






ClaudeはWeb検索機能をリリースしました。米国のすべての有料ユーザー向けに利用可能です。
GoogleはGeminiに新機能「Canvas」と「Audio Overview」を導入しました。CanvasはGeminiと対話しながらテキストやコードをリアルタイムで作成・編集・共有できるインタラクティブ機能です。
Audio Overviewはドキュメント、スライド、Deep Researchレポートをポッドキャスト形式の音声ディスカッションに変換する機能です。2人のAIホストが資料を要約し、トピック間のつながりを説明しながら活発な議論を展開します。
さて、この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第88回)では、高解像度な3Dメッシュを生成できるAIモデル「DeepMesh」、スマホカメラから実世界の3D空間を理解する大規模言語モデル「SpatialLM-Llama-1B」を取り上げます。
また静止画像を3Dビデオに変換するStability AI開発のモデル「Stable Virtual Camera」や、動画のシーンを維持しながら異なるカメラ軌道で再生成できるAIモデル「ReCamMaster」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、生成AIモデルが検索で引用する情報が誤ったものが多いことを指摘した研究を単体記事で掘り下げています。

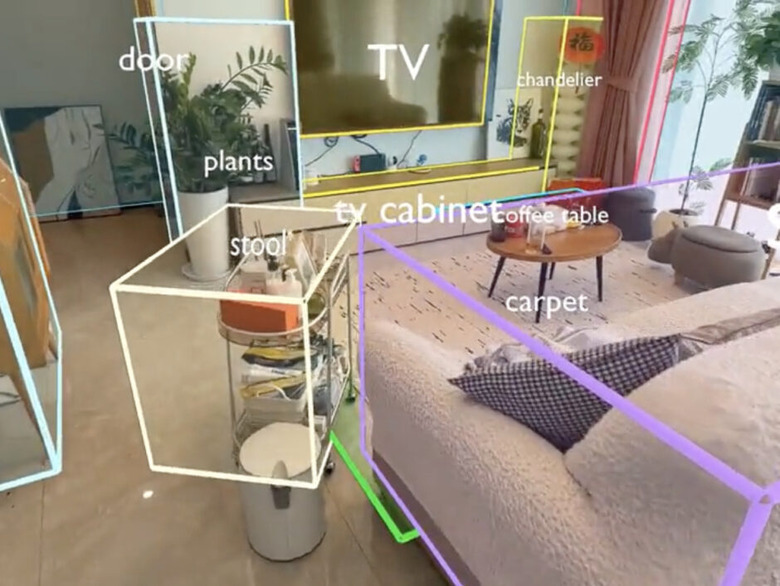
単眼カメラから実世界の3D空間を理解する大規模言語モデル「SpatialLM-Llama-1B」
SpatialLM-Llama-1Bはモデルサイズが12.5億パラメータで、中国のManycore Researchが開発した3D空間を理解する大規模言語モデルです。このモデルの特徴は、3Dポイントクラウド(点群データ)から壁、ドア、窓などの建築要素や家具などの物体を認識し、バウンディングボックスなどで出力できることです。
従来の技術では特殊な機器が必要でしたが、SpatialLMは単眼カメラで撮影したビデオやRGBD画像、LiDARなど様々な機器から得られたデータを処理できます。SpatialLMは、リアルタイム高密度SLAM「MASt3R-SLAM」を使用しています。
モデルの性能評価のために、107の3Dデータを含む「SpatialLM-Testset」が提供されています。このテストセットは、実際のビデオから再構築されたデータを使用しているため、ノイズや遮蔽物があり、従来のきれいなデータセットよりも難しい課題となっています。
ベンチマーク結果では、壁、カーテン、ベッド、ソファなど様々な物体カテゴリでの認識性能が報告されています。特にベッドの認識では95.24%のF1スコアを達成しています。

