


OpenAIのo1推論モデルに匹敵するオープンウェイトモデルとして注目を集めている「DeepSeek-R1」について、Unslothチーム(エンジニアのDaniel Han氏とMichael Han氏の兄弟チーム)は671Bパラメータのモデルを効率的に量子化することに成功し、元の720GBから131GBまで80%のサイズ削減を実現したと発表しました。
単純にすべての層を量子化すると精度が低下する問題が発生してしまうため、同チームは選択的な量子化アプローチを採用しました。具体的には、モデルの重要な部分を4ビットや6ビットなどの高いビット数で量子化する一方、モデル全体の約88%を占めるMoE層を主に1.5ビット程度で量子化することで、モデル全体として平均1.58ビットの効率的な量子化を実現しました。このような動的量子化アプローチによって、高い軽量化を実現しつつ、実用的な性能レベルを維持したモデルが可能になりました。
Alibaba Cloudは、20兆以上のトークンで事前学習を行った大規模MoEモデル「Qwen2.5-Max」を発表し、APIを通じて一般提供を開始しました。このモデルは、多くのベンチマークでDeepSeek V3を上回る性能を示しています。
さて、この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第81回)では、DeepSeekの画像生成AI「Janus-Pro」と、Sakana AIによるLLMの知識を小規模モデルに転移させる蒸留法「TAID」を取り上げます。
また、アリババの画像理解能力が高いマルチモーダルAI「Qwen2.5-VL」や、歌詞から楽曲を生成するオープンソースの音楽AIモデル「YuE」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、OpenAIがリリースした「o3-mini」を単体記事で掘り下げています。

DeepSeek、画像生成AI「Janus-Pro」を公開。DALL-E 3やStable Diffusion 3 Mediumを超える性能
DeepSeekが新しい画像生成AI「Janus-Pro」を発表しました。このモデルは1.5Bと7Bという2つのサイズで展開され、画像の理解と生成の両方の能力を備えています。
Janus-Proは、先行モデルのJanusを3つの面で大きく改良しています。まず、トレーニング戦略を最適化し、より効率的な学習を実現しました。次に、学習データを大幅に拡充し、画像とテキストの理解力を高めるためのデータを約9,000万件、画像生成の品質向上のための高品質な訓練データを約7,200万件追加しました。さらに、モデルのサイズを拡大することで、より高度な処理が可能になりました。
トレーニングは3段階で行われ、各段階で異なる焦点を当てています。第一段階では基本的な画像処理能力の向上に取り組み、第二段階ではテキストから画像を生成する能力の強化に注力しました。最終段階では、様々な種類のデータをバランスよく組み合わせることで、総合的な性能の向上を実現しています。
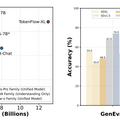
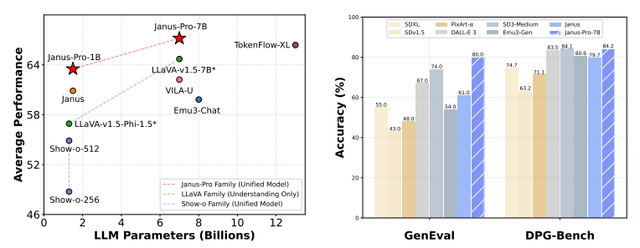
性能評価では、Janus-Pro-7Bにおいて、画像とテキストの理解力を測るMMBenchというテストで高いスコアを記録し、既存の主要なモデルを上回りました。また、テキストの指示に基づいて正確に画像を生成する能力を評価するGenEvalでも高い精度を達成し、DALL-E 3やStable Diffusion 3 Mediumといった強力なモデルの性能を超えています。


Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan
Paper | GitHub
Sakana AI、LLMの知識を小規模モデルに転移させる知識蒸留の新手法「TAID」発表
近年、大規模言語モデル(LLM)は日常的な対話から数学やコーディングまで、人間と同等のレベルでこなせるようになっています。しかし、これらのモデルの開発と活用には莫大な計算資源が必要となり、大きな課題となっています。
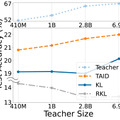
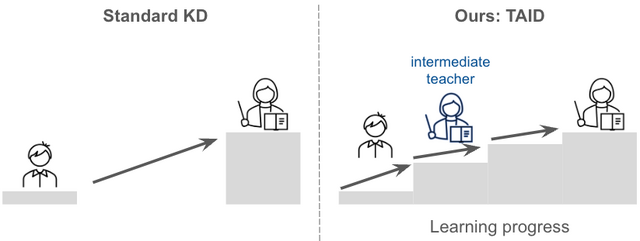
この課題に対して、Sakana AIは小規模で高性能な言語モデル(SLM)を効率的に構築するための新手法「TAID」を開発しました。TAIDは、LLMの知識を小規模モデルに転移させる「知識蒸留」の新しい手法で、学習過程に応じて段階的にLLMの知識を転移させる特徴があります。この手法は、生徒モデルの学習進度に合わせて教師モデルを段階的に変化させることで、より効果的な知識の転移を実現しています。
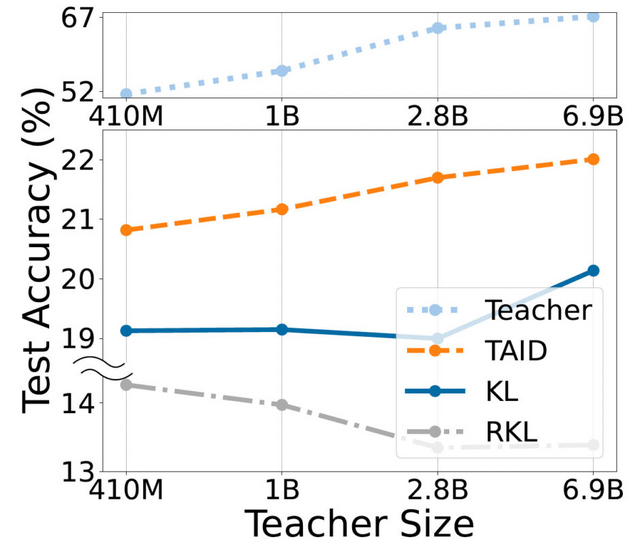
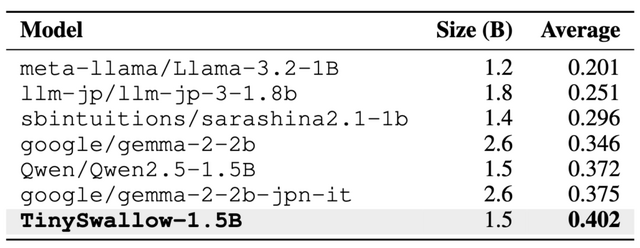
この技術を用いて開発された「TinySwallow-1.5B」は、32BパラメータのLLMから1.5BパラメータのSLMへと知識を転移し、同規模のモデルの中で最高性能を達成しています。さらに、小規模であるため、APIなどを介さずにスマートフォンやPCで直接チャットが可能となっています。従来の手法では教師モデルが大きくなると性能が低下する傾向がありましたが、TAIDではそのような問題を克服し、教師モデルの大きさに比例して生徒モデルの性能が向上することが確認されています。
TAID: Temporally Adaptive Interpolated Distillation for Efficient Knowledge Transfer in Language Models
Makoto Shing, Kou Misaki, Han Bao, Sho Yokoi, Takuya Akiba
Paper | GitHub | Blog | Hugging Face
画像処理能力が高いマルチモーダルAI「Qwen2.5-VL」を中国アリババが発表
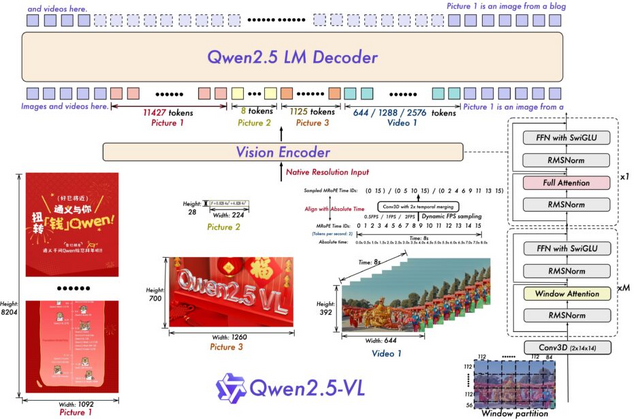
中国アリババのQwenチームは、前バージョン「Qwen2-VL」から画像処理能力を大幅に向上させた新しいAIモデル「Qwen2.5-VL」をリリースしました。このモデルは3B、7B、72Bの3つのサイズで提供されています。
Qwen2.5-VLは、花や鳥、魚、昆虫などの一般的な物体の認識だけでなく、画像内のテキスト、チャート、アイコン、グラフィック、レイアウトの分析に優れた能力を持っています。また、ラップトップやスマートフォンの操作が可能な視覚エージェントとして機能し、1時間を超える長時間の動画を理解し、関連する動画セグメントを特定することができます。
画像内のオブジェクトの位置を正確に特定する機能も備えており、バウンディングボックスやポイントを生成して座標や属性を安定したJSON形式で出力することができます。さらに、請求書やフォーム、表などのスキャンデータの内容を構造化された形式で出力することができ、金融や商業などの分野での活用が期待されています。
性能面では、フラッグシップモデルのQwen2.5-VL-72B-Instructが大学レベルの問題や数学、文書理解、一般的な質問応答、動画理解、視覚エージェントなど、さまざまなベンチマークで競争力のある性能を達成しています。特に文書や図表の理解において大きな優位性を持ち、タスク固有の微調整なしで視覚エージェントとして機能することができます。

