









1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第39回目は、生成AI最新論文の概要5つを紹介します。
生成AI論文ピックアップ
実写動画をアニメ映像に変換など、動画をプロンプトで高品質に編集できるAIモデル「FRESCO」
この研究では、事前学習済みの画像拡散モデルを、追加学習なしで動画変換に適用できるゼロショット手法「FRESCO」を提案しています。入力動画が与えられた場合、内容と動きを保持しながら、目標とするテキストプロンプトに基づいて再レンダリングします。例えば、実写動画をアニメ調にしたり、登場人物の外見を変えたりすることができます。
FRESCOは、入力動画のフレーム内空間的対応とフレーム間時間的対応の両方を活用することで、高品質で一貫性のある動画変換を実現します。具体的には、U-Netのデコーダ層の特徴量を入力動画との整合性が高くなるように最適化する「FRESCO-aware feature optimization」と、Self-Attentionを入力動画の空間的・時間的対応に基づくAttentionに置き換える「FRESCO-guided attention」という2つの処理を導入しています。
これらの適応処理を組み合わせることで、生成される動画の一貫性を大幅に改善できることが示されました。また、FRESCOはControlNetやLoRAなどの既存の画像操作技術との互換性が高く、柔軟なカスタマイズが可能です。長時間の動画変換では、キーフレーム選択と補間を用いて効率化を図っています。
実験により、FRESCOが従来のゼロショット手法と比べて、編集精度と時間的一貫性の両面で優れていることが示されました。FRESCOは、動画の色付けなど、他のテキストガイドの動画編集タスクへの応用も期待されます。


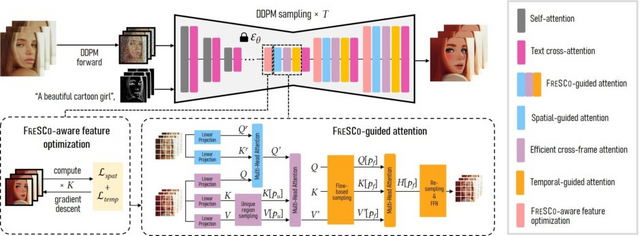
FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation
Shuai Yang, Yifan Zhou, Ziwei Liu, Chen Change Loy
Project | Paper | GitHub
既存モデル同士を掛け合わせて新しい高品質LLMを自律的に作り出す手法、AIベンチャー「Sakana AI」が開発
大規模言語モデル(LLM)の開発において「モデルマージ」と呼ばれる手法があります。これは、既存のモデルを掛け合わせて新たな高性能な基盤モデルを作る技術です。追加の学習データやコンピュータリソースを必要とせず、コストを抑えられるのが大きな利点です。
しかし現状、モデルマージには専門家の直感と経験に頼る部分が大きく、その可能性を十分に引き出せていません。多種多様な言語モデルが公開される中、人間の直感だけでは最適な組み合わせを見つけるのは困難だからです。
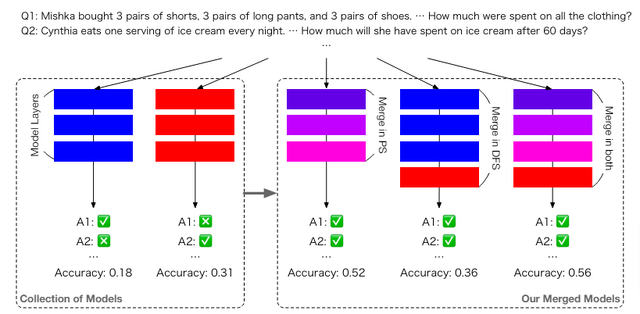
この問題を解決すべく、日本に拠点を置くAIベンチャー「Sakana AI」の研究者らは、モデルマージに進化的アルゴリズムを組み合わせた手法を開発しました。コンピュータが自動的にモデル同士を統合して最適なモデルを作り出すアプローチです。何世代もの統合を自律的に繰り返すことで、人に頼る従来の方法では難しかった、効率的に高品質なモデルを作り出すことに成功しました。
この手法の特徴は、モデルのパラメータだけでなく、推論時のデータの流れ方も最適化する点にあります。例えば、日本語の言語モデルに英語の算術モデルを統合することで、日本語で数学問題を解くモデルを作れます。
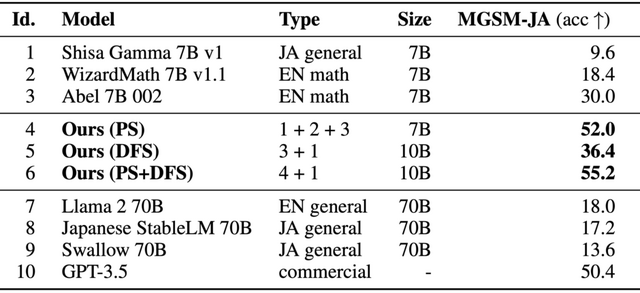
