









音声の書き起こしはライターにとって夢の技術だ。そのまま原稿にできるわけではないが、インタビュー原稿や取材記事を執筆する上での手間が劇的に減る。筆者はもうずっと昔から、書き起こし系の技術が出るたびに試行錯誤を繰り返してきた。
そんな中に、ちょっとびっくりするようなサービスが現れた。正確にいえば「使ってみたらびっくりするようなものだった」というのが正しいだろうか。
それはいわゆるジェネレーティブAIサービスである「Easy-Peasy.AI」だ。このうち、AIによる音声書き起こしサービス「AI Transcription」を日本語で使ってみた。
結果として、「非常に使えるが、面白い性質がある」こともわかってきた。現在のジェネレーティブAIとはなんなのかを考える上でも、興味深い事例となっている。
※この記事は、毎週月曜日に配信されているメールマガジン『小寺・西田の「マンデーランチビュッフェ」』から、一部を転載したものです。今回の記事は2023年1月30日に配信されたものです。メールマガジン購読(月額660円・税込)の申し込みはこちらから。コンテンツを追加したnote版『小寺・西田のコラムビュッフェ』(月額980円・税込)もあります。
日本語の文字起こしはまだ「完璧ではない」
本題に入る前に、現在の「いわゆるAIによる日本語書き起こし」がどのような状態にあるか、確認しておこう。
この種のサービスは、英語だと2015年頃から増え始め、2018年に登場した「Otter.ai」である種の完成を見る。周囲がうるさい場所でも音声を聞き取り、話者を区別し、「AさんとBさんの会話」として文字にしてくれる。今はさらに機能がアップし、書き起こし後にサマリーを自動生成、メールで送ってくれるようにもなった。

精度はもちろん100%ではない。固有名詞を中心に間違うことも多いが、頻度は非常に少なく、自分で確認すれば済む程度。筆者は、英語でのカンファレンスやインタビュー取材では、いまだOtterに頼りっぱなしだ。別のサービスに切り替える理由を見出せない。
一方、日本語でOtterの域に達したサービスはまだない。
日本語で書き起こしをできるサービスは増え、話者の自動認識も可能になっている。以下は筆者も日常的に使っている「CLOVA Note」の画面だ。
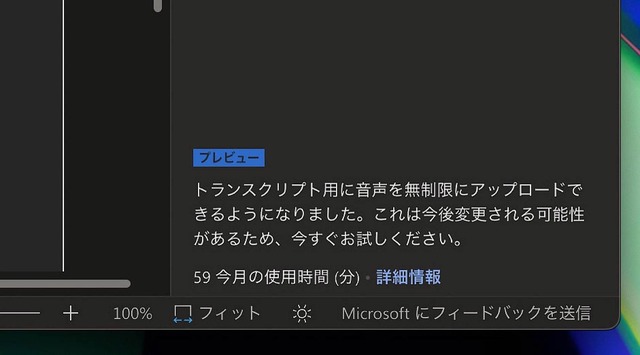
ちなみに「ウェブ版Microsoft Wordでの文字起こしは」、Office 365利用者の場合、現在、書き起こし可能時間が「無制限」になっている。追加料金なしでこれはとても美味しい。変更の可能性があるので、お得に使いたい方は今のうちの利用をお勧めする。
閑話休題。
ただ、この種の日本語向けサービスは、肝心の「書き起こし精度」がいまひとつだ。そのまま文章として読めるものは少なく、相当に修正を必要とする。「あー」「えー」という俗に「ケバ」と呼ばれる部分も、間違いも多い。
まあ、とはいえ、「ないよりまし」ではある。
筆者は取材記事の作業過程だけでなく、note版マガジン向けの追加コンテンツ「今週の壁打ち」で、毎回音声配信のテキスト起こしをつけている。その作業には「CLOVA Note」を使っているが、修正にかかる時間がけっこうあり、短くなったとはいえ「負担」ではあった。
文字起こしに「Easy-Peasy.AI」を使ってみた
というわけで今回の本題に入る。
