





Google DeepMindから「Gemini 1.5 Pro Experimental 0801」モデルが登場し、Chatbot ArenaでGPT-4oやClaude-3.5を抜いてテキストとマルチモーダルの両方で1位のスコアを獲得しました。
動画生成AIでは、中国から「Vidu」がリリースされました。画像1枚から4秒または8秒の動画が作成でき、無料と有料サブスクリプションが用意されています。
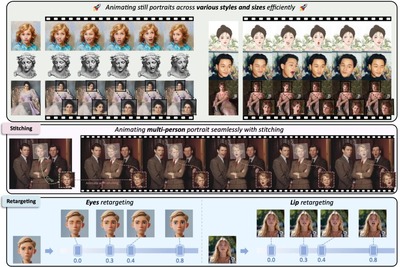
以前この連載で取り上げた、静止画や動画内のキャラクターの表情や頭部を自在に動かせる「LivePortrait」の動物版がアップデートしました。さまざまな動物 (主に猫と犬) で微調整され、人間の表情に合わせて多様な動物の表情を制御することができます。
さて、この1週間の気になる生成AI技術をピックアップして解説する「生成AIウィークリー」(第58回)では、先日OpenAIが発表した「SearchGPT」など、Webのタイムリーな情報と大規模言語モデルを組みわせた検索AIのオープンソースモデル「MindSearch」や、Stability AIが発表した、単一の入力画像から3Dメッシュを0.5秒で生成する「Stable Fast 3D」を取り上げます。
また、Meta AIの動画内の指定したオブジェクトだけを追従して切り抜く「SAM」の進化版「SAM 2」や、Stable Diffusionの開発チームが新しく創設した「Black Forest Labs」による画像生成AIモデル「FLUX.1」をご紹介します。
生成AI論文ピックアップ
オープンソースな大規模言語モデルベースの検索エンジン「MindSearch」。Perplexity.ai Proと同等のパフォーマンス>
Stable Diffusion開発チームの新会社「Black Forest Labs」による画像生成AI「FLUX.1」
オープンソースな大規模言語モデルベースの検索エンジン「MindSearch」。Perplexity.ai Proと同等のパフォーマンス
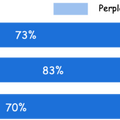
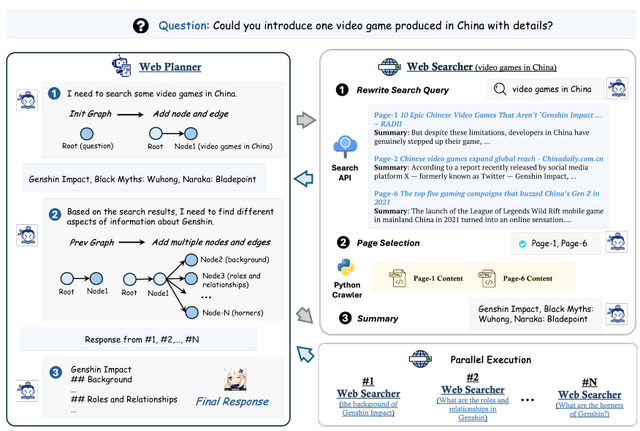
MindSearchは、Perplexity.ai ProやSearchGPTに似た、大規模言語モデル(LLM)ベースの ウェブ検索エンジンです。
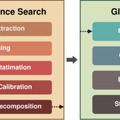
WebPlannerとWebSearcherという2つの主要コンポーネントで構成されています。WebPlannerは、ユーザーの質問を部分的な検索タスクに分解し、検索結果に基づいて次のステップを決定します。この過程は、グラフ構造を用いて表現されます。一方、WebSearcherは階層的な情報検索を行い、関連情報を収集します。
MindSearchの特徴は、複雑な質問を効果的に分解し、大量のウェブページから関連情報を効率的に抽出できる点にあります。また、マルチエージェント設計により、3分以内に300以上のウェブページから並列的に情報を探索・統合することができます。これは人間の専門家が同様の認知作業を行うのに約3時間かかる規模です。
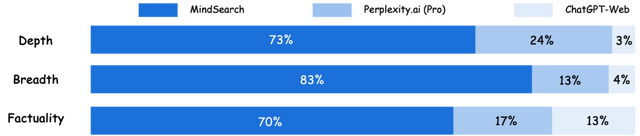
研究チームは、GPT-4oやInternLM2.5-7Bなどのモデルを用いて、クローズセットとオープンセットの両方の質問応答タスクでMindSearchの性能を評価した結果、既存のシステムと比較して、回答の質が大幅に向上したことを示しています。また、オープンソースモデルであるInternLM2.5-7Bを基にしたMindSearchの回答が、ChatGPT-Web(GPT-4oベース)やPerplexity.aiのProバージョンよりも好まれました。

