









動画生成AIのKLING AIがアップデートし、「Kling AI v1.5」をリリースしました。1080p解像度への対応など性能が向上しました。新機能として、画像内の物体をマスクし、手書きのスケッチで動きをナビゲートすることで、希望する動きを直感的かつ大まかに指定できるようになりました。
Qwenチームは、オープンソースの言語モデルファミリー「Qwen2.5」を発表しました。0.5B~72Bの幅広いサイズが含まれ、一般的な言語モデルのQwen2.5、コーディング専用のQwen2.5-Coder、そして数学に特化したQwen2.5-Mathが用意されています。
NVIDIAは、マルチモーダル大規模言語モデルファミリー「NVLM 1.0」を発表しました。GPT-4oやLlama 3-V 405Bなどのモデルと肩を並べる性能を示しています。
さて、この1週間の気になる生成AI技術・研究をピックアップして解説する「生成AIウィークリー」(第65回)では、対話スピードや会話中の割り込みの自然さなど、人間と話しているかのような会話ができるモデル「Moshi」や、ByteDanceが開発した音楽生成・編集モデル「Seed-Music」を取り上げます。また、単一フレームワークでさまざまな画像編集が可能な「OmniGen」や、新しいEmbeddingモデル「jina-embeddings-v3」をご紹介します。
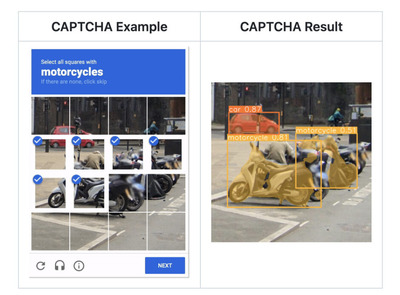
そして、生成AIウィークリーの中でも、特に興味深い技術や研究にスポットライトを当てる「生成AIクローズアップ」では、「私はロボットではありません」でお馴染みのGoogleが開発する「reCAPTCHAv2」システムを100%の精度で突破するAIシステムを提案した研究を単体で掘り下げます。
人間のように会話するオープンソースの対話AI「Moshi」、低遅延で人間同士の会話に近い速さを実現
AlexaやSiri、Google Assistantなどの音声対話システムは、中間モダリティがテキストであるため、対話間に数秒の遅延が生じます。また、感情や非音声音などの意味を変える非言語情報が対話の中で失われてしまいます。
「Moshi」は、対話を音声から音声への生成としてモデル化することで、これらの問題を解決します。Moshiは、Kyutai Labsによって開発された、7Bパラメータの会話AIモデルです。
結果として得られたモデルは、理論上160ミリ秒、実際には200ミリ秒の遅延で、リアルタイムの会話を実現します。これは人間同士で話す会話スピードに近い速さです。
さらに、音声を直接処理するので、非言語情報も理解します。従来のシステムは「ユーザーが話す→システムが応答する」という固定的なやり取りでしたが、Moshiは人間の話に割り込んだり、同時に話したりすることができ、より自然な対話を実現します。また、周囲のノイズがある環境でも適切に処理できる特徴を持っています。(下記添付のXで工事現場での実演を確認できます)
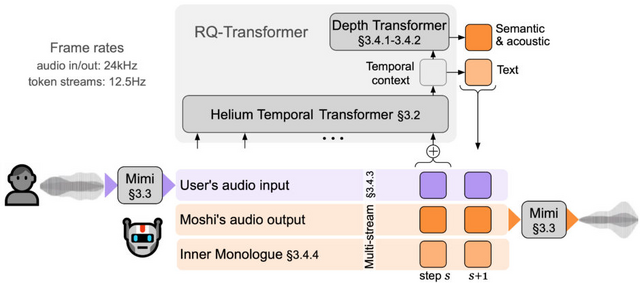
Moshiは、大きく分けて3つの主要な要素から構成されています。まず、「Helium」と呼ばれる大規模言語モデル(LLM)があります。これは約7Bパラメータを持つテキストベースのモデルで、2.1兆トークンの英語データで事前学習されています。Heliumは、Moshiの中核となる言語理解と生成の能力を担っています。
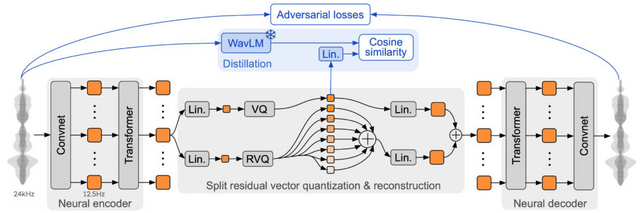
次に、「Mimi」という名前のニューラルオーディオコーデックがあります。Mimiは音声を離散的なトークン(音声単位)に変換し、また逆にトークンから音声を再構成する役割を果たします。そして、これらを組み合わせて機能させるのがMoshiアーキテクチャです。MoshiはHeliumとより小さなTransformerモデルを組み合わせて、階層的かつストリーミング方式で音声トークンを予測します。