もうちょっと精度の高い日本語書き起こしができないものか……? そこで1つのアイデアが浮かんだ。
「書き起こしたテキストを、最近流行りのジェネレーティブAIにリライトしてもらえば、手間が減るのではないか?」
書き起こし用のAIは、音声をマッチングして認識し、「それと思われるテキスト」に変換する。
日本語の場合、書き言葉と話し言葉が大きく異なっていることや、前出の「ケバ」の問題が大きい。仮に正確に音声がテキスト化されたとしても、そのままで読みやすい文章になるとは限らないのだ。実のところ、Otterなど英語系のサービスでも「ケバ」は内部でとっているそうなのだが、日本語に比べるとそもそもの認識率が高いこともあってか、文章としての不自然さは小さい。
すなわち、「話し言葉を認識した結果の不自然さ」が問題なのだとすれば、「不自然な文章を整形してくれる作業」を挟めばいいのではないだろうか?……と筆者は考えたわけだ。
とはいえ、それをすぐに実現するのはちょっと面倒だ、と思った。文章のジェネレーティブAIである「ChatGPT」は、文字量の制限もあってそのようには使えない。ChatGPTのベースであるOpenAIのサービスを使って構築すればできるのはわかっているのだが、筆者はライターであって開発者ではないので、短時間で構築作業をするのは難しい。締め切りが落ち着いて時間ができたら試してみるか……くらいのつもりで考えていた。
……と、そこに、SNSに流れてきたのが「Easy-Peasy.AI」だった。
ChatGPTよりも速い、ということで評価されていたのだが、また別の性質も持ち合わせている。「サービス」としてしっかりと構築されているので、作業用のテンプレートが非常に豊富である、ということだ。
「ネイティブスピーカーのように書く」「メールの返事を書く」「Instagramのキャプションを作る」「文章をリライトする」などのテンプレートが用意済みなので、選んで使うだけでいい。有料版のみとなるが、日本語にも対応している。
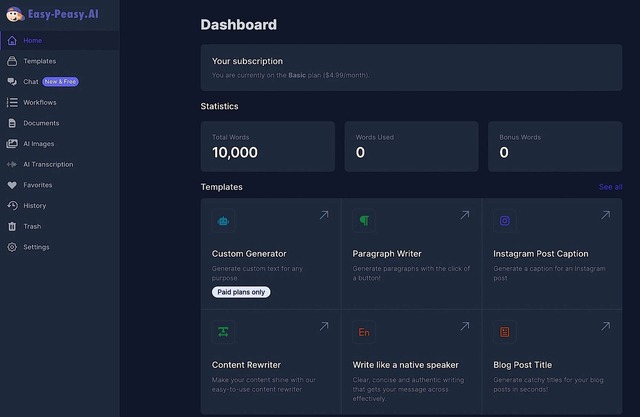
以下の画像は、有料プランに入った上で「文章をリライトする」機能を使い、本メルマガの一部を「ファニー」にリライトしてもらったものだ。内容がこのリライトで適切かは、また別の話として、文章としてはけっこうちゃんとしている。課金は「処理する単語の量」で決まり、英語以外の言語に対応するには有料版への契約が必要になる。ちなみに、1万語までの利用で毎月4.99ドルとなっている。
この中に「AI Transcription」、すなわち音声からの書き起こし機能があったので、ちょっと試してみることにしたわけだ。ジェネレーティブAIをベースとした書き起こしなので、先ほど筆者が考えた「音声書き起こしをジェネレーティブAIでリライトしてもらう」という流れに近い結果になる、と想定してのことだ。
日本語で書き起こせるかもわからず進めてみたのだが、書き起こしはできた。ただ、書き起こしには他のサービスより多少時間がかかる印象がある。26分の音声の書き起こしに4、5分ほど必要である。
「自然な日本語」に書きおこすジェネレーティブAIだが……
では品質はどうか。
機能としてはOtterやCLOVA Noteに劣る。話者の区別がなく、テキストと録音データのリンクもない。本当にシンプルな「書き起こし」しかない。英語の書き起こしなら、このサービスを使う必然性は薄いだろう。
