






こんにちは。西川善司です。
昔、Oh! MZとかOh! Xというソフトバンクが出していたパソコン雑誌で、技術的な記事プログラムとか音楽作ったりしていた、プログラマー崩れの著述家です。
現在は、2台の大きさのだいぶ違うスポーツカーを乗り回したり、渓流ルアー釣りを楽しんだり、色んなゲームをプレイしたり、国内外の電機メーカー、半導体企業を取材したりしています。
自分は他媒体では、頂いた「1テーマ」に沿った技術コラムを書かせてもらっていますが、テクノエッジさんでは、そのメディア名を曲解して「技術の端っこ」をテーマにしたコラムを書かせていただきたいと思います。
「技術」には普段、自分が請け負うことの多い「電気的な先端技術」もありますが、それ以外にも、マクドナルドではドリンクを氷抜きで頼むと何も言われないけどケンタッキーでは「氷を減らしたところでドリンクの量は増えませんよ」とビックリするようなことを言われるから気を付けよう…みたいな「ライフハック的な技術(テクニック)」もあります。
このコラムでは、日々の取材等で知り得た最先端技術の話から、先ほどの「ドリンク氷抜き」のような、筆者以外にはほとんど役に立たない無駄話的な「辺境技術(技術の端っこ)」的な話題をランダムで取り扱っていきたいと思っています。
ちなみに、連載タイトルのバビンチョは、前出のOh! MZとかOh! Xで連載タイトルに付けていたキャッチコピーです。いわゆる精神的続編です。
元ネタは「まんがはじめて物語」に出てくるタイムトラベルが出来るピンクのモグラ的な生き物「モグタン」が叫ぶ魔法の呪文です。
実は、ほんのつい最近知ったのですが、「まんがはじめて物語」の主題歌の歌詞字幕によると、モグタンは「バビンチョ」ではなく「バビッチョ」と叫んでいるらしく、ずっと聞き間違いだったことが、この連載開始前に判明しました。すみません、連載開始して最初のトリビアを序文で披露してしまいました。
ちなみに、この後の、本文は「ですます」調ではなく「だ、である」調になります。バビンチョ!
いまさらだけどApple M3プロセッサについて見ていく
第1回は、担当編集者からリクエストを頂いた、Appleが同社製品に採用を進めているプロセッサブランド「M3」シリーズの解説だ。
筆者は、ヘビーiPad Proユーザーにもかかわらず、なぜかApple系プロセッサの解説をほとんど依頼されたことがないので、今回は、結構レアな取り組みとなっている。
2023年10月30日、Appleは同社のノートPCの新製品「MacBook Pro」を発表した。その搭載プロセッサは、発表前から予測されていたとおり「M3」と言う名称であった。
M3プロセッサの製造プロセスは、量産プロセッサの製造ラインとしては最先端のTSMCの3nmを採用。製造コストは相応に高いはずだが、Appleプラットフォームのユーザーは、高価なプロセッサが搭載された製品であっても、ちゃんと継続的に買ってくれる強い忠誠心があるので問題なし。こうしたエコシステムとブランディングができあがっているのは、Appleプラットフォームならではの特異性であり、他のメーカーがうらやむポイントとなっている。
このM3プロセッサはどのような製品なのかを改めて見ていくことにしたい。
いちおう、下記にM3までのMシリーズ・プロセッサの主要スペックを、筆者なりの推測値も交えてまとめた表を下記に示すので、これを見ながら記事を読み進めていってほしい。
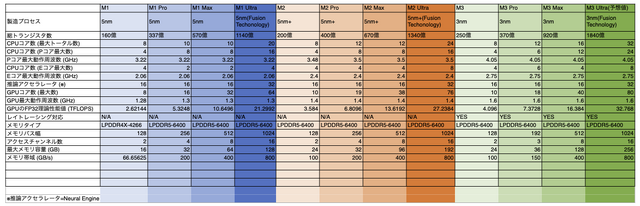
M3はM2からどう変わった?
