



OpenAIが「o1」より強力な言語モデル「o3」とコスト効率の良い小型モデル「o3 mini」を発表しました。o3-miniは、2025年1月下旬に一般公開予定としています。
Googleは動画生成AI「Veo 2」を発表しました。また、推論系AIモデル「Gemini 2.0 Flash Thinking」を発表しました。思考プロセスを生成するようにトレーニングされた試験運用版モデルで、思考することで推論を強化しています。
さて、この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第76回)では、アニメの自動彩色と中間フレームを生成できるAIモデル「AniDoc」と、Metaの動画理解AIモデル「Apollo」をご紹介します。
また、テキストをリアルタイムに読み上げるストリーミングTTSモデル「CosyVoice 2」と、アリババのオープンソース大規模言語モデル「Qwen2.5」を取り上げます。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、OpenAIが最近発表したAIモデル「o3」と汎用人工知能(AGI)について、AGIの性能を評価するベンチマーク「ARC-AGI」の開発者フランソワ・ショレ氏(Googleの研究者)が考察した記事を掘り下げています。

アニメの自動彩色と中間フレームを生成できるAIモデル「AniDoc」
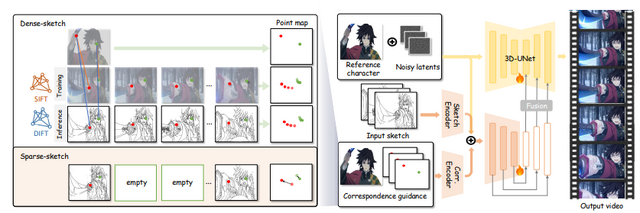
アニメーション制作の標準的なワークフローは、キャラクターデザイン、キーフレームアニメーション、中割り、彩色という4つの重要な工程で構成されています。AniDocは、このプロセスの労力を削減するために、生成AIの力を活用したツールとして開発されました。
AniDocの特徴的な機能は、1枚のキャラクターデザイン画像を参照として、異なるポーズやスケールの線画シーケンスを自動で彩色できる点です。さらに、中割り作業も自動化することができ、開始フレームと終了フレームの線画だけを提供するだけで、時間的に一貫性のあるアニメーションを作成することができます。
実験結果では、AniDocは既存の手法と比較して、画質と時間的一貫性の両面で優れた性能を示しました。同じキャラクターの異なるビデオクリップを1枚の参照画像で彩色できる柔軟性も実証されています。



