








生成AIグラビアをグラビアカメラマンが作るとどうなる? 記事一覧
■ FLUX.1登場から約2ヶ月経った現状
8月1日にいきなり登場したFLUX.1 [pro][dev][schnell]。約2ヶ月経った今ではすっかり主流になった感じで、各方面FLUX.1だらけとなっている。
ただ[dev]だとRTX 4090を使っても832x1216の画像が8秒ちょっと/枚と結構重い処理。久々にSD 1.5やSDXLを生成するとその速さにビックリする(笑)。それでもFLUX.1 [dev]を使い続けるのはやはり画質が良いからに他ならない。

小ネタの連打になるが、今回はこの約2ヶ月で得たいろいろな情報を筆者XアカウントのPostを眺めつつまとめてみたい。
まずCheckpointだが、 MergeタイプとTrainedタイプ、2種類ある中、圧倒的に多いのはMergeタイプだ。これはベースとなる flux1-dev.safetensors にLoRAなどをブレンドして作ることもありやり易いのだろう。Trainedタイプは学習させるため時間がかかり数える程しかあがっていない。ただ執筆時点で[dev]を超えるCheckpointは(確認した範囲では)残念ながらまだ無い感じだ。
LoRAに関しては当初、高速化やエフェクトなど拡張型がいくつか出たが、その後は肖像権大丈夫なの?的な顔LoRAとNSFW対応が山盛りcivitaiに載っている。まぁcivitaiはSD 1.5の頃からそうなので今に始まった話ではない。が、それも最近一時期よりは登録数が減ってきている。出尽くした!?(笑)。
■ unetタイプCheckpointを全部入りfp8に変える方法
Checkpointは大きく分けてunetタイプとclip/t5/vae全部入りタイプと2種類ある。ComfyUIのWorkflow的にはこんな感じだ。
前者の利点はcheckpoint/clip/t5/vae全てファイルが分かれているので、絵柄を変えるのはcheckpointだけ入れ替えればよく、容量的な効率が良い。またclip/t5/vaeは固定なので、Checkpointを変えた時、動き出すのも速いだろう。
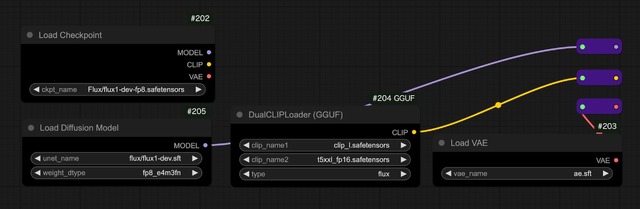
対して全部入りは、ご覧のようにnode一つでWorkflow的にスッキリで簡単。またファイル1本で完結するので扱いも楽だ。欠点としては、ファイルにclip/t5/vaeを抱えるため、その分、ファイルサイズは大きくなる。例えばunetタイプは約11GB、全部入りタイプは約17GBとなる(fp8)。
とは言え、この2つが混在すると、どちらを使うかで上記のようにWorkflowが変わるため、出来ればよく使うものだけでも全部入り、そしてfp8にまとめたい。fp8はfp16と比較して精度は劣るものの、画像の場合、ちょっと変わる程度。ファイル容量が半分近くなるのでストレージが助かる。
unet fp16から全部入りfp8変換のWorkflowは以下の様になる。custom_nodesは ComfyUI_DiffusionModel_fp8_converter を追加しておく。
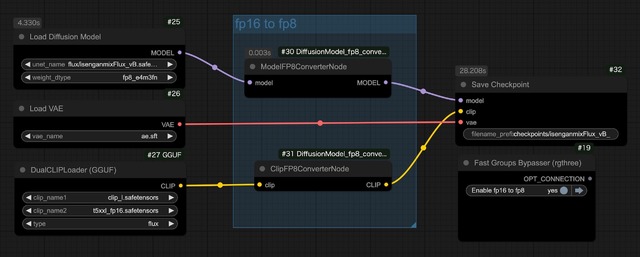
fp8にはせず、fp16のまま全部入りにする場合は、真ん中2つのnodeをbypassすれば良い。但しファイルサイズは22GBほどに。出来たCheckpointはComfyUI/outputフォルダに入っている。
なお、fp8変換手前にLoad LoRAを入れれば、LoRAも一緒にマージ出来る。結構簡単なのでいろいろ試して欲しい。
■ flux1-dev2pro.safetensors登場!
一瞬[pro]がオープンに!?と勘違いしそうだが、それは違う。もちろんcheckpointの一種なので生成は可能なのだが、[dev]と比較して、ちょとテイストの異なる絵が出るだけで、優っているわけではない。
では何に使うのか?と言うと学習用だ。学習する時に flux1-dev.safetensors を使わず flux1-dev2pro.safetensors を使う。英文だが ここ によると、そもそも[dev]は[pro]の蒸留モデルであり、これでLoRAなどを作っても良い結果が得られず、本来であれば[pro]で学習すべき…的な内容が書かれている。