歴代のMシリーズ同様に、今回も、M3プロセッサは無印で基準モデルの「M3」とその上位の「M3 Pro」「M3 Max」の3種類で構成される。上で示した表には、まだ発表されていない「Max」系Mシリーズプロセッサを「Fusion Technology」で繋ぎ合わせる「M3 Ultra」を「出たらこんな感じ?」という想定で書き込んでしまっている点についてはご了承いただきたい。
「M3」「M3 Pro」「M3 Max」、これら3種類は、多くのプロセッサメーカーが行っているような「同一ダイ(チップ)の特定ロジック領域を無効化して製品化」されたもののではなく、3種類、それぞれのダイを個別に製造している。この部分は冒頭で触れたようなAppleの"特異"なエコシステムだからこそ実現し得た偉業だともいえる。

▲「同一ダイ(チップ)の特定ロジック領域を無効化して製品化」されたものではなく、「M3」「M3 Pro」「M3 Max」の3種類、それぞれのダイは個別に製造されている
前出の表を見ると、プロセスルールの微細化でトランジスタ数は増えていることが分かるが、その増加率はM2→M3で+25%、M2 Max→M3 Maxで+37%といったころで、おそらく「ダイサイズはほぼそのまま」で物理設計がなされたのだと推察される。これは、ノートPCが主戦場なAppleにおいては、筐体の廃熱性能(熱設計)を大きく変えられない事情を踏まえれば納得のいく話ではある。
二桁nmプロセス時代は(たとえば14nm→10nmのように)、プロセスノードが一世代進むと単位面積あたりの2倍のトランジスタを集積できた。
(14nm÷10nm)²=1.96
(面積比の計算のために二乗している)
ところが、一桁nm台(たとえば7nm→5nmや、今回の5nm→3nm)に突入してからは鈍化し、トランジスタ密度はノード値の対比率に近い値に比例するようになった。
(5nm÷3nm)=1.66
今回のM2→M3では、トランジスタ増加率がこの値を下回っているので、ダイサイズは大型化されていないことは明白である。
それと、M3プロセッサでは、大容量キャッシュを搭載したので、これもトランジスタ増加率を下げている一因となっている。プロセスノード一桁台に突入してからはキャッシュメモリ(SRAM素子)のスケーリング(小型化)がほとんど進んでいないのだ。そう、詳細は後述しているが、今回のM3プロセッサでは巨大な「ダイナミックキャッシュ」(L3キャッシュ)を搭載している。このため、プロセスノードが進んだ割には搭載トランジスタ数がそれほど増えていないのだろう。
初代のM1プロセッサが、当時の最新技術を贅沢に活用した「超欲張り仕様で高性能なオールインワン・プロセッサ」で、インパクトがでかすぎたこともあって、事実上のマイナーチェンジであったM2はいわずもがな。今回のM3も「プロセスノードが進んだ割には想像範囲内の順当な性能強化に留まったな」といった印象がある。
たとえば、M2 Pro→M3 Proにおいてはトランジスタ数が-8%と減少しているのが興味深い。M3 ProはCPUの高性能コア(Pコア)を8コアから6コアへと減らし、高効率コア(Eコア)を4コアから6コアへと増やし、さらにGPUのコア数を削減させるという、ドラスティックな構成変更の手が入っている。メモリインタフェースも256ビットから192ビットへと削減され、これに伴いメモリ帯域も先代M2 Proよりも低下させれられた。トランジスタ数8%減はこの構成変更の影響を反映したものだろう。
結果、M3 Proは、動作クロック向上の恩恵で性能自体は微増しているが、その開発コンセプトは性能強化重視ではなく、消費電力対性能(Performance Per Watt)に重きを置いたものに違いない。
しかし、これもある種、仕方がないことなのだ。最新プロセスで製造するプロセッサは、コストが掛かる割には歩留まりが芳しくない。なので、どのプロセッサメーカーも、最新プロセスで作る初号プロセッサは、大型サイズでのチップ製造を避けたり、あるいは大規模なアーキテクチャ変革を行わないのが常だ。おそらく、M1の時に行ったような革新的なアーキテクチャで攻めてくるのは次のM4の時なのではないか……と筆者は想像している。