だが、日本語だとちょっと変わってくる。
以下は、1月27日にnoteで公開した「今週の壁打ち」音声のテキスト起こしの一部だ。CLOVA NoteとEasy-Peasy.AIの結果を並べてご覧いただこう。改行位置をごく一部変えている(流石に読みにくいため)が、それ以外は修正していない。
<CLOVA Note>
はい、えーっと、今週の1本目です。あのー、aiがえー、論文を書くのはどうなのかって話がありますね。で、ただ これまシンプルな話でして。aiっていうのはツールなので、 筆者は筆者なんですよね。で、そこに対してaiが筆者で名前を連ねる必要があるかっていうと、これは根本的にないです。
で、というのは、書いた人要は名前を出して、えーっと世に出した人いが筆者なんですよね。で、 どんな通ー路を使おうが、誰かに欠かせようが、えー、責任を持つのは筆者なんですよ。で、 結果としてそれが受け入れられるか、受け入れられないかっていうのは、どんな形になろうが、筆者は責任を負うものです。で、例えば学生の論文だっても同じなんでしょね。 学生の論文が自分の名前で、えーっとチャットgptで書いたえーっとーものを出しました。で、ほとんど手を書けずに、内容も確認しないで出したとします。
で、その時に誰が責められるかと言ったら、それは名前を書いて出した人なんですよ。
で、さらにはそれが世の中に出て高く評価されてしまったとしても、後からaiだとばれたら、えー。攻めくを負うのはその型なんですね。で、 仮にaiだとバレなかったとしたら、 それはすなわちaiがすごくよくできてて、一切手を加えなくても、文章ができたら、それは奇跡的です。けれども、そうじゃなくて、内容確認したりだとか、えー、自分らしさというのをちゃんと組み込んだりだとか、そういうことをしたら、それはもうやっぱり書いた人筆者のものなんですよね。
で、それは過去からある話であって、別に特別なツールを使ったからといって、どうこうという話ではないです。で、その辺がなんていうか、こう コストをかけずに機械でできてしまうことによって、えーっと、ちょっとセンシティブな話になってきてるように見えるんですけども、本質的にはやはり誰が出したか出した人の名前責任で全て追わなければいけない。
<Easy-Peasy.AI>
はい、今週の1本目です。AIが論文を書くのはどうなのかという話がありますね。
ただ、これもシンプルな話でして、AIというのはツールなので、筆者は筆者なんですよね。そこに対してAIが筆者で名前を連ねる必要があるかというと、これは根本的にないです。というのは、書いた人、要は名前を出して世に出した人、AIが筆者なんですよね。
どんなツールを使おうが、誰かに書かせようが、責任を負った筆者なんですよ。結果としてそれが受け入れられるか受け入れられないかというのは、どんな形になろうが筆者は責任を負うものです。例えば、学生の論文だと同じなんですよね。学生の論文が自分の名前でチャットGPTで書いたものを出しました。ほとんど手をかけずに、内容も確認しないで出したとします。その時に誰が責められるかといったら、それは名前を書いて出した人なんですよ。さらには、それが世の中に出て高く評価されてしまったとしても、後からAIだとバレたら、責め口を追うのはその方なんですよね。