MindSearch: Mimicking Human Minds Elicits Deep AI Searcher
Zehui Chen, Kuikun Liu, Qiuchen Wang, Jiangning Liu, Wenwei Zhang, Kai Chen, Feng Zhao
Project | Paper | GitHub
より速く、より正確に写真から立体の世界を作り出す3D空間再構築技術「GLOMAP」
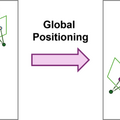
Structure-from-Motion(SfM)は、複数の画像から3D構造とカメラの動きを復元する技術です。従来のグローバルアプローチは全ての画像を一度に処理するため効率的ですが、精度と堅牢性が劣っていました。
この研究では、グローバルアプローチの問題を再考察し、「GLOMAP」という新しいシステムを提案しています。GLOMAPの主な特徴は、従来別々に行われていたカメラの位置を推定する処理と三角測量のステップを、単一のグローバル位置推定ステップに統合したことです。これにより、カメラ位置と3D点の位置を同時に推定することができます。
研究チームは、ETH3D、LaMAR、Image Matching Challenge 2023、MIP360などの様々なデータセットでGLOMAPを評価しました。その結果、GLOMAPは他のSfMシステム(最先端のCOLMAPなど)と同等かそれ以上の精度と堅牢性を達成しました。特筆すべきは、GLOMAPがCOLMAPよりも数倍から数十倍高速に動作することです。
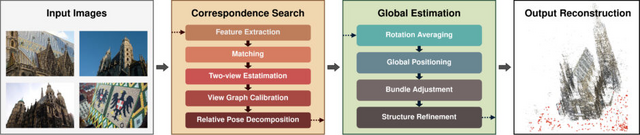
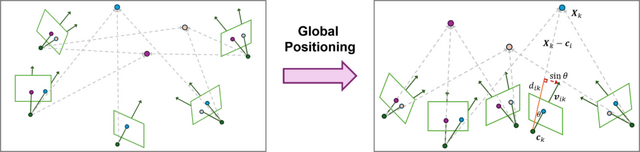

Global Structure-from-Motion Revisited
Linfei Pan, Dániel Baráth, Marc Pollefeys, Johannes L. Schönberger
Project | Paper | GitHub
映像内の物体を追跡し切り抜く画像セグメンテーションモデル「SAM 2」をMeta AIが発表
Meta AIの研究チームが、画像と動画の両方に対応する新しい物体セグメンテーションモデル「SAM 2」(Segment Anything Model 2)を発表しました。これは、去年発表のモデル「SAM」の後継版で、より高性能かつ汎用性の高いモデルとなっています。
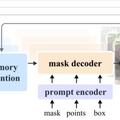
SAM 2は、単一のモデルで画像と動画のセグメンテーションを行えます。ユーザーはクリック、バウンディングボックス、マスクなどのプロンプトを使って、切り抜きたい対象を自由に指定できます。指定した対象が動いても追跡し、切り抜くことができます。
動画をフレームごとに処理し、過去のフレーム情報を記憶する仕組みを持つことで、長時間の動画でも効率的に物体を追跡できます。モデルの構造は、ストリーミングアーキテクチャを採用しており、リアルタイムに物体を切り抜くことができます。また、学習データにない未知なる物体に対しても対応できるゼロショットを備えています。
SAM 2の開発には、新たに作成された大規模データセット「SA-V」が使用されました。SA-Vは約5万本の動画と約64万のマスク(動画内の物体のマスク)を含み、既存の最大データセットの53倍もの規模を誇ります。この豊富なデータにより、モデルの汎用性と精度が大幅に向上しました。
性能面では、SAM 2は画像セグメンテーションタスクでSAMを上回る精度を達成し、処理速度も6倍に向上しました。動画セグメンテーションでは、従来手法と比べて3分の1以下の操作で、より高精度なセグメンテーションを実現しています。
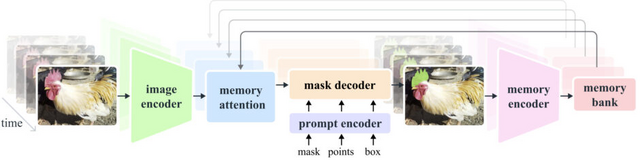
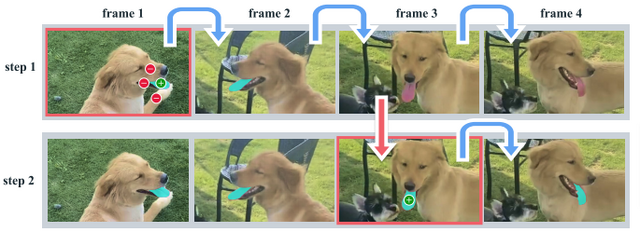

SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, Christoph Feichtenhofer
Project | Paper | GitHub | Blog
Stability AI、1枚の画像から3Dモデルを0.5秒で生成する「Stable Fast 3D」発表
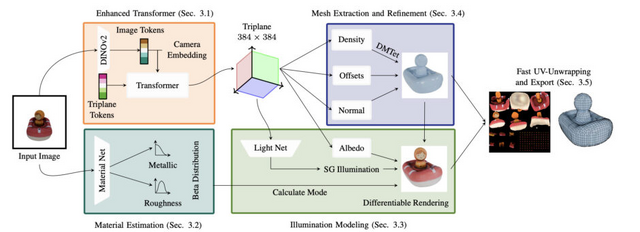
Stability AIは、単一の2D画像から高品質な3Dメッシュを生成する「Stable Fast 3D」(SF3D)を開発しました。SF3Dは、単一の画像から高品質な3Dメッシュを0.5秒という短時間で生成することができます。
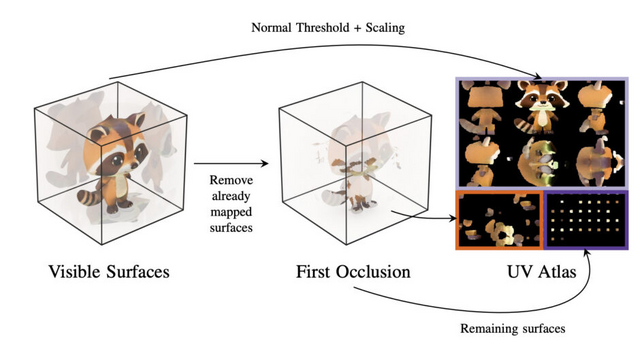
SF3Dは、球面ガウス関数(SG)を用いて照明を予測し、照明効果を分離する能力を持っています。これにより、入力画像に含まれる影や照明の影響を取り除き、より汎用的な3Dモデルを生成することができます。また、高速なボックス投影ベースのUV展開技術を導入し、より効率的なテクスチャ生成を実現しています。
さらに、SF3Dは滑らかなメッシュ表面を生成する能力も向上しています。従来の手法では、階段状のアーティファクトが発生しがちでしたが、SF3Dでは、より効率的なアーキテクチャを採用し、DMTet(Deep Marching Tetrahedra)と学習された頂点変位および法線マップを使用することで、これらの問題を軽減しています。
加えて、SF3Dは物体の空間的に変化しない材質特性も予測することができます。これにより、生成された3Dモデルは異なる照明条件下でもリアルな見た目を保つことができます。
研究チームは、SF3Dの性能を評価するために、Google Scanned Objects(GSO)とOmniObject3Dという2つのデータセットを使用しました。実験結果、SF3Dが既存の手法と比較して、形状の正確さと視覚的品質の両面で優れた性能を示しました。
生成されたメッシュは、細かいディテールや滑らかな表面を持ち、他の手法で見られるようなアーティファクトが少ないことが確認されました。また他の手法と比べてポリゴン数が少ないにもかかわらず、高い形状の正確さを達成しています。生成速度も多くの比較対象が1秒から64秒を要するのに対し、SF3Dは0.5秒という非常に短い時間で3Dメッシュを生成することができました。