M3プロセッサに搭載されたGPU、3つの新機能
先進のREエンジンをカプコンがAppleプラットフォームに対応した理由は、M1プロセッサやM2プロセッサのGPUの高性能ぶりに驚いたからだそうだが、最新のM3のGPUはどうか。

▲2022年6月、「バイオハザード・ヴィレッジ」のMac版の発売をアナウンスする伊集院勝氏(カプコン・技術研究開発部技術開発室・室長)。この発表は、事実上、カプコンの新世代ゲームエンジン「REエンジン」がMetal 3対応を果たしたことを宣言するものであった。つまり、カプコンのゲーム作品のSteam版がMac対応となる可能性が見えてきたということだ
▲実際、2023年末にはiPhone及び、Mシリーズプロセッサ採用Mac向けの「BIOHAZARD RE:4」も発売された
CPUのコア数と同じで、先代M2プロセッサに対してGPUのGPUコア(演算クラスタ)数自体は「微増」に留まったが、3つほど、機能面での強化があった。
1つは待望のハードウェア・レイトレーシング・ユニット(RTU)の搭載だ。既にAppleプラットフォームの最新グラフィックスAPI「Metal 3」ではレイトレーシング(以下、レイトレ)関連APIは実装済みだったが、実際のレイトレ処理はGPGPU的なソフトウェア実装アプローチでの実践に留まっていた。
なお、GPGPUとは、Genral Purpose GPUの略。GPUの演算機能を、ラスタライズ法のグラフィックスパイプラインから利用するのではなく、汎用演算目的で利用する概念のこと。昨今の空前のAI技術の進化は、このGPGPU技術の台頭によって促進されたことは有名な話である。
これまでGPGPU的なソフトウェアアプローチで実現していたレイトレ技術が、今回のM3プロセッサ世代のGPUからは、飛ばしたレイと3Dモデル上のポリゴンとの衝突判定を行う交叉判定処理までを行うRTUが搭載されることになった。AMDやIntel、NVIDIAの最新GPUと同等の機能を持つレイトレ機能が搭載されたことの意義は大きい。
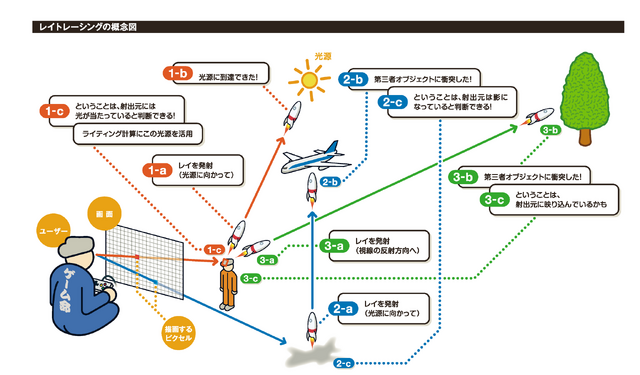
▲「レイトレーシング」とは3Dシーン内に探査機を飛ばして情報を回収しながら描画するイメージ。図解は拙著「ゲーム制作者になるための3Dグラフィックス技術 改訂3版」より引用
2つ目は新ジオメトリパイプライン「Mesh Shader」の搭載だ。Mesh Shaderは一言で言うならば、ポリゴンの増減、分割、頂点変移などを可能にするプログラマブルシェーダー機能になる。
この機能自体はWindows PCでは、2021年にDirectX12 Ultimateに標準仕様として採用済みだが、M3プロセッサ搭載機とWindows環境とでグラフィックス制作時に活用技術の整合性が取れる意義はゲーム開発側にはメリットが大きいと思う。
▲増改築が続き複雑怪奇となったジオメトリパイプラインを再編する目的で開発された「Mesh Shader」。この技術はもともと、2018年、NVIDIAに、GeForce RTX 20シリーズの発表時に提唱されて、のちに業界標準仕様化された
3つ目は「ダイナミックキャッシュ」機構だ。Apple側からの詳しい説明はないが、最近のAMDやIntel、NVIDIAの最新GPUが採用してきている大規模なL3キャッシュに相当するものだと思われる。
「ダイナミック」の意するところについても公式な説明はないが、従来のラスタライズ法の描画処理時と、新機能のレイトレ法の描画処理時において、それぞれの負荷に応じてキャッシュの割当比率を動的に(ダイナミックに)変える……ということだと思われる。
GPUの新機能アピールに「新キャッシュ搭載」がある理由
では、なぜ、Appleは「GPUの新機能項目」として、たかだかキャッシュメモリの増量をホットトピックとしてアピールしているのか。
ここには、AppleのMシリーズが抱える「アーキテクチャ面の課題」と「近代ゲームグラフィックスがGPUに求める性能」の都合が大きく絡んでいる。