仮にAIだとバレなかったとしたら、それはすなわちAIがすごくよくできていて、一切手を加えなくても文章ができたら、これは奇跡的ですけれども、そうじゃなくて内容確認したりだとか、自分らしさというのをちゃんと組み込んだりだとか、そういうことをしたら、それはもうやっぱり書いた人、筆者のものなんですよね。
それは過去からある話であって、別に特別なツールを使ったからといって、どうこという話ではないです。その辺が、コストをかけずに機械でできてしまうことによって、ちょっとセンシティブな話になってきているように見えるんですけれども、本質的にはやはり誰が出したか、出した人の責任で全てを追わなければいけない。
差は明白だろう。ちゃんと文章として読めるのは明らかに後者だ。
実際にはEasy-Peasy.AIの場合、以下の画像のように出力されていて、全然改行が入っていない。だから、ちゃんと段落の体裁を整える、という作業は必要になる。また、変換の間違いもゼロではない。
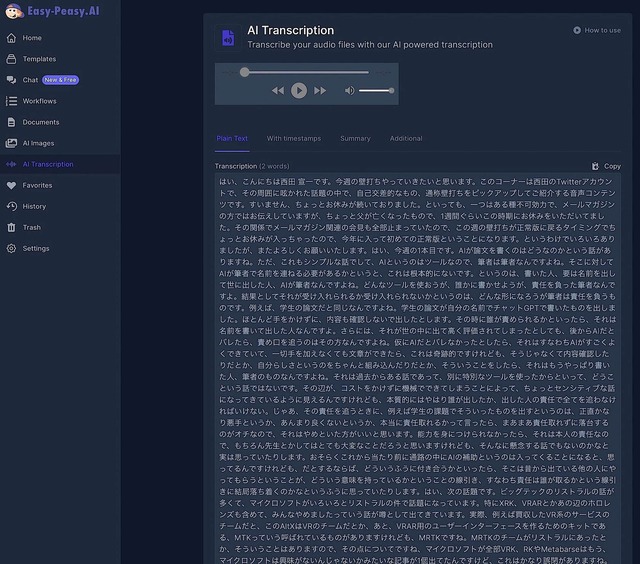
しかし、前者と比べると、書き起こし文としての自然さは歴然だ。前者は音声をテキストにそのまま変換している印象だが、後者はケバとりも含め、「音声から得られた文章を処理して読みやすい文章にしている」印象を受ける。
ただ、あくまで印象論に過ぎないが、文章を丸める過程で「作ってしまう」ところがあり、「このニュアンスで話したのではないのにそう書かれているな」と感じるようなところがあった。
これまで日本語の書き起こしの場合、間違いの結果意味が読み取れない文章はあっても、意味が変わってしまうことはなかった。英語の場合、「not」を聞き取れず逆の意味になる、という流れはあったのだが、日本語ではそうはならなかった。
具体的に、前掲のサンプルで言えば以下の部分だ。
<CLOVA Note>
で、そこに対してaiが筆者で名前を連ねる必要があるかっていうと、これは根本的にないです。
で、というのは、書いた人要は名前を出して、えーっと世に出した人いが筆者なんですよね。
<Easy-Peasy.AI>
そこに対してAIが筆者で名前を連ねる必要があるかというと、これは根本的にないです。というのは、書いた人、要は名前を出して世に出した人、AIが筆者なんですよね。
「AIは筆者ではない」という意味で話した文章が、後者ではなぜか「AIが筆者」になってしまっている。認識した言葉を並べた結果、そちらの方が自然な文章だとAIは考えたのだろう。
ジェネレーティブAIは、人間のように考えて正しい内容を答えとして返す、と言われるが、それはちょっと正確ではない。ジェネレーティブAIは内容の正しさを理解するものではなく、大量のデータの中で「そちらの方が言及量が多い」などの条件からデータを作っているだけだ。文章の正しさ・わかりやすさを選択して作っているわけでもない。「指示に従うならなんとなくこっちの方がいい」という感じだろうか。前述のような間違いが紛れ込むのも、実にジェネレーティブAIらしい。
おそらく今後、書き起こしについては、ジェネレーティブAIが使っている高度な言語モデルを使ってさらに質があがっていくのは間違いない。その時、単語の認識間違いだけでなく、「文章にする作業」でニュアンスのずれなどが発生する可能性は高い。実際にツールとして使う場合には、そうした部分を把握して「ずれを適切に修正する」ことが必要になってくるだろう。





