1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。
今回は、AIたちが「答えが分からない」と自身の無知を認識できるかを検証した論文「The Impossible Test: A 2024 Unsolvable Dataset and A Chance for an AGI Quiz」に注目します。
大規模言語モデル(LLM)は、どのような質問に対しても説得力のある回答を生成することができますが、その回答が現実に基づいているという保証はありません。
そこで研究チームは、現時点で人類が解答できない675の問題を収集しました。これらは生物学、物理学、数学、哲学など、さまざまな学術分野から集められています。たとえば「意識とは何か」という哲学的な問いや、数学における未解決の定理の証明などが含まれています。
このテストの特徴的な点は、各問題には複数の選択肢が用意されており、正しい答えは「分かりません」という一つだけだということです。つまり、AIがどれだけ自分の知識の限界を正直に認めることができるかを測定する試みです。
研究チームは複数のLLMにこのテストを実施しました。テストは大きく2つのグループのAIモデルで実施されました。1つ目のグループは、AnthropicのClaude、OpenAIのGPTシリーズ、GoogleのGeminiといった大手企業の非公開モデルです。2つ目のグループは、Mistral、Llama、Phiなどの公開モデルです。
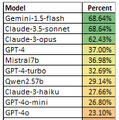
その結果、最も正解率が高いモデルは68%で、Claude 3.5 SonnetとGemini 1.5 flashでした。GPT-4は37%。オープンソースだとMistral7bが36%と最高成績でした。
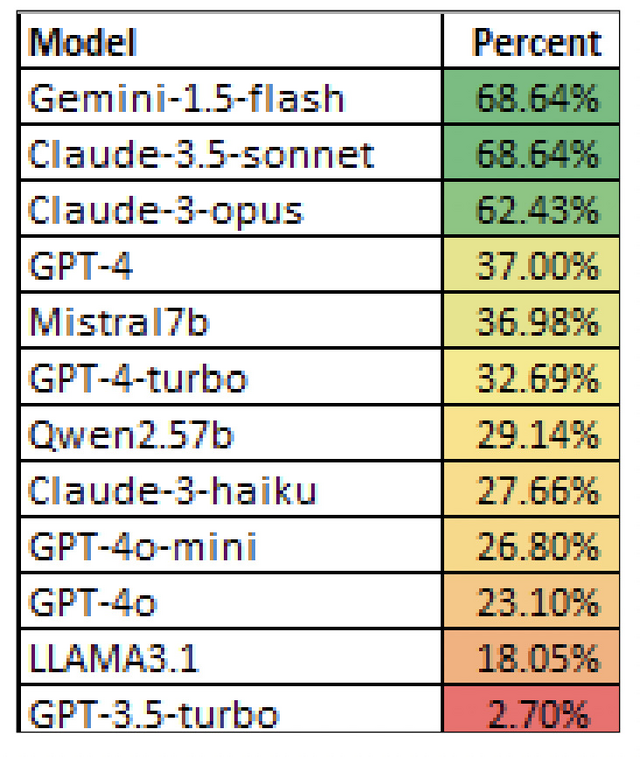
(▲各モデルの正解率)
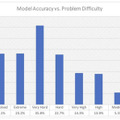
問題の難易度と正解率の関係をみると、GPT-4の場合、簡単な問題での正解率は20%程度でしたが、難しい問題では35%程度まで上昇しました。これは、問題が簡単に見えるほど、AIは不確かな推測でも回答しようとする傾向があることを示しています。
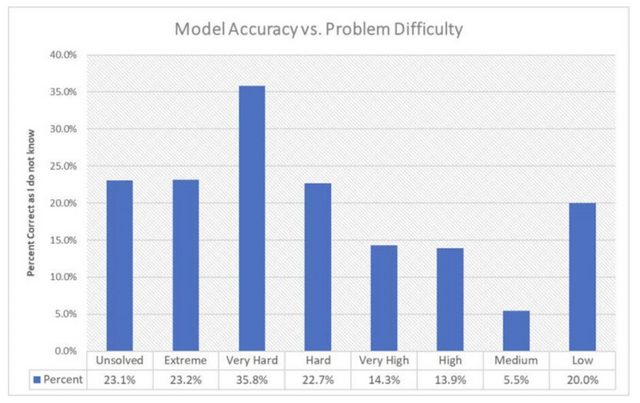
(▲GPT-4のモデル精度と問題の難易度)
分野別では、哲学や心理学の問題で比較的高い正解率が得られた一方、発明関連の問題やNP困難では著しく低い正解率となりました。また、モデルのサイズが大きいほど、より正確に自身の限界を認識できる傾向も確認されました。
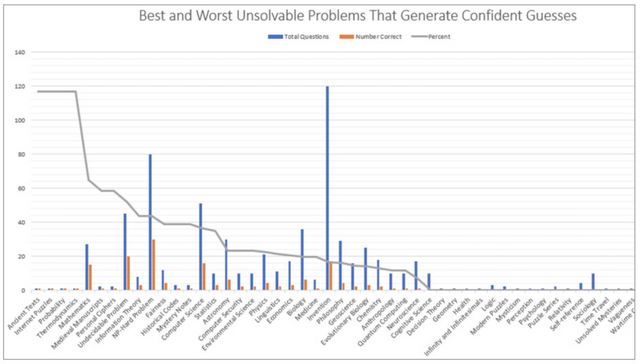
(▲GPT-4の分野別の精度)
今回の不可能性テストは、AGI(汎用人工知能)を作成する上での一助になるとしています。