AppleのMシリーズのプロセッサ達はCPUとGPUが限られたメインメモリの帯域を奪い合うアーキテクチャを採用している関係で、可能な限りメインメモリアクセスをキャッシュアクセスで隠蔽したい強い思惑がある。
MシリーズのGPUは、まとまったZバッファを確保せず、16×16ピクセルや32×32ピクセルのようなタイル単位で描画を行い、その各タイル単位のZバッファをキャッシュメモリで代替させる「タイルベースレンダリング」を採用している。
また、近代ゲームグラフィックスでは、GPUがサポートする仕様以上の動的な光源数を利用する目的で、ポリゴンだけを先に描画し、次の描画パスで画面座標系でライティング(照明演算)やシェーディング(材質演算)を行うDeferred Renderingを採用する傾向が強い。これらの処理系を高速に実践するためには潤沢なキャッシュメモリが必要になる。
そして、レイトレ処理におけるRTUの実務とは、レイの生成処理、レイを推進させるトラバース処理、そしてポリゴンとの衝突を判定する交叉判定処理の3つだが、これらは全て、レイトレ処理専用に事前定義しておく3Dシーン構造であるBVH(Bounding Volume Hierarchy)に対する探索処理に相当する。
これは事実上、メモリ空間上に展開されるデータ構造に対するランダムなメモリアクセスに相当する。これを高速化するための直接的な効能はキャッシュメモリしかないのだ。
M3のGPUに搭載された3機能のうち、どれがどうゲームに効くの?
では、GPUに搭載された3つの機能強化のうち、即効性が期待できるのはどれだろうか。
実は最も地味だと思われた「ダイナミックキャッシュ」機能だけ、となる。それはなぜか。これは既存のゲームでも、「自動的」に効果的な恩恵を享受できるからだ。
では、他2つがそうではない理由はどこにあるのか。
Mesh Shaderは機能としては魅力だが、現状、この機能を活用したゲームタイトル及びゲームエンジンはWindows PC、家庭用ゲーム機においてもまだ少ない。M2プロセッサ以前に搭載されていないことも重大なポイントだ。
いずれにせよ、直近ではM3プロセッサ専用に開発されたゲームでも登場しない限り、積極的な活用は期待できないだろう。
また、Mesh Shaderとはあくまでプログラマブルシェーダーなので、自動で何かが享受できる機能ではない。この機能を活用するためには、ゲーム(あるいはゲームエンジン)側が管理している3DモデルをMesh Shaderで駆動するための最適なデータ構造として構成し直し、なおかつこれを効果的に描画するサブシステムの構築が必要になる。
つまり、プログラマーだけの頑張りだけでの対応は難度が高く、3Dモデルのデータ作り段階から準備が必要になる。つまり、Mesh Shader活用版のゲームと非活用版のゲームとでジオメトリサブシステムを作り分けないといけないのだ。技術難度はともかく、ゲームの開発現場では開発工数が増えることの方が問題視されている。

▲2023年10月に発売された大作ゲーム「Alan Wake II」はいまだ多くないMesh Shader活用がアピールされたタイトルである
待望のRTUも、GPUコア数が先代比で微増程度のM3シリーズでは、リアルタイムに近いレイトレ性能は期待できないだろう。というのもRTUが行うのは「放ったレイとポリゴンの衝突が起きたか否か」の判定を行う「交叉判定」まで。最終的なピクセルの色までを決定づけるライティングやシェーディングの処理は、RTUからGPUコア内のプログラマブルシェーダーユニットに外注されることになるからだ。
それらは、従来のラスタライズ法の描画にも動員されるので、M3のGPUではレイトレを本格活用するにはどう考えてもプログラマブルシェーダーユニットの絶対数が足りない。おそらくM3シリーズのRTUは、ゲーム向けではなく、映像作品制作向けのレイトレ処理時間の短縮目的を想定したもの……と考えるのが自然かもしれない。
と、今回はここまで。連載第1回は、Appleがらみの「技術の端っこ」話をさせていただいた。
また、いずれこのAppleがらみの話題をお届けすることがあるかもしれないが、次回は未定ということで。バビンチョ!



