









現役グラビアカメラマンでありソフトウェアエンジニアでもある西川和久氏が、画像生成AIを使ったリアルなAIグラビア作成技術を解説する連載の第三回。
今回はポーズ / 構図をテーマに、プロカメラマンとしての撮影スタイルとAI生成の共通点、現時点のAIでは難しい手指の表現を改善する技術についても説明します。(編集部)

実際の撮影と「呪文」の関係は似ている?
グラビアでもポートレートでも、撮影する時は「立って」「座って」「前向き」「後ろ向き」……といったようにカメラマン側から指示を出す。
この大雑把な指示はどのカメラマンでもすることだが、顔の向きだったり腕の形だったり足の位置といった細かいことは、「指示する」カメラマンと「指示しない」カメラマンとで分かれる。これは撮影スタイルの話なので、どちらが良い悪いではない。
筆者の場合は割と大雑把で、細かい指示はせず、後の事はそのモデルに任せる=個性だと思っている。笑い話になるが、1番撮ってた20年ほど前だと、A面/B面(前向き/後ろ向き)と言えば皆パッパと動いてくれたが、流石に最近では通じなくなってしまった。たまに「あ、それ知ってる!」と言われ苦笑したりする。
そしてポーズを指示すると同時に、頭の中では、「この子でこの場所、この衣装なら構図はこんな感じ」と何パターンか考えており、寄って撮るのかちょい引きか全身に近いかなど、優先順位も含め決めている。つまり、シャッターを切る前から撮りたい絵はおおよそ決まっている(もちろん例外もある)。
「寄りも引きも色んなポーズも全部撮ればいいのでは?」と疑問に思う方も多いと思うが、現場ではなかなかそうも行かない。というのも時間制限があるからだ。
スタジオやその撮影場所を押さえている時間が何時間で、その中で水着を何パターンか撮るとなると、1つの衣装に使える時間はそう多くない(セッティング、片付け、着替え/ヘアメイク、休憩なども含まれる)。
加えて最近だと動画撮影も行うことが多く、時間配分としては動画の方がより多く割り当てられる。写真の撮影時間は減る一方だ。にも関わらずディレクターからはいっぱい写真が欲しいと理不尽な要求もされる(笑)。
ポーズ/構図指定プロンプトの基本
前置きが長くなってしまったが、Stable Diffusionのポーズ/構図と呪文(プロンプト)はこれと非常によく似ている。
モデルのポーズ
standing(立つ)
sitting(座る)
looking at viewer(視線こっち)
lie down(寝転ぶ)
カメラの撮影位置
from front(前から)
from above(上から)
from below(下から)
from behind(後ろから)
from side(横から)
構図
full body(全身)
half body(またはupper body/上半身)
portrait(バストアップ)
thigh focus(膝上)
……と言った感じだ。
例えばstanding,thigh focusと書けば、直立で膝上の写真が出てくる(多くの場合は)。ただ本当に腕を下にしての直立なのか、何か腕や手の位置が違うのか、少し前かがみ気味なのか少し横向きなのかは、Checkpoint(学習モデル)とseed次第。
つまり先に説明した「細かい部分はモデル任せ」となり、筆者の撮影スタイルと同じとなる。
もちろんarms up(両手を上げる)、hands on chest(胸に手を添える)などと組み合わせばもっと細かい指示も可能だ。参考までに、arms behind headとすると頭の後ろで腕を組むので手(指)が見えなくなり、指問題をごまかす事ができる。
作例
では実際作例で試してみたい。使用したCheckpointは扉の写真も含め全て、前回少しご紹介したyayoi_mix v2.0。BRAV6ベースに作られたものだ。
今回は、ポーズ/構図以外の呪文(Negativeも含め)や設定は固定。thigh focus, standing,この部分だけ入れ替える。
なおポーズ/構図の作例と言うことで、最後のグラビア以外、出た画像を掲載サイズに合わせてUpscale+ノイズを加えたほか手を入れていない。よりリアルな写真に近づけるための仕上げは省いている。予めご了承頂きたい。
Prompt:
(8k, best quality, masterpiece, ultra highres:1.2),
photo of japanese woman, 20yo, camisole, shorts, smile, pool background,
thigh focus, standing,
<lora:eye-nolight_03:-0.8>
※thigh focus, standing,の行だけ入れ替える
Negative prompt:
SimpleNegative,illustration,3d,sepia,(painting),cartoons,sketch,(worst quality:2),(backlight:1.2),bad anatomy,bad hands,double navel,collapsed eyeshadow,multiple eyebrows,freckles,signature,logo,2faces,((3fingers:1.2)),((4fingers:1.2)),((6fingers:1.2)),(laugh line:1.2),
※前回の筆者標準にSimpleNegativeと((3fingers:1.2)),((4fingers:1.2)),((6fingers:1.2)),(laugh line:1.2)を加えている
Settings:
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 3381279521, Face restoration: CodeFormer, Size: 512x768, Model hash: 8ec9b85b4d, Model: Yayoi_yayoi_mix_v20, Clip skip: 2,
 |  |
 |  |
 |  |
thigh focus, standing,
thigh focus, standing, from behind,
thigh focus, sitting, from above,
thigh focus, sitting, (from below:1.3),
(full body:1.2), standing,from side,
selfie, from above,
いくつか補足説明すると、from belowが(:1.3)となってるのは重みを付けて下からの角度を調整している。もっと重みを付けると更に下からのアングルになる。
(full body:1.2)は、普通にfull bodyだけでは全身にならなかったから。この辺りは他の呪文との兼ね合いもあるので必要に応じて調整する。
バックショットはthigh focusのthighの部分をあるワードにして、from behindを省く事ができるのだが、そのワードが隠語なので掲載を見送った(hipではない3文字)。直ぐ見つかると思うので興味のある人は調べて欲しい。
selfieは自撮りだ。今回はカメラマン視線なので趣旨は違うものの、こんなことも出来ると言う意味で作例を掲載している。
また呪文に食い合わせ的なものがあり、navel(ヘソ)と書くと後ろを向かなかったり、shoes(靴)と書くと、thigh focusと指定してるにも関わらず(靴を見せたいため)full bodyになったりする。
つまり見せたいものがある時はそれを優先し、他の相反する呪文が効かなくなってしまうのだ。言うことを聞かない時は、この手の「両方は無理」的な呪文を探すと良い。
呪文にある<lora:eye-nolight_03:-0.8>は、1回目でご紹介したsiitake-eyeとは別の方法で眼にキャッチライトを入れるLoRAだ。