Qwen2.5-VL
Qwen team
GitHub | Blog | Hugging Face
歌詞からボーカルと伴奏を含む楽曲を生成するオープンソースの音楽AIモデル「YuE」
これまでテキストを条件とした音楽生成モデルは、非ボーカル音楽の短いクリップに対して高品質な結果を生み出してきましたが、ボーカルパートと伴奏パートの両方を含む数分間の楽曲全体を生成することは依然として課題となっており、いくつかのクローズドな商用システムでのみ満足のいく結果が確認されている状況でした。
中国の研究チームは、クローズドモデルに匹敵する、音声生成AIオープンソースモデル「YuE」を発表しました。このモデルは、歌詞からボーカルと伴奏の両方のパートを含む数秒から数分間(最長5分)の楽曲を生成することができます。多様なジャンルに対応し、英語、中国語、日本語、韓国語と複数の言語での楽曲生成が可能となっています。
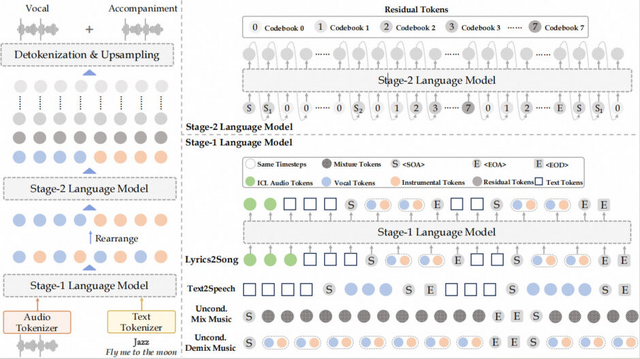
YuEは、2つの言語モデルを組み合わせて構成されています。1つ目は7Bパラメータを持つ言語モデルで、テキストラベル付きの意味豊かな音声・音楽トークン1.6兆個を学習しています。2つ目は1Bパラメータの言語モデルで、より細かな音楽要素を取り入れるために残差トークン2.1兆個を学習対象としています。さらに、敵対的生成ネットワーク(GAN)を使用して、音声を44.1kHzにアップサンプリングすることで、高品質な音声出力を実現しています。


YuE: Open Music Foundation Models for Full-Song Generation
Ruibin Yuan, Hanfeng Lin, Shawn Guo, Ge Zhang, Jiahao Pan, Yongyi Zang, Haohe Liu, Xingjian Du, Xeron Du, Zhen Ye, Tianyu Zheng, Yinghao Ma, Minghao Liu, Lijun Yu, Zeyue Tian, Ziya Zhou, Liumeng Xue, Xingwei Qu, Yizhi Li, Tianhao Shen, Ziyang Ma, Shangda Wu, Jun Zhan, Chunhui Wang, Yatian Wang, Xiaohuan Zhou, Xiaowei Chi, Xinyue Zhang, Zhenzhu Yang, Yiming Liang, Xiangzhou Wang, Shansong Liu, Lingrui Mei, Peng Li, Yong Chen, Chenghua Lin, Xie Chen, Gus Xia, Zhaoxiang Zhang, Chao Zhang, Wenhu Chen, Xinyu Zhou, Xipeng Qiu, Roger Dannenberg, Jiaheng Liu, Jian Yang, Stephen Huang, Wei Xue, Xu Tan, Yike Guo
Project | GitHub