




Metaがさまざまな研究成果を公開しました。画像や動画内のオブジェクトを切り抜けるセグメンテーションモデル「SAM 2」の更新版「SAM 2.1」や、テキストと音声を自由に組み合わせるマルチモーダル言語モデル「Spirit LM」、大規模言語モデル(LLM)の生成時間を加速させる「Layer Skip」などが含まれています。
また、ファインチューニングなしで、ゼロショットで音声変換できるボイスチェンジシステム「Seed-VC」が話題になりました。1~30秒の参照スピーチを与えることでリアルな音声に変換します。
さて、この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第68回)では、テキストを読み上げるTTSシステム「F5-TTS」や、会話AIモデル「Ichigo」を取り上げます。また、単一CPUでLLMで実行できる、Microsoftの1ビットLLM推論フレームワーク「bitnet.cpp 1.0」などをご紹介します。
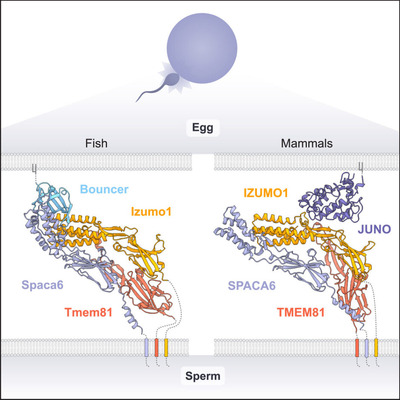
そして、生成AIウィークリーの中でも特に興味深い技術や研究にスポットライトを当てる「生成AIクローズアップ」では、今年のノーベル化学賞を受賞した2人が開発に貢献したタンパク質構造AI予測ツール「AlphaFold」シリーズによって、精子と卵子の結合メカニズムを明らかにした研究を単体で掘り下げました。
■テキストから流暢かつ忠実な音声を生成するTTSシステム「F5-TTS」
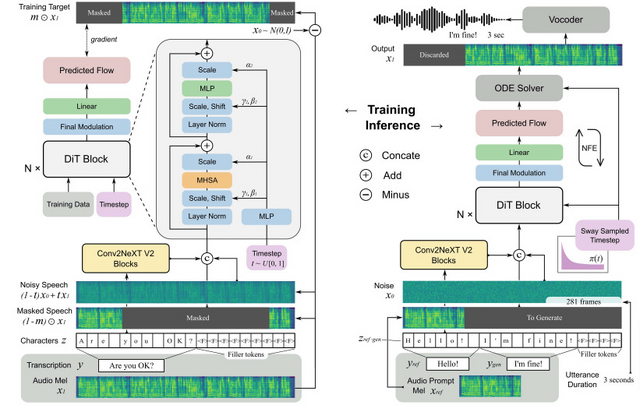
「F5-TTS」は、Diffusion Transformer (DiT) を用いた、テキストから音声を生成するText to Speech(TTS)システムです。このシステムの特徴は、従来の複雑な仕組みを大幅に簡素化していることです。
例えば、音の長さを予測したり、テキストを特殊な形式に変換したりする必要がありません。代わりに、入力されたテキストを直接音声の長さに合わせて調整し、そこから音声を作り出します。
この方法は以前にE2-TTSという別のシステムで試されましたが、学習に時間がかかり、安定性に欠けるという問題がありました。F5-TTSはこの課題を解決するため、ConvNeXtという技術を使ってテキストの理解を深め、音声との調和をより良くしています。さらに、Sway Samplingという新しい方法を導入し、音声生成の質と速度を大幅に向上させました。
F5-TTSの優れた点は、学習と音声生成の両方が高速であることです。特に、音声を1秒生成する速度は0.15秒という、非常に速いスピードを実現しています。
また、F5-TTSは10万時間以上の多言語音声データを使って訓練されており、さまざまな言語で自然な音声を生成できます。
実験結果では、生成された音声の正確さ(単語の誤り率)と、元の話者の声の特徴をどれだけ再現できているか(話者類似度)という点で、既存のシステムを上回る成績を示しています。
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
Yushen Chen, Zhikang Niu, Ziyang Ma, Keqi Deng, Chunhui Wang, Jian Zhao, Kai Yu, Xie Chen
Project | Paper | GitHub
■関連性の高い文書検索を行う、高速な検索拡張生成(RAG)システム「LightRAG」
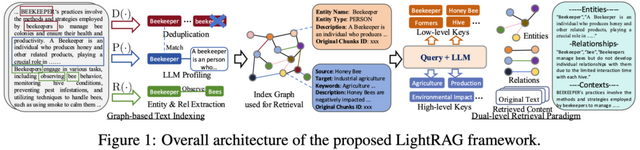
LightRAGは、LLMの性能を外部知識源と統合することで向上させる、高速な検索拡張生成(RAG)システムです。従来のRAGシステムが抱えていた単純化されたデータ構造や不十分な文脈認識という課題を克服するため、LightRAGはグラフ構造を巧みに活用しています。これにより、迅速かつ関連性の高い文書検索を促進し、複雑なクエリのより深い理解を可能にしています。
このシステムの核心は、テキストのインデックス作成と検索プロセスにグラフ理論を応用した点にあります。具体的には、二重レベル検索システムを採用し、低レベルと高レベルの両面から包括的な情報検索を可能にしています。これにより、単なるキーワードマッチングを超えた、意味的に豊かな検索が実現されています。
さらに、LightRAGはグラフ構造とベクトル表現を融合させることで、関連エンティティとその関係性を効率的に把握できます。このアプローチにより、文脈の関連性を損なうことなく応答時間を大幅に短縮することに成功しています。