イラスト系用だがリアル系でも使用可能。元々は名前の通り、眼から光を消すものだが、負にすると逆に光が入る。-1から0までの変化を掲載したので参考にして欲しい、siitake-eyeよりキャッチライトっぽいので、今後筆者のベースはこれにしたい。
openpose_handで指問題は解決できるか
Stable Diffusionで利用できるControlNetという技術があり、応用の一つに「OpenPose」がある。これは予めセットした写真から骨に相当する部分だけ書き出し、プロンプトと合わせることができるのだ。
つまり似たポーズで違う外観を作ることが可能となり、今回のお題、ポーズ/構図にも関係する。
ファンクション的には、体だけのopenpose、体と顔のopenpose_face、顔だけのopenpose_faceonly、体と手のopenpose_hand、そして全部入りのopenpose_fullがある。
openpose_fullにすると顔の輪郭まで似てしまうので、指問題に関しては体と手のopenpose_handを使う。
元写真は1回目に学習用で使った筆者撮影のものをセット。呪文は先のポーズ/構図から差し替え用の行を削除している。これは写真から得られたposeデータにポーズ/構図が含まれているからだ。
以下、元写真、実際の設定、元写真から生成されたposeデータ、出来た画像を掲載したので参考にして欲しい。
 |  |
 |  |
元写真(モデル 小彩 楓)
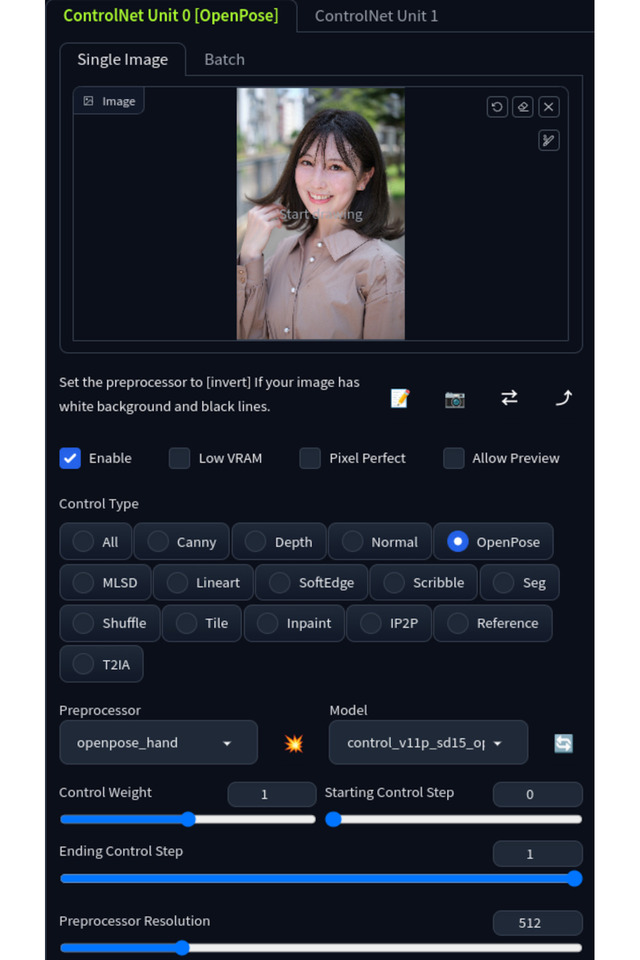
ControlNet / OpenPoseの設定
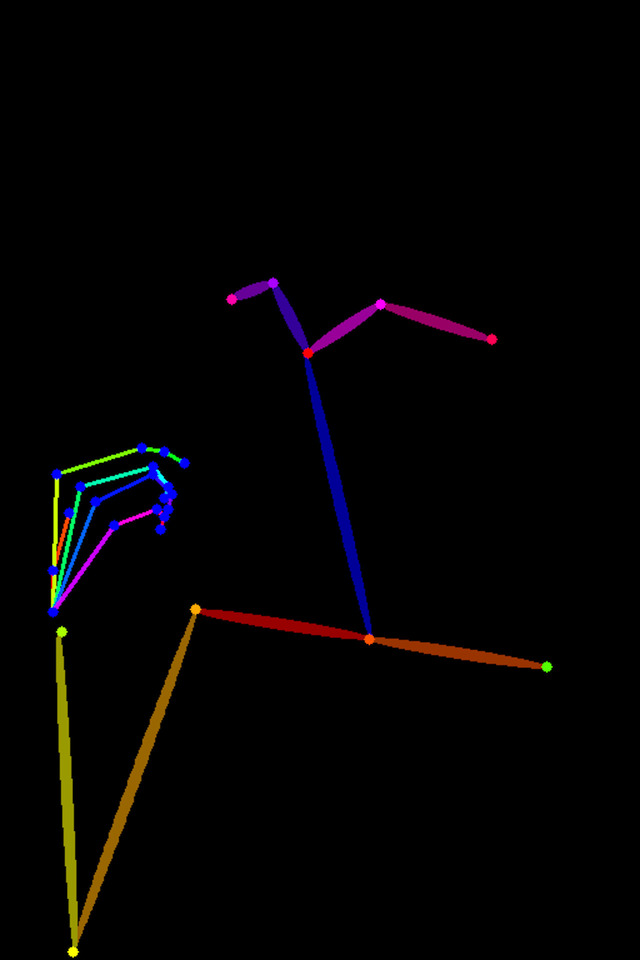