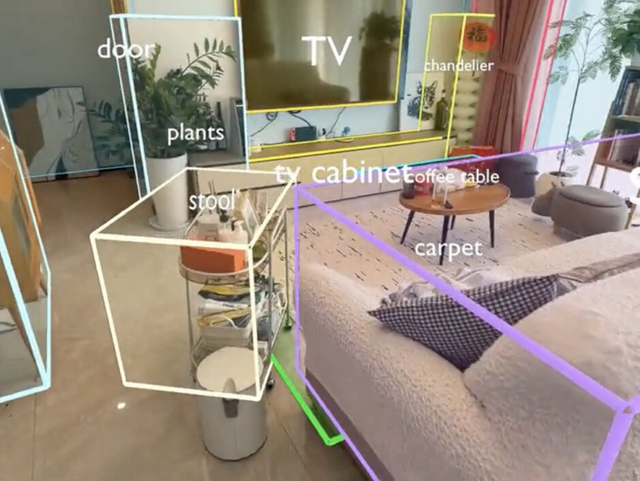

SpatialLM-Llama-1B
Manycore Research
Hugging Face
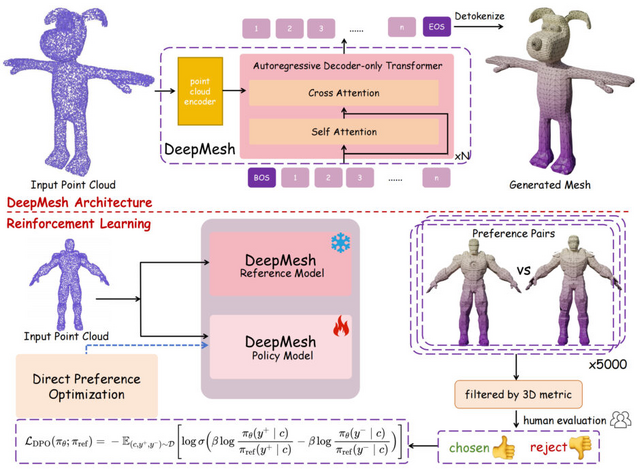
点群データから高解像度な3Dメッシュを生成できるAIモデル「DeepMesh」
「DeepMesh」は、点群データ(ポイントクラウド)から高品質な3Dメッシュを生成する技術です。従来の3Dモデル生成技術では、細部まで美しいメッシュを作るのが難しく、特に面の数が多い複雑なモデルの生成は困難でした。DeepMeshは2つの技術でこの問題を解決しています。
1つ目は効率的なトークン化アルゴリズムです。これにより、データ量を72%削減しながらも細部の情報を失わない処理が可能になりました。2つ目は強化学習の導入です。人間の好みに基づいたデータセット(5,000ペアの選好データ)を使って学習することで、見た目に美しいメッシュを生成できるようになりました。
DeepMeshは最大3万面を持つ高解像度メッシュを生成でき、従来の方法と比べて幾何学的な正確さと視覚的な美しさの両方で優れた結果を示しています。



DeepMesh: Auto-Regressive Artist-mesh Creation with Reinforcement Learning
Ruowen Zhao, Junliang Ye, Zhengyi Wang, Guangce Liu, Yiwen Chen, Yikai Wang, Jun Zhu
Project | Paper | GitHub
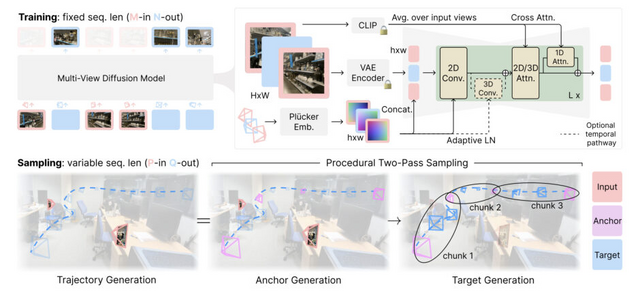
Stability AI、静止画像を3Dビデオに変換するモデル「Stable Virtual Camera」開発
Stability AIやオックスフォード大学に所属する研究者らは、入力画像から多様な新しい視点の画像を生成できる多視点拡散モデル「Stable Virtual Camera」を発表しました。これは2D画像を入力に3Dビデオに変換し、リアルな奥行きと視点を実現します。
具体的には、1枚から最大32枚の入力画像から、ユーザー定義のカメラ軌道に沿って、またはカメラ制御も非常に精密で、360°、レムニスケート(∞の形をした経路)、ズームアウト、スパイラル、ドリーズームなど14種類の動的カメラパスを使用して、シーンの新しい視点を生成します。
特筆すべき点は、NeRF(Neural Radiance Fields)のような複雑な3D表現を必要とせず、単一のネットワークで高品質な新規視点画像を生成できることです。これにより、大幅な視点変化と時間的な滑らかさを両立させた、最大で30秒程度の高品質な動画生成が可能になりました。
研究チームは10種類のデータセットを用いた包括的なベンチマークテストを実施し、Stable Virtual CameraはViewCrafterやCAT3Dなどの既存モデルよりも優れた性能を発揮しています。