実際に、日本語LLM (7B) と英語の数学モデル(7B)をマージして日本語大規模言語モデル 「EvoLLM-JP」を作成しました。評価実験の結果、EvoLLM-JPは70B規模の日本語LLMを日本語の数学問題で上回る性能を示し、また数学問題以外の日本語タスクでも高い汎用性を発揮しました。さらに、同様の手法で日本語と画像認識モデルを統合することで、日本文化に特化した質問応答ができる日本語視覚言語モデル「EvoVLM-JP」の開発にも成功しています。
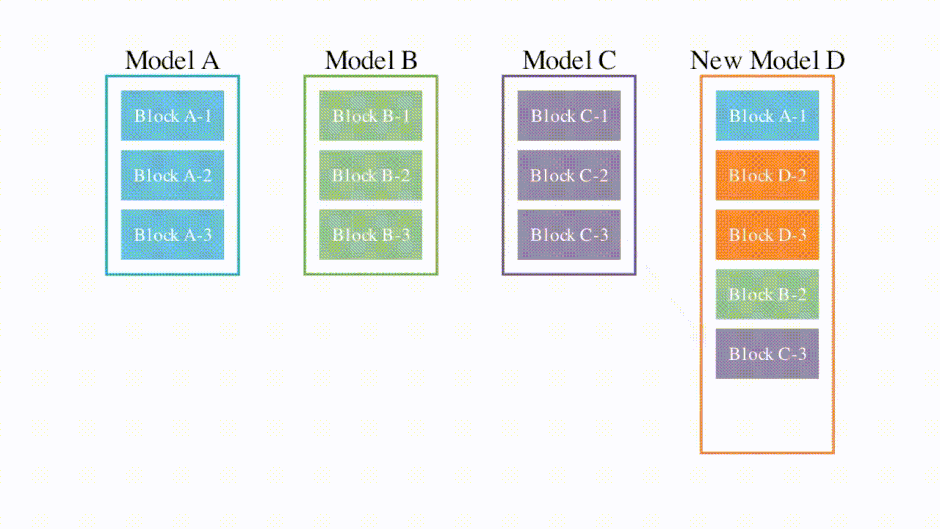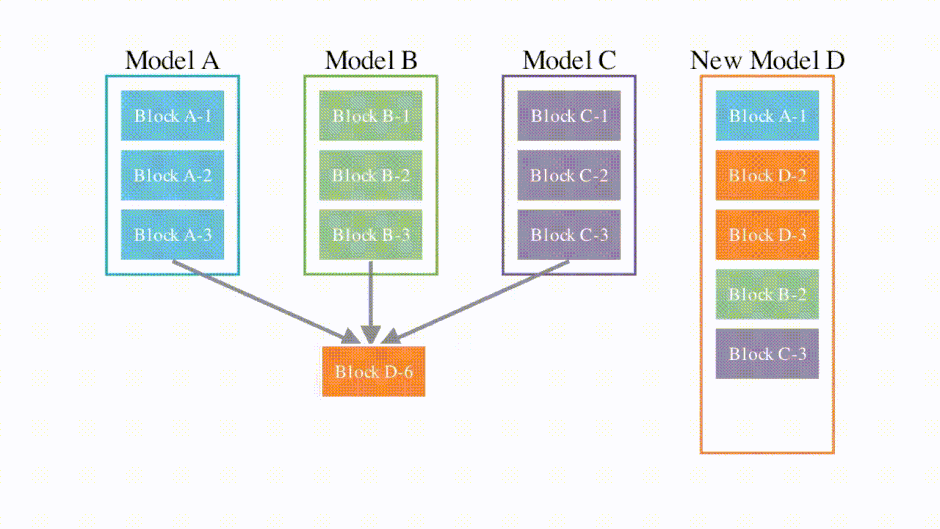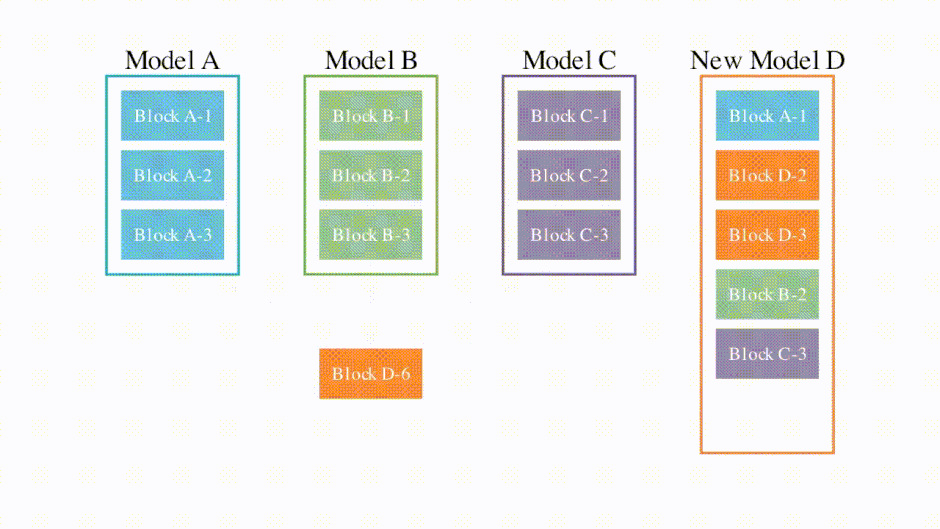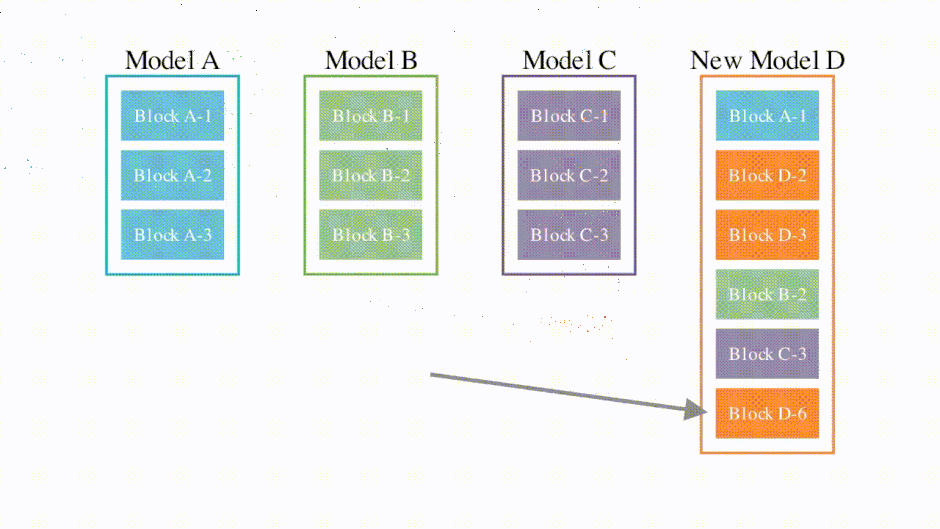


Evolutionary Optimization of Model Merging Recipes
Takuya Akiba, Makoto Shing, Yujin Tang, Qi Sun, David Ha
Paper | GitHub | Demo | Blog
高品質なステレオ音楽を生成できるボコーダー「MusicHiFi」をAdobeなどが開発
拡散モデルでは通常、音声の表現(メルスペクトログラムなど)を生成し、それをボコーダーを用いて音声に変換します。しかし、従来のボコーダーは低解像度のモノラル音声しか生成できず、限界がありました。
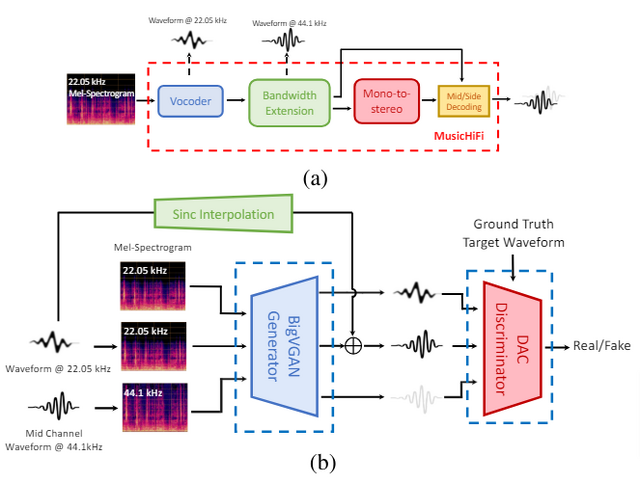
そこで、Adobe Researchなどに所属する研究チームは、新しい高速高音質ステレオボコーダー「MusicHiFi」を提案しました。MusicHiFiは、3つのGAN(Generative Adversarial Network)を用いて、既存の低解像度音声や生成されたメルスペクトログラムから高音質のