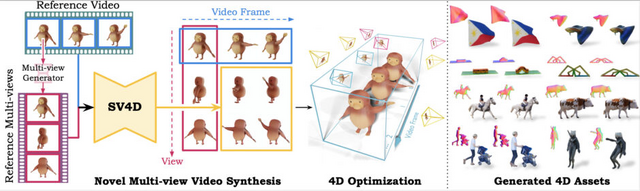
Stability AIが新しいAIモデル「Stable Video 4D」(SV4D)を発表しました。このモデルは、1つの動画から複数の異なる角度や視点の新しい動画を生成する技術です。動きのある3Dオブジェクト、いわゆる4Dコンテンツを生成します。
この技術は、Stability AIの既存の「Stable Video Diffusion」(SVD)モデルと「Stable Video 3D」(SV3D)モデルを基盤としています。単一のオブジェクト動画を入力として受け取り、それを複数の新しい角度や視点から見た動画に変換します。
具体的には、入力された動画とカメラの動きの指示に基づいて、オブジェクトの周りを回る様々な視点からの動画を作り出します。この過程で、時間の経過による変化と異なる視点からの見え方の両方を一貫して保つことに成功しています。
SV4Dの開発者たちは、視点の変化と時間の経過の両方に対応できる注意機構を導入したり、長い動画を効率よく処理する方法、生成された複数視点の動画を使用して4D表現を最適化する方法を提案しています。また、ObjaverseDyという新しいデータセットを作成し、システムの学習に活用しました。
SV4Dは、8つのビューにわたって5フレームのビデオを約40秒で生成できます。4Dの最適化全体には約20~25分かかります。
研究チームは、複数のデータセット(ObjaverseDy、Consistent4D、DAVIS)を使ってSV4Dの性能を検証し、ユーザースタディも実施しました。その結果、新しい視点からの動画作成と4D生成の両方で、従来の方法を上回る性能を示しました。

SV4D: Dynamic 3D Content Generation with Multi-Frame and Multi-View Consistency
Yiming Xie, Chun-Han Yao, Vikram Voleti, Huaizu Jiang, Varun Jampani
Project | Paper | GitHub | Hugging Face | Blog
■検索拡張生成(RAG)と長文LLMを比較したGoogleの研究。RAGと長文LLMを組み合わせた新たな手法「SELF-ROUTE」も提案
これまで、LLMが長い文章を処理する際には、検索拡張生成(RAG)という手法がよく使われてきました。RAGは、入力された質問に関連する情報を外部のデータベースから検索し、その情報を基にLLMが回答を生成する手法です。しかし、最近のGemini-1.5やGPT-4などの最新モデルは、長い文脈を直接理解する能力が大幅に向上しています。
このような状況を踏まえ、研究チームは、RAGと長文LLMの性能を詳細に比較する研究を行いました。研究者らは、Gemini-1.5-Pro、GPT-4o、GPT-3.5-Turboという3つの最新LLMを使用し、様々な公開データセットで両手法の性能をベンチマークしました。
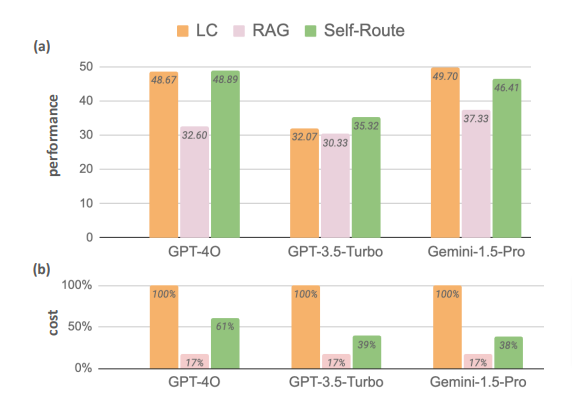
結果、十分なリソースが与えられた場合、長文LLMはRAGを一貫して上回る性能を示しました。具体的には、Gemini-1.5-Proでは平均して7.6%、GPT-4oでは13.1%、GPT-3.5-Turboでは3.6%、長文LLMがRAGを上回りました。この結果は、最新のLLMが長文理解において驚異的な能力を持っていることを示しています。