openpose_handで元写真から生成されたposeデータ。指の部分が含まれている
poseデータと呪文で生成された画像
如何だろうか。これを使えばposeデータに指が含まれているので、指問題は(ほぼ)解決できる。また呪文だけで指示するには難しい(分からない)ポーズをこれで真似する事も可能だ。
ただ逆に言えば、最大の問題は何らかの元写真が必要なこと。加えてポーズ/構図が固定されるため、作る側としては面白味に欠けることだろうか。
良さそうな具体例としては、昔撮ったヨーガのポーズ一式の写真があり、古いのでそれを全てAI生成画像に置き換えたいなどには合うだろうか。強力な機能なのでうまく使っていきたいところ。

今回のグラビアは、口絵の作例と同様にプールだが雰囲気を変えてナイトプールに、そして少し色っぽく仕上げてみた。これもopenpose_handを使っているが、元写真は水着なので紙面の都合上掲載できない。
ただ指はイマイチ。これはposeデータで形/本数は何とかなっても、レンダリング時の質感は別の話になるからだ。先に”ほぼ”と書いたのもこれが理由だったりする。
また後処理でGoogleフォトのエンハンス(自動調整)、HDR、ポートレートライトを使用した。ポートレートライトは後からレフを当てたような光を自然に追加できるため、この手の写真には効果抜群!(但しHDRと共にGoogle One加入またはPixelが必要)。
これまでスマホアプリ版でしか使えなかったが、最近やっとWeb版でも使えるようになり重宝している。AI生成画像でも有効なので、利用可能な人は是非試して欲しい。

¥88,800
(価格・在庫状況は記事公開時点のものです)