SF3D: Stable Fast 3D Mesh Reconstruction with UV-unwrapping and Illumination Disentanglement
Mark Boss, Zixuan Huang, Aaryaman Vasishta, Varun Jampani
Project | Paper | GitHub | Demo
Stable Diffusion開発チームの新会社「Black Forest Labs」による画像生成AI「FLUX.1」
Stable Diffusionの開発者たちが新たに「Black Forest Labs」というAI会社を立ち上げました。この研究チームの開発履歴には、VQGANやLatent Diffusion、Stable Diffusionモデル群、リアルタイム画像生成のためのAdversarial Diffusion Distillationなどが含まれます。
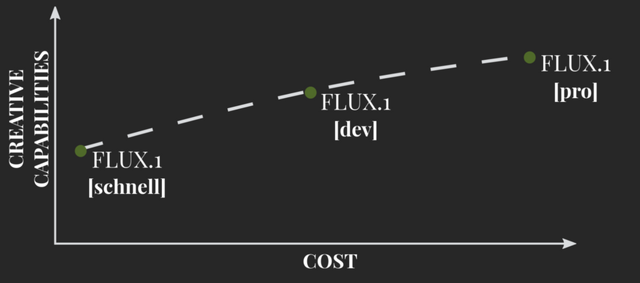
そんなBlack Forest Labsがテキストから画像を生成する120億パラメータのモデル「FLUX.1」をリリースしました。FLUX.1は、様々なニーズに対応するため、3つのバリエーションで提供されています。最高性能を誇るFLUX.1 [pro]、オープンウェイトで非商用利用向けのFLUX.1 [dev]、そして最速で個人利用に適したFLUX.1 [schnell]です。
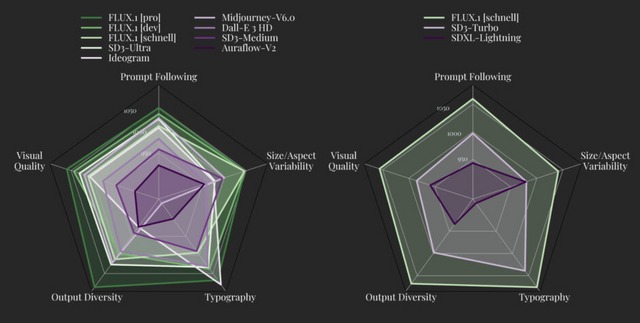
FLUX.1 [pro]は、最高品質の画像生成を提供し、プロンプトへの追従性、視覚的品質、画像の詳細さ、出力の多様性において最高水準の性能を発揮します。APIを通じてアクセスでき、ReplicateやFal.aiでも利用可能です。企業向けのカスタマイズソリューションも提供されています。
FLUX.1 [dev]は、FLUX.1 [pro]から蒸留された非商用アプリケーション向けのモデルです。同じサイズの標準モデルよりも効率的でありながら、[pro]に近い品質とプロンプト追従能力を実現しています。HuggingFaceで重みが公開されており、ReplicateやFal.aiで試すことができます。
FLUX.1 [schnell]は、ローカル開発や個人利用に適した最速のモデルです。Apache2.0ライセンスで公開されており、HuggingFaceで重みが入手可能で、GitHubやHuggingFaceのDiffusersでコードを見ることができます。ComfyUIとの統合も実現しています。
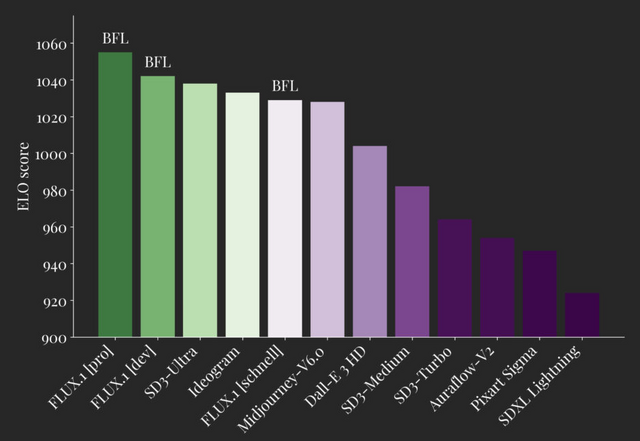
FLUX.1は、画像合成の新しいベンチマークを設定しています。FLUX.1 [pro]と[dev]は、Midjourney v6.0、DALLE 3 (HD)、SD3-Ultraなどの人気モデルを、視覚的品質、プロンプト追従性、サイズ/アスペクト比の可変性、タイポグラフィ、出力の多様性のそれぞれの面で上回っています。FLUX.1 [schnell]は、同クラスの競合モデルだけでなく、Midjourney v6.0やDALL-E 3(HD)をも凌駕します。
次の展開として、テキストから動画を生成するモデルもリリース予定としています。





FLUX
Andreas Blattmann, Andi Holmes, Axel Sauer, Dominik Lorenz, Dustin Podell, Frederic Boesel, Harry Saini, Jonas Müller, Kyle Lacey, Patrick Esser, Robin Rombach, Sumith Kulal, Tim Dockhorn, Yam Levi, Zion English
Project | GitHub | Blog














![[BURTLE] [バートル] カラーファン+24Vバッテリーセット AC09+AC09-1 エアークラフト AIRCRAFT 京セラ製 2025年モデル バッテリーのカラー:78マットブラック/ファンのカラー:35ブラック image](https://m.media-amazon.com/images/I/41PCWQZJUkL._SL160_.jpg)
![スティング [DVD] image](https://m.media-amazon.com/images/I/51l9NN4g5yL._SL160_.jpg)

![SHINee DVD [Blu-ray] The Trilogy I 2026 SHINee WORLD VIII : [THE INVERT] (26.05.30) 日本語字幕/シャイニー [並行輸入品] image](https://m.media-amazon.com/images/I/61PNBMbY5wL._SL160_.jpg)




![[機能性表示食品] サントリー烏龍茶 2L×9本 [Amazon限定ブランド] まとめ売り実施中 image](https://m.media-amazon.com/images/I/419bofWXTvL._SL160_.jpg)