LightRAG: Simple and Fast Retrieval-Augmented Generation
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, Chao Huang
Project | Paper | GitHub
■人の話を聞き取り、音声で返答するオープンソースのリアルタイム会話AIモデル「Ichigo」
「Ichigo」は、テキストベースのLLMを拡張して会話機能を持たせるための、オープンソースで進行中のプロジェクトです。人間の話す言葉を聞き取って理解し、それに対して音声で返事をすることができます。
以前のバージョンで見られた課題を克服するため、3段階の訓練アプローチを採用しました。第1段階では、7言語音声データを使用して継続的な事前訓練を行い、モデルの多言語能力を向上させました。
第2段階では、元のLLMの性能を回復しつつ、音声モダリティのバランスを取ることに焦点を当てました。第3段階では、聞き取れない入力に対して適切に応答する能力を身につけさせました。
訓練の結果、MMULベンチマークでの性能低下を最小限に抑えつつ、音声理解能力を大幅に向上させることができました。また、AudioBenchという音声LLM評価のベンチマークでも良好な結果を示しています。

■画像内の“擬人化キャラクター”の動きを制御できるAIモデル「Animate-X」
最近の研究では、静止画内のキャラクターを自在に動かすアニメーション技術が注目を集めています。しかし、これまでの手法は主に人間のキャラクターに限定されており、ゲームや娯楽産業で広く使われる擬人化キャラクターへの応用が課題でした。
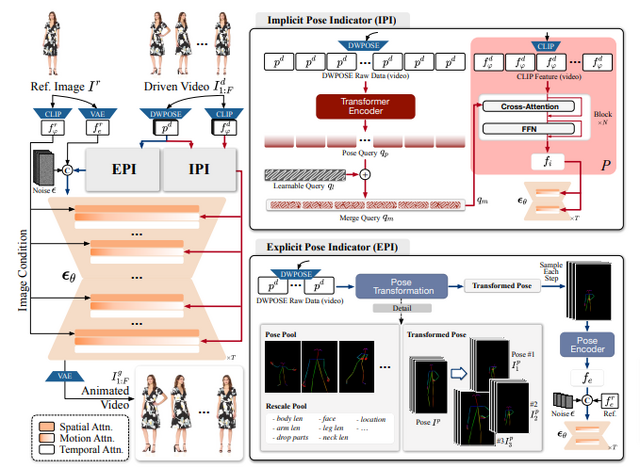
この課題に取り組むため、研究チームは「Animate-X」と呼ばれる新しいフレームワークを開発しました。Animate-Xは、潜在拡散モデル(LDM)を基盤とし、動きの表現を強化するために「Pose Indicator」というモジュールを導入しました。
Pose Indicatorは、Implicit Pose Indicator(IPI)とExplicit Pose Indicator(EPI)の2つの部分から構成されています。IPIはCLIPを使用して動画全体の動きの特徴を暗黙的に抽出し、EPIは明示的に姿勢の変換を行います。これにより、動画から包括的な動きのパターンを捉え、より自然で柔軟なアニメーションが可能になりました。
研究チームはまた、擬人化キャラクターのアニメーション性能を評価するための新しいベンチマーク「A2Bench」を作成しました。A2Benchには500種類の擬人化キャラクターとそれに対応するダンス動画が含まれており、これらはGPT-4とKLING AIを用いて生成されました。
実験の結果、Animate-Xは既存の最先端手法と比較して、キャラクターの個性保持と動きの一貫性の両面で優れた性能を示しました。特に、人間以外の擬人化キャラクターのアニメーション生成において、高い汎用性と頑健性を実現しています。定量的評価と定性的評価の両方で、Animate-Xは他の手法を上回る結果を示しました。