AniDoc: Animation Creation Made Easier
Yihao Meng, Hao Ouyang, Hanlin Wang, Qiuyu Wang, Wen Wang, Ka Leong Cheng, Zhiheng Liu, Yujun Shen, Huamin Qu
Project | Paper | GitHub
Meta、動画理解AIの新モデル「Apollo」を発表
Metaとスタンフォード大学の研究チームが、大規模マルチモーダルモデル(LMM)における動画理解の仕組みを解明し、新しいAIモデル「Apollo」を開発しました。
研究の主要な成果として、小規模モデルでの実験結果が大規模モデルにも適用できる「スケーリング一貫性」を発見しました。これにより、莫大な計算リソースを必要とせずに効率的な研究開発が可能になります。
また、トレーニング時の毎秒フレーム数(fps)サンプリングが、従来の均一フレームサンプリングよりも大幅に優れていることを実証し、さらに動画表現に最適なビジョンエンコーダーの組み合わせも特定しました。
開発されたApolloは、3Bパラメータモデルでも7Bパラメータの既存モデルを上回る性能を示し、7Bモデルは同規模のAIの中で最高性能を記録しました。さらに、評価時間を41分の1に短縮できる新しいベンチマーク「ApolloBench」も開発しています。
Apollo: An Exploration of Video Understanding in Large Multimodal Models
Orr Zohar, Xiaohan Wang, Yann Dubois, Nikhil Mehta, Tong Xiao, Philippe Hansen-Estruch, Licheng Yu, Xiaofang Wang, Felix Juefei-Xu, Ning Zhang, Serena Yeung-Levy, Xide Xia
Project | Paper
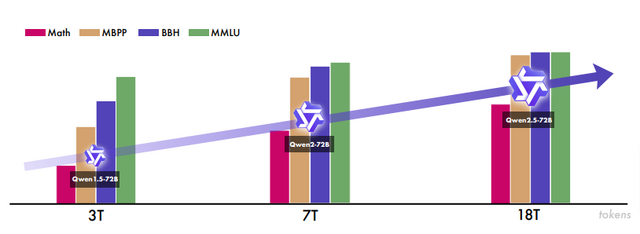
アリババの最新オープンソース大規模言語モデル「Qwen2.5」の技術レポートが公開
Qwenチームは、最新の大規模言語モデル「Qwen2.5」シリーズの技術レポートを公開しました。このモデルは、事前学習データを従来の7兆トークンから18兆トークンに拡大し、100万以上のサンプルを用いた微調整や強化学習を実施することで、性能を大幅に向上させています。
Qwen2.5シリーズは、オープンウェイトモデルとして0.5B、1.5B、3B、7B、14B、32B、72Bパラメータのモデルを提供し、さらにAPIサービス向けにQwen2.5-TurboとQwen2.5-Plusという2つのMoE(Mixture of Experts)モデルも用意しています。
特筆すべき点として、フラッグシップモデルのQwen2.5-72B-Instructは、約5倍のパラメータを持つLlama-3-405B-Instructと競争力のある性能を示しています。また、Qwen2.5-TurboとQwen2.5-Plusは、それぞれGPT-4o-miniやGPT-4oと同等の性能を、より効率的なコストで実現しています。
モデルの改善点として、生成可能な文章の長さが2000トークンから8000トークンに拡大され、表やJSONなどの構造化データの取り扱いが向上し、ツールの使用も容易になりました。さらにQwen2.5-Turboは、最大100万トークンまでのコンテキスト長をサポートしています。
Qwen 2.5は言語理解、推論、数学、コーディング、人間の選好との整合性など、幅広いベンチマークで優れた性能を示しています。また、このモデルは、Qwen2.5-Math、Qwen2.5-Coder、QwQなどの専門モデルや、マルチモーダルモデルの基盤としても活用されています。
Qwen2.5 Technical Report
Qwen: An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Yang Fan, Yang Su, Yichang Zhang, Yu Wan, Yuqiong Liu, Zeyu Cui, Zhenru Zhang, Zihan Qiu (additional authors not shown)
Paper | GitHub | Hugging Face
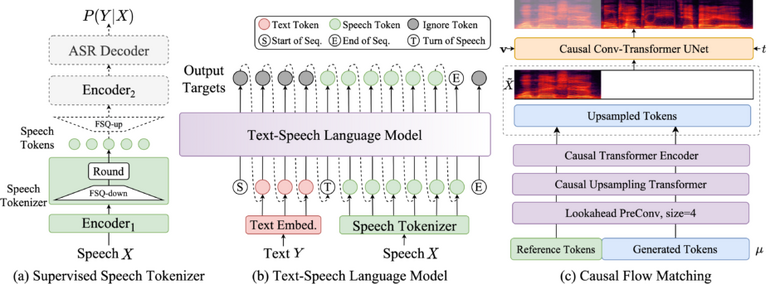
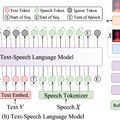
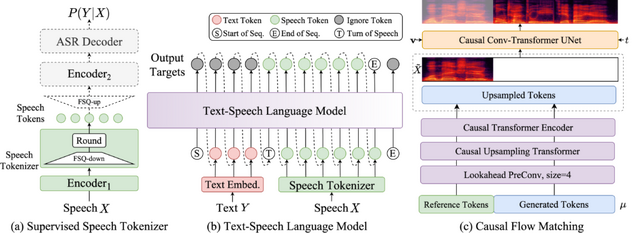
テキストをリアルタイムに読み上げるストリーミング音声合成AIシステム「CosyVoice 2」をアリババが発表
Alibaba Groupは、ゼロショットの「Text-to-speech」(TTS)ストリーミング音声合成AIモデル「CosyVoice 2」を開発しました。このシステムは、以前のCosyVoiceから大幅な改良を加え、より優れた音声生成能力を実現しています。
CosyVoice 2は、超低遅延での音声生成を可能にし、最初のパケット合成の遅延を150ミリ秒まで低減させることに成功しました。また、発音エラーを30%から50%削減し、Seed-TTSの評価セットにおいて最低の文字エラー率を達成しています。
最大の特徴は、リアルタイムでの音声生成(ストリーミング)と、一括での音声生成を1つのシステムで実現したことです。従来のシステムでは、ストリーミング方式では音質が低下する傾向がありましたが、CosyVoice 2ではその問題が改善されています。
実用面での機能も充実しています。感情表現の制御や方言アクセントの調整、役柄のスタイル、声の抑揚など、より細かな音声の制御が可能です。
多言語対応も強化されており、中国語、英語、日本語、韓国語など、複数の言語に対応しています。さらに、これらの言語を混ぜて使用する場合でも、自然な発音と滑らかな言語の切り替えを実現しています。
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, Fan Yu, Huadai Liu, Zhengyan Sheng, Yue Gu, Chong Deng, Wen Wang, Shiliang Zhang, Zhijie Yan, Jingren Zhou
Project | Paper | GitHub