とは言え[pro]はAPI使用のみでオープンにはなっておらず、学習ベースには使えない。そこで、擬似的に[pro]を作ったのが、この flux1-dev2pro.safetensors となる。
以下2つが、 flux1-dev2pro.safetensors ベースで学習したLoRAで生成した画像(左)と、 flux1-dev.safetensors ベースで学習したLoRAで生成した画像(右)の比較だ。もちろんdatasetは同じ、生成時のパラメータも同じだ。
 |  |
flux1-dev2pro.safetensors ベースで学習したLoRA使用
flux1-dev.safetensors ベースで学習したLoRA使用
基本顔LoRAなので似てる似ていないの判断もあるが、背景がまるで違う。Promptに忠実なのは flux1-dev2pro.safetensors ベースで学習したLoRAとなる。
何枚かガチャっても結果は同じ。flux1-dev.safetensors ベースで学習したLoRAだと背景がグレーバックになることがほとんどだった。本来[pro]で学習すべき…とは、こう言う意味かも知れない。
■ ピンボケ対策
FLUX.1 [dev]で画像を生成しているとたまにピンボケが出てくることがある。運?が悪いと何度ガチャっても結構な率で発生したりする。これへの対策は、
focus on the eyes をPromptに追加
Guidance Scaleを3.5未満にする
Step数を増やす
以上の様になる。1は何処にピントを合わすのか迷い結果ピンボケになるケース。シンプルな背景で且つ、顔LoRA無しの時にたまに出る。
 |  |
 |  |
ピンボケ
focus on the eyes 追加
Guidance Scale 2.5
40 Steps
2と3は力技(笑)。Guidance Scaleはあまり小さくすると画質に影響するため2.5までだろうか。Step数を増やすのは確実な対応方法だが、その分、生成時間が長くなる。どれで行くかはケースバイケースだろう。
■ カラフルな世界の名所を背景に
ここまでは技術的な話だが、ここではFLUX.1 [dev]が学習している女性以外(笑)の話を。"カラフルな世界の名所"で検索すると、Cinque Terre(チンクェ・テッレ)やBurano(ブラノ島)などが出てくる。これをまんまPromptへ入れるとこうなる。
 |  |
realistic photograph of the Cinque Terre
realistic photograph of the Burano
いかがだろうか?旅行へ行き、そこで撮ったような画像が生成される。ここに美女を立たすのもまた一興(扉参照)。いろいろな場所が入っているので是非試して欲しい。
■ 今回締めのグラビア
今回の締めのグラビアは、前回のコラボ企画、後半の偽ゲームショウ2024ネタの続編?となる。あの記事後、”周囲をカメラで撮影する大勢の男性”にして撮影会状態にすれば面白そう…っと思いながら作ったところ結構いけたので掲載する(笑)。


Checkpointは、今朝(9/30)出たばかりの Realistic DeepDream FLUX 。[dev]版と[schnell]版があり、[dev]版を使っている。
出力は2MPで1152x1728ピクセル。ありがちなJapanese womanとは違う系統の顔が出る(上記画像は顔LoRA無し)。ちょっと面白そうなのでこれからいろいろ試してみたい。


![生成AIグラビアをグラビアカメラマンが作るとどうなる?第31回:新型ForgeでFLUX.1 [dev] fp8を生成する(西川和久) 画像](/imgs/p/KS0xA70UphpJ5g7PcXQyhA2bwJXOlZSTkpGQ/18723.jpg)
![生成AIグラビアをグラビアカメラマンが作るとどうなる?第30回:生成AI画像の本命がいきなり登場!?新型モデルFLUX.1 [dev]を使ってみる(西川和久) 画像](/imgs/p/KS0xA70UphpJ5g7PcXQyhA2bwJXOlZSTkpGQ/18531.jpg)