



Anthropicが「Claude 3.5」のアップデートを発表しました。「Claude 3.5 Sonnet」の名前は変わらず改善という形で更新し、「Claude 3 Haiku」は「Claude 3.5 Haiku」にアップデートしました。Claude 3.5 Sonnetは特にコーディング分野が向上し、Claude 3 Haikuは前バージョンの最高レベルClaude 3 Opusと同等性能に格上げされました。また、人間のようにPC画面のカーソルを移動させクリックさせたりできる機能「Computer Use」も追加で更新しました。
Google DeepMindが言語生成AIで生成した文章を識別するための電子透かし(ウォーターマーク)技術「SynthID Text」を発表しました。人には見えない電子透かしを文章に直接埋め込むことで、その文章がAIによって生成されたものかどうかを判別します。
さらに、DeepMindは新しい生成AI音楽ツールを発表しました。今回発表されたのは、テキストプロンプトを用いて新しい音楽をリアルタイムで生成する「MusicFX DJ」の新バージョン、マルチトラックビューやループ生成、音声変換、インペインティングなどの機能を備えた「Music AI Sandbox」のアップデート、そしてYouTube Shortsのための新しいAI音楽技術です。
Stability AIが画像生成AI「Stable Diffusion 3.5」を公開しました。Large(80億パラメータ、1メガピクセルの解像度で生成)、Large Turbo(Largeモデルの圧縮版)、Medium(25億パラメータ、0.25から2メガピクセルの解像度で生成)の3種類になります。
さて、この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第69回)では、顔の静止画を音声駆動でアニメーション化するオープンソースのリップシンク生成AI「Hallo2」や、マイクロソフトが開発するAIが画面操作する「OmniParser」をご紹介します。また、オープンソースな動画生成AIを2つ、商用利用可能な「Allegro」と、2,840万ドルの資金調達に成功したGenmoが開発した「Mochi 1」を取り上げます。
そして、生成AIウィークリーの中でも特に興味深い生成AI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、人間には聞き取れないノイズを音楽に埋め込むことで、AIモデルの学習を妨げる防御フレームワークについての研究を単体で掘り下げました。

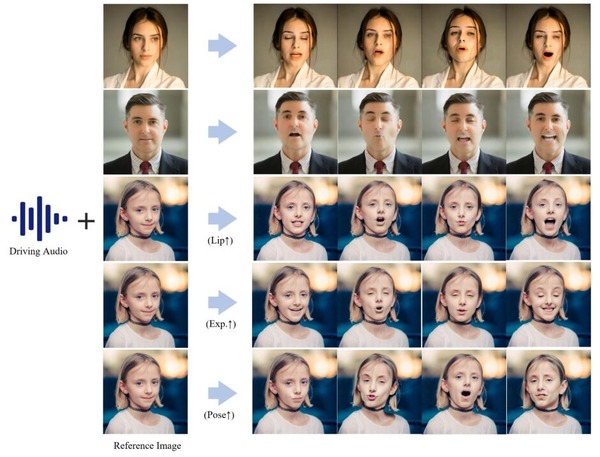
■音声に応じて人物画像を数時間話させる、ローカル実行可能なリップシンク生成AI「Hallo2」
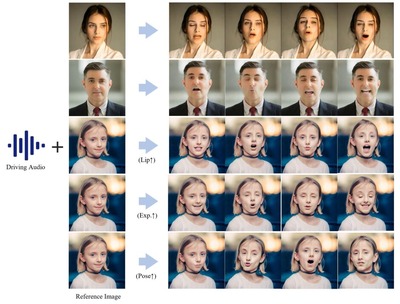
オープンソースの「Hallo2」は、1枚の人物画像から音声に合わせて数十分間から数時間の動画を生成できる、長時間・高解像度のオーディオ駆動型ポートレート画像アニメーション生成モデルです。
4K解像度での出力が可能で、音声による制御に加えて、テキストプロンプトを使って表情や動きをコントロールすることもできます。例えば、「笑顔で」「真剣な表情で」といったテキスト指示を任意のタイミングで入力することで、より細かな表情の制御が可能です。
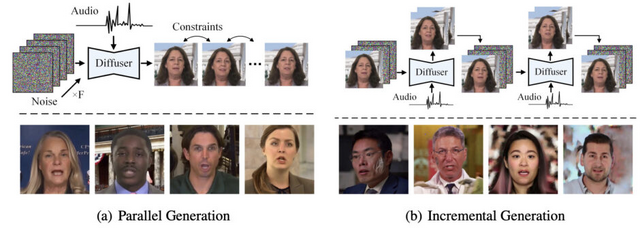
従来の技術では、数秒程度の短い動画しか生成できなかったり、長時間の生成を試みると画質が劣化してしまう問題がありました。
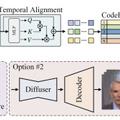
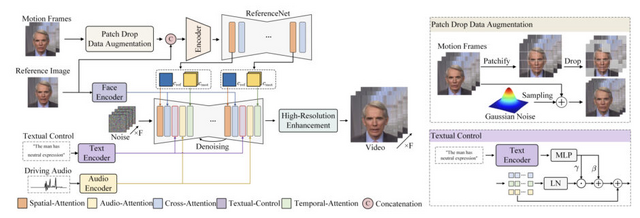
Hallo2では、この課題を解決するために「Patch drop」という新しい技術を導入しています。これは、動きの情報を伝えるフレームの一部を意図的に欠落させ、さらにGaussian Noiseを加えることで、元の人物の見た目を維持しながら自然な動きを実現する手法です。
研究チームは、この技術の性能を検証するため、3つの異なるデータセット(HDTF、CelebV、Wild)を用いて詳細な実験を行いました。その結果、画像の品質を示すFIDスコア、動画の品質を示すFVDスコア、そして音声との同期性を示すSync-Cスコアなど、すべての主要な評価指標において、既存の手法を上回る性能を示すことができました。