Animate-X: Universal Character Image Animation with Enhanced Motion Representation
Shuai Tan, Biao Gong, Xiang Wang, Shiwei Zhang, Dandan Zheng, Ruobing Zheng, Kecheng Zheng, Jingdong Chen, Ming Yang
Project | Paper
■1000憶パラメータのLLMを“単一CPU”でローカル実行できる、1ビットLLM推論フレームワーク「bitnet.cpp 1.0」をMicrosoftがリリース
マイクロソフトリサーチが1ビットLLM向けのソフトウェアスタック「bitnet.cpp」を発表しました。これは、BitNet b1.58のような1ビットLLMの推論を高速かつ無損失で実行することを可能にするものです。
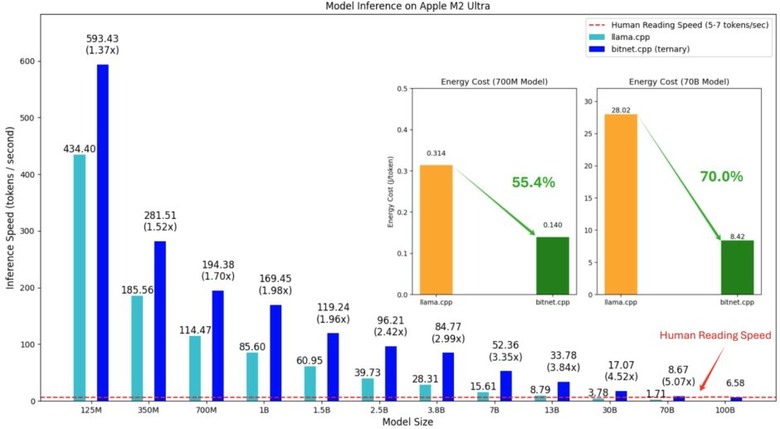
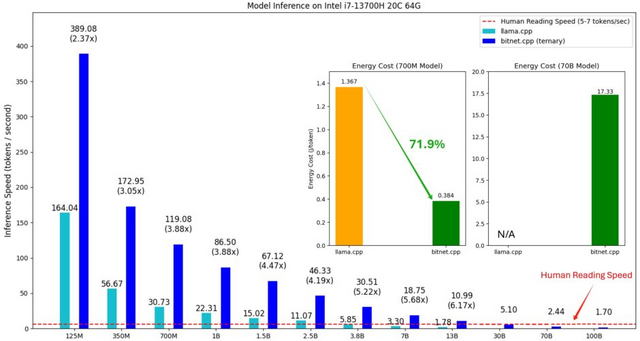
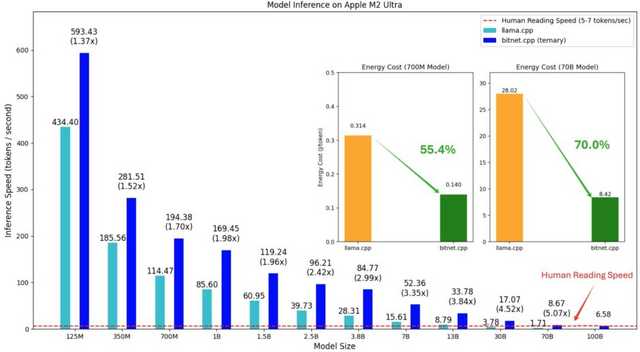
成果として、bitnet.cppは1000億(100B)パラメータモデルを単一のCPU上で実行可能で、Apple M2 Ultra上で最大6.58トークン/秒、Intel i7-13700H上で最大1.70トークン/秒を達成しました。これは人間の読書速度(1秒間に5-7トークン)に相当する処理速度です。
性能面では、Armプロセッサ上で1.37倍から5.07倍、x86プロセッサ上で2.37倍から6.17倍の高速化を実現しています。消費電力についても改善が見られ、Armプロセッサでは55.4%から70.0%、x86プロセッサでは71.9%から82.2%の削減を達成しました。
bitnet.cppは、I2_S、TL1、TL2という3種類の最適化されたカーネルを提供しています。
推論の精度に関しては、WildChatから無作為に選択された1000個のプロンプトを用いた評価において、bitnet.cppの全てのカーネルが32ビット浮動小数点演算と同等の100%の精度を達成しました。これは、量子化による精度低下なしに高速な推論が可能であることを示しています。
今後の展開として、研究チームはiPhoneやAndroidなどのモバイルデバイス、NPU、GPUへのサポート拡大を計画しています。
Llama-3-8B-Instructを基盤に、bitnet 1.58bをファインチューニングしたモデル「Llama3-8B-1.58-100B-tokens」が利用可能です。


1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs
Jinheng Wang, Hansong Zhou, Ting Song, Shaoguang Mao, Shuming Ma, Hongyu Wang, Yan Xia, Furu Wei
Paper | GitHub