Stable Virtual Camera: Generative View Synthesis with Diffusion Models
Jensen (Jinghao)Zhou, Hang Gao, Vikram Voleti, Aaryaman Vasishta, Chun-Han Yao, Mark Boss, Philip Torr, Christian Rupprecht, Varun Jampani
Paper | GitHub | Blog
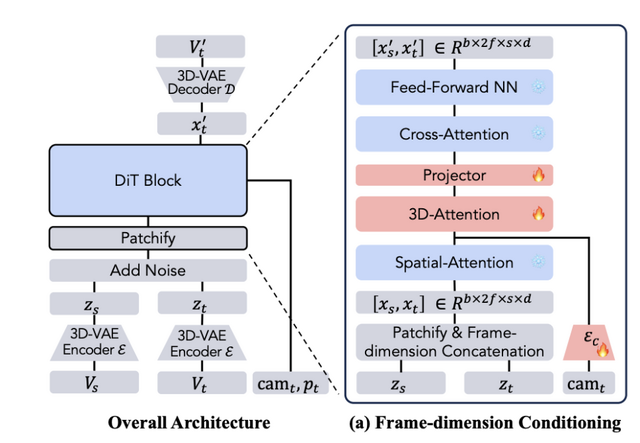
動画のシーンを維持しながら異なるカメラ軌道で再生成できるAIモデル「ReCamMaster」
単一動画から新たなカメラアングルの映像を生成する「ReCamMaster」技術が開発されました。入力された動画のシーンを保持しながら、異なるカメラ軌道から撮影したかのような映像を生成することができます。
従来の手法では動画の特徴を色情報などのチャネルで複雑に結合したり、特別な注意機構を追加したりする方法が主流でした。これに対しReCamMasterは、元の動画と生成したい動画の情報を時間軸に沿って単純に連結する動画条件付け機構という新しいアプローチを採用。この直感的かつシンプルな方法により、事前学習したテキスト生成動画(Text-to-Video)モデルの能力を最大限に引き出しています。
研究チームはトレーニングデータを構築するために、Unreal Engine 5を駆使した大規模な映像生成に取り組みました。この過程で40種類の3D環境内に13,600の動的シーンを構築し、122,000種類のカメラ軌道を用いて撮影された136,000本の高品質映像を生成。この多様なデータセットにより、ReCamMasterはさまざまな撮影状況に対応できる汎用性を獲得しています。
評価実験の結果、ReCamMasterは既存の最先端技術やベースラインモデルを大幅に上回るパフォーマンスを示しました。生成された映像は視覚的品質、カメラ精度、元映像との同期性において優れた結果を達成しています。
応用として、手振れした映像を滑らかに修正、ズームインして高詳細な映像を生成、元の映像に映っていない周辺部分を自然に補完などが挙げられています。



ReCamMaster: Camera-Controlled Generative Rendering from A Single Video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, Di Zhang
Project | Paper | GitHub