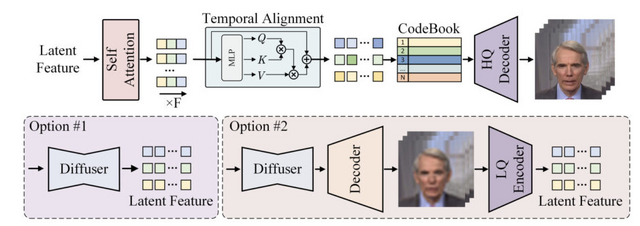

Hallo2: Long-Duration and High-Resolution Audio-Driven Portrait Image Animation
Jiahao Cui, Hui Li, Yao Yao, Hao Zhu, Hanlin Shang, Kaihui Cheng, Hang Zhou, Siyu Zhu, Jingdong Wang
Project | Paper | GitHub
■商用レベルでテキストから動画を生成する、商用利用可能なオープンソース動画生成AI「Allegro」
「Allegro」は、テキストから高品質で一貫性のあるビデオ生成が可能な商用レベルのオープンソース動画生成AIです。Apache 2.0ライセンスの下で公開されており、学術研究者から商用利用者まで、誰でも無料で活用することができます。
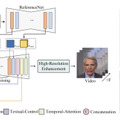
モデルの技術的な構造は、2つの主要なコンポーネントから成り立っています。1つ目はVideoVAE(Video Variational Auto-Encoder)で、ビデオデータの空間的・時間的な圧縮と展開を行い、効率的な処理を実現します。2つ目はVideoDiT(Video Diffusion Transformer)で、T5テキストエンコーダーを採用してテキストの意図を正確に理解し、それに基づいて高品質なビデオを生成します。
訓練データセットは、106Mの画像データに加え、48Mのビデオデータセットを使用し、それぞれに関連したテキストキャプションを付与しました。トレーニングは複数の段階で実施され、まずテキストから画像を生成する基本的な能力を習得し、次にビデオ生成の能力を段階的に向上させていきます。
完成したモデルは720p解像度、88フレーム(15 FPS)の最大6秒でビデオを生成可能です。性能評価では、Allegroは既存のオープンソースモデルを6つの評価軸すべてで上回り、商用モデルの多くの領域でも大きな優位性を示しました。特に、ビデオとテキストの関連性では全ての商用モデルを上回り、全体的な品質ではHailuoとKLINGに次ぐ高評価を獲得しています。