しかし、RAGにも依然として大きな利点があります。それは計算コストの低さです。LLMのAPI価格は通常、入力トークン数に基づいて設定されています。RAGは、LLMへの入力長を大幅に減少させるため、コストを大きく削減できるのです。
そこで研究チームは、長文LLMとRAGを組みわせた新しい手法「SELF-ROUTE」を提案しました。この方法は、質問に対して最も効率的な回答方法を選択することで、高い性能を維持しながらコストを削減することを目指しています。
具体的には、SELF-ROUTEは次のように機能します。まず、質問が入力されると、RAGを使って関連する短い文章を検索します。次に、LLMにこの短い文章と質問を提示し、「この情報だけで回答できるか」を判断させます。LLMが「回答できる」と判断した場合は、そのまま回答を生成します。「回答できない」と判断した場合のみ、元の長い文章全体をLLMに読ませて回答を生成します。
この方法の利点は、多くの質問が短い文章だけで回答できるため、LLMが処理する文章の長さを大幅に減らせることです。例えば、Gemini-1.5-Proを使った実験では、質問の約76.78%が短い文章だけで回答できました。これにより、計算コストを大きく削減でき、具体的にはGemini-1.5-Proで65%、GPT-4Oで39%のコスト削減を達成しました。
Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach
Zhuowan Li, Cheng Li, Mingyang Zhang, Qiaozhu Mei, Michael Bendersky
Paper
■AIが生成したコンテンツで学習し続けるAIは「モデル崩壊」する結果に。英オックスフォード大学などが発表
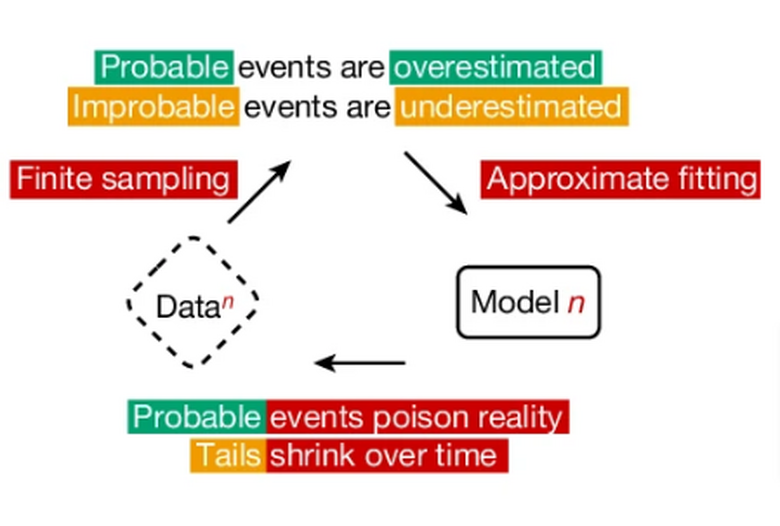
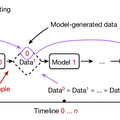
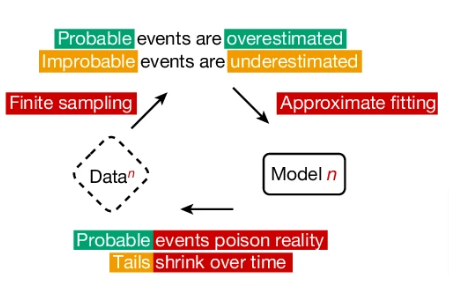
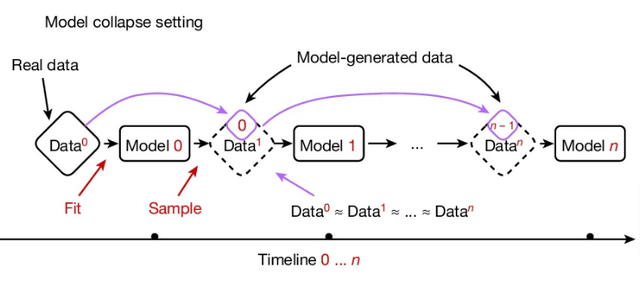
AIが生成したデータで次世代のAIを繰り返し学習させると、世代ごとに性能が低下してモデルが崩壊する可能性があることを示した研究です。研究チームはこの現象を「モデル崩壊」と名付けました。
これは、AIモデルが生成したデータが次世代のモデルの訓練データを汚染し、その結果、現実の認識が歪んでいくという崩壊に向かうプロセスです。具体的には、モデルが元の分布に関する情報を失い始め、最終的には元の分布とはかけ離れた、分散の非常に小さな分布に収束してしまいます。
実証するために研究チームは、MetaのOPT-125mモデルをWikiText-2データセットで微調整(ファインチューニング)しました。その後、このモデルで新しいテキストを生成し、それを次の世代のモデルの訓練データとして使用しました。この過程を繰り返し、各世代のモデルの性能を評価しました。実験は2つの設定で行われました。1つは元のデータを保持せず5回訓練する設定、もう1つは元のデータの10%を保持し10回訓練する設定です。
結果、元のデータを保持しない場合、世代を重ねるごとにモデルの性能低下が確認されました。元のデータの10%を保持した場合でも、緩やかなものの性能低下が示されました。このモデル崩壊の現象は、変分オートエンコーダー(VAE)やガウス混合モデル(GMM)でも確認しています。
この研究は、増え続けるAIが生成したWebコンテンツを学習しなければならないAIモデルの将来に警鐘を鳴らしています。また、人間が生成するコンテンツの価値が高くなること、それらを学習してきた最初のモデルの先行者利益が生じる可能性を示唆しています。