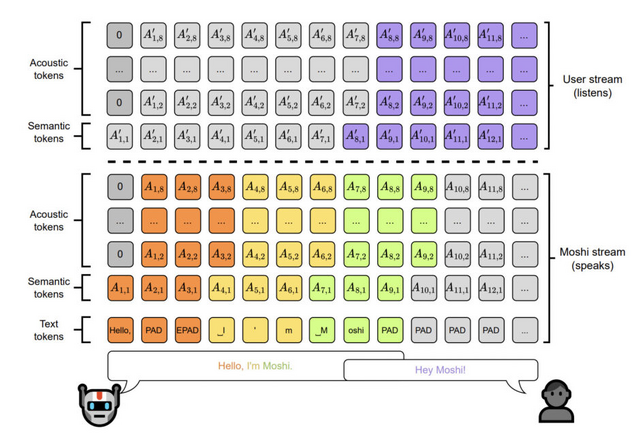
Moshiの特筆すべき機能の一つが「Inner Monologue」です。これは、音声トークンを予測する前に、時間に沿ったテキストトークンを予測するという新しい手法です。この方法により、生成される音声の事実性と言語的品質が大幅に向上します。
実験結果では、Moshiが既存の音声テキストモデルと比較して、音声モデリングと音声による質問応答の両面で最先端の性能を示しました。特に、ストリーミング互換性を持ちながら高い性能を達成し、5分間の長い文脈を適切に処理できることが確認されています。
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Defossez, Laurent Mazare, Manu Orsini, Amelie Royer, Patrick Perez, Herve Jegou, Edouard Grave, Neil Zeghidour
Paper | GitHub | Demo | Hugging Face
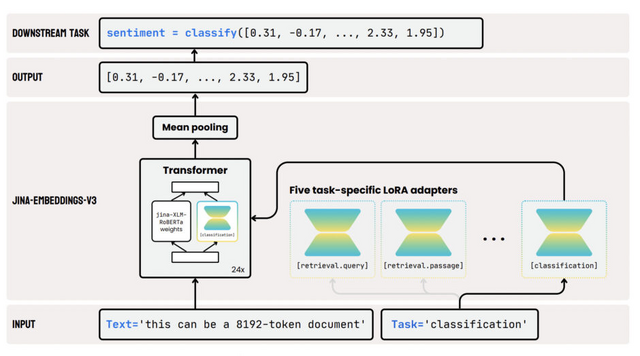
5億7000万パラメータと最大8192トークンのEmbeddingモデル「jina-embeddings-v3」
Jina AIは、5億7000万パラメータを持つ多言語テキストEmbeddingモデル「jina-embeddings-v3」を発表しました。このモデルは、最大8192トークンの入力長をサポートし、文書検索、クラスタリング、分類、テキストマッチングなどのタスクに対応するLoRAアダプターを備えています。
MTEBベンチマークの評価では、jina-embeddings-v3はOpenAIやCohereなどの最新のEmbeddingモデルを英語タスクで上回り、多言語タスクでもmultilingual-e5-large-instructを凌駕しています。
また、GoogleのMatryoshka Representation Learningの統合により、ユーザーはパフォーマンスを損なうことなく埋め込みの次元を32まで任意に削減できます。これにより、ユーザーは埋め込みの次元とパフォーマンスのバランスを取ることが可能になります。
jina-embeddings-v3は、10億パラメータ未満のモデルの中で最高のMTEB英語スコアを達成し、多言語モデルとしても最高の性能を示しています。このモデルは幅広い言語をサポートし、多くの言語で高いパフォーマンスを発揮します。

jina-embeddings-v3: Multilingual Embeddings With Task LoRA
Saba Sturua, Isabelle Mohr, Mohammad Kalim Akram, Michael Günther, Bo Wang, Markus Krimmel, Feng Wang, Georgios Mastrapas, Andreas Koukounas, Nan Wang, Han Xiao
Paper | Hugging Face | Blog
画像生成から視覚認識まで複数のタスクをこなす統合型画像生成AI「OmniGen」
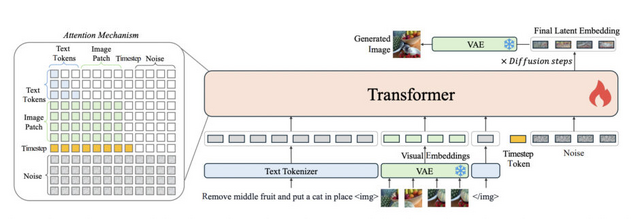
「OmniGen」は、テキストから画像を生成する能力に加え、画像編集、被写体主導の生成、視覚条件付き生成など、幅広いタスクを単一のフレームワーク内でサポートする統合型画像生成AIモデルです。
このモデルは多様な画像処理タスクを実行できます。例えば、画像中の特定の物体を削除したり、色を変更したり、新しい要素を追加したりする画像編集が可能です。また、参照画像から特定の対象物を抽出し、新しい画像の中にその対象物を組み込んで生成することもできます。
さらに、OmniGenは従来のコンピュータビジョンタスクも処理できます。エッジ検出や人間のポーズ認識などの古典的なタスクに加え、ぼやけた画像をクリアにする、画像から雨の効果を除去する、インペインティング(画像の欠損部分を補完する)、低光量画像の強化などのタスクも画像生成タスクとして実行することができます。
OmniGenの構造は、VAE(Variational Autoencoder)と事前学習された大規模トランスフォーマーモデルから構成されています。3.8Bのパラメータを持つこのモデルは、複雑なタスクを自然言語による指示で完了することができ、ユーザーにとって使いやすいモデルとなっています。
注目すべきは、OmniGenが推論能力や少数ショット学習能力も示していることです。また、Chain of Thought(CoT)のような方法を使用して段階的に画像を生成することもできます。興味深いことに、OmniGenは他の最先端モデルと比較して少ない0.1Bの画像データで訓練されているにもかかわらず、高い性能を示しています。








OmniGen: Unified Image Generation
Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xingrun Xing, Ruiran Yan, Shuting Wang, Tiejun Huang, Zheng Liu
Paper | GitHub
ユーザーの話し声(10秒)を既存楽曲のボーカルに変換できる音楽生成・編集モデル「Seed-Music」をByteDanceが開発
「Seed-Music」という新しい音楽生成・編集システムをご紹介します。このシステムは、高品質な音楽を生成し、きめ細かいスタイル制御を可能にする技術を統合したフレームワークです。
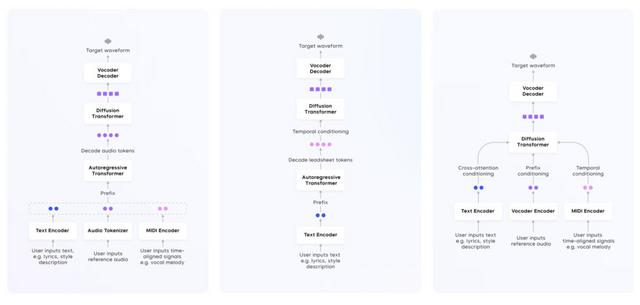
Seed-Musicは、制御された音楽生成と後編集という2つの主要な音楽制作ワークフローをサポートしています。音楽生成においては、歌詞、スタイルの説明、オーディオ参照、楽譜、声のプロンプトなど、複数のモダリティからの入力を用いてボーカル音楽を生成できます。
後編集では、既存の音楽トラック内で歌詞、メロディ、音色などを直接編集することができます。例えば、曲の一部の歌詞を変更したり、メロディラインを調整したりすることが可能です。
このシステムは、自己回帰モデルと拡散アプローチの両方を活用した統一フレームワークを採用しています。これにより、多様な入力条件に基づいた高品質な音声音楽生成が実現しています。
さらに、Seed-Musicには新しい歌声変換技術が組み込まれています。この技術は、ユーザーが10秒程度の音声サンプル(歌声でも通常の話し声でも可)を提供するだけで、既存の楽曲の歌声をユーザーの声質に変換できます。これにより、誰でも自分の声で歌っているような音楽を簡単に作れるようになりました。

Seed-Music: A Unified Framework for High Quality and Controlled Music Generation
Ye Bai, Haonan Chen, Jitong Chen, Zhuo Chen, Yi Deng, Xiaohong Dong, Lamtharn Hantrakul, Weituo Hao, Qingqing Huang, Zhongyi Huang, Dongya Jia, Feihu La, Duc Le, Bochen Li, Chumin Li, Hui Li, Xingxing Li, Shouda Liu, Wei-Tsung Lu, Yiqing Lu, Andrew Shaw, Janne Spijkervet, Yakun Sun, Bo Wang, Ju-Chiang Wang, Yuping Wang, Yuxuan Wang, Ling Xu, Yifeng Yang, Chao Yao, Shuo Zhang, Yang Zhang, Yilin Zhang, Hang Zhao, Ziyi Zhao, Dejian Zhong, Shicen Zhou, Pei Zou
Project | Paper