Allegro: Open the Black Box of Commercial-Level Video Generation Model
Yuan Zhou, Qiuyue Wang, Yuxuan Cai, Huan Yang
Paper | GitHub | Hugging Face
■水や髪などの滑らかな動きを得意とする、商用利用可能なオープンソースな動画生成AI「Mochi 1」
2840万ドルの資金調達に成功した「Genmo」が、オープンソースのビデオ生成モデル「Mochi 1」のプレビュー版をリリースしました。
Mochi 1は100億パラメータを持つ拡散モデルで、新しいAsymmetric Diffusion Transformer(AsymmDiT)アーキテクチャを採用しています。このモデルは30fpsで最大5.4秒の滑らかな動画を生成でき、流体力学(水や煙など)や毛髪のシミュレーション、一貫性のある自然な動作を表現することができます。
生成される動画の品質についても、既存のオープンソースモデルの中では最高水準を達成しており、商用の非公開モデルと比べても遜色のない性能を示しています。特に、入力されたテキストの内容を忠実に反映した動画を生成できる点や、動きの自然さについて高い評価を得ています。
現時点での制限事項として、480pの解像度制限や、極端な動きを伴うケースでの歪みや歪曲が発生する可能性が挙げられます。また、写実的なスタイルに最適化されているため、アニメコンテンツの生成は得意としていません。
Apache 2.0ライセンスの下で公開されるMochi 1は、個人利用および商用利用ともに無料で利用可能です。現在リリースされているのは480pのベースモデルで、HD版は今年後半にリリースされる予定です。
Mochi 1
Genmo
GitHub | Blog | Hugging Face
■AIが画面操作する「OmniParser」をMicrosoftがリリース GPT-4Vがボタンの位置と機能を理解
Microsoftは、GPT-4Vを用いた画面解析AI「OmniParser」をGitHubなどにおいて公開しました。OmniParserは、画面のスクリーンショットだけを見て、クリックできるボタンやアイコンの位置を特定し、それぞれの機能を理解します。
システムは、UIスクリーンショットを構造化された要素に分解し、画面上のクリック可能なアイコンや領域を検出するモデルと、それらの機能的な意味を理解して説明を生成するモデルを組み合わせています。
開発にあたって研究チームは、まず人気のWebサイトから6万7000枚以上のスクリーンショットを集め、それぞれの画面上でクリックできる場所を特定するAIモデルを作りました。さらに、7000以上のアイコンについて、それぞれがどのような機能を持つのかを説明するデータを用意し、AIにアイコンの意味を理解させる訓練を行いました。
この技術をGPT-4Vと組み合わせることで、「メールを開いて」「設定を変更して」といった指示に対して、該当するボタンやアイコンを見つけ出し、適切な操作を行うことができます。
評価実験では、ScreenSpot、Mind2Web、AITWという3つの主要なベンチマークで検証を行い、HTMLやView hierarchyなどの追加情報を必要とせずに、GPT-4Vの性能を大幅に向上させることに成功しました。
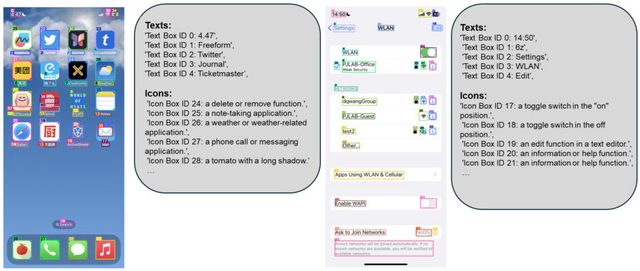
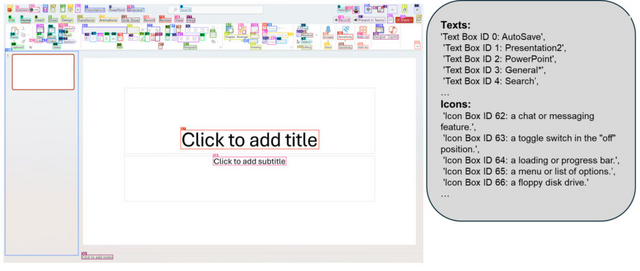
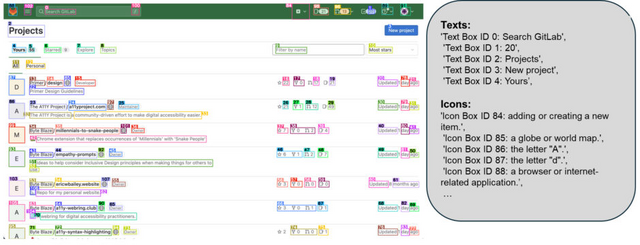
OmniParser for Pure Vision Based GUI Agent
Yadong Lu, Jianwei Yang, Yelong Shen, Ahmed Awadallah
Project | GitHub | Hugging Face