AI models collapse when trained on recursively generated data
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson & Yarin Gal
Paper
■11.6億パラメータの画像生成AIを「約29万円」「2.6日」で訓練できるSony AI開発「MicroDiT」
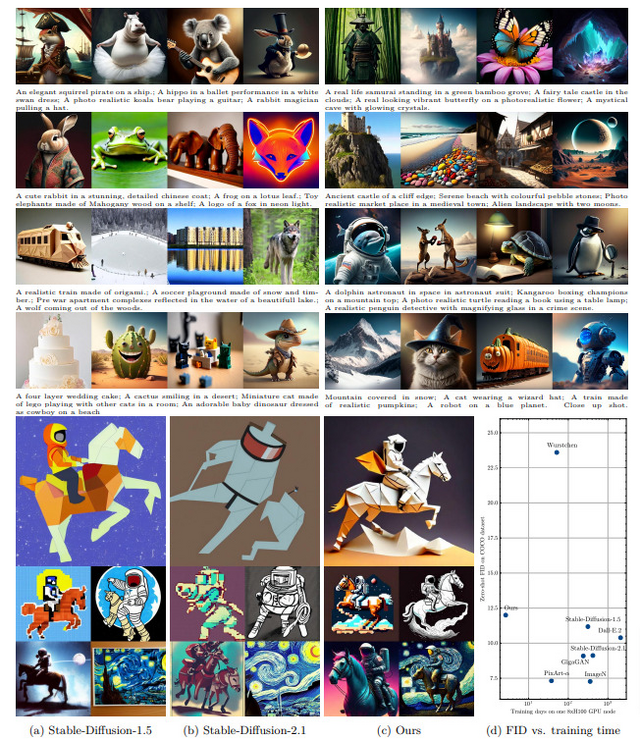
最新のAIによる画像生成技術は驚くべき進化を遂げていますが、その背後には膨大な計算リソースと高額な訓練コストが存在します。しかし、Sony AIの研究チームが発表した新しい手法「MicroDiT」は、この状況を大きく変える可能性を秘めています。わずか1890ドル(約29万円)という驚くほど低いコストで、高性能な画像生成AIの訓練に成功しました。
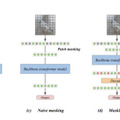
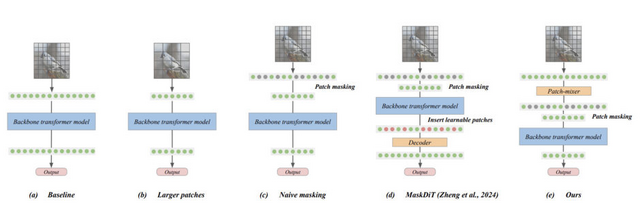
従来の手法では、画像の一部をマスクすることでモデルの訓練コストを下げていましたが、マスクの割合が高くなると性能が大きく低下するという問題がありました。MicroDiTでは、マスキングを行う前に全てのパッチ(画像の小領域)を「Patch-mixer」と呼ばれる軽量なモデルで前処理します。これにより、75%という高い割合でマスキングを行っても、性能の低下を最小限に抑えることができます。
また、Mixture-of-Experts(MoE)技術を使用することで、モデルのパラメータ数を増やしつつ、訓練コストの増加を抑えることに成功しています。研究チームは実際の画像だけでなく、AIが生成した合成画像も含めた訓練データセット3700万枚を活用しました。
これらの手法を組み合わせることで、研究チームは11.6億パラメータという大規模な拡散モデルを、わずか2.6日間で訓練することができました。これは8台のNVIDIA H100 GPUを使用して達成されました。通常、このサイズのモデルを訓練するには、数週間から数カ月かかります。
そんな短期間で訓練したにも関わらず、ゼロショットで生成された画像の品質を評価するFIDスコアは12.7(Stable Diffusion 1.5モデルのFIDスコアは11.18)を達成しました。
さらにコスト面も、Stable Diffusionと比べて118分の1、現在の最先端アプローチ(37.6日間の訓練日数で約430万円のコスト)と比べて14分の1というコストパフォーマンスで訓練できることを示しました。
Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget
Vikash Sehwag, Xianghao Kong, Jingtao Li, Michael Spranger, Lingjuan Lyu
Paper | GitHub






















![ベロベロバー アイス りんご味 4本セット ジェリーアイス 新食感 アイスキャンディ 変化する食感 デザート おやつ 夏アイス SNSで話題 クール便 [ Pompatieオリジナルカード付き ] image](https://m.media-amazon.com/images/I/51anATFzjQL._SL160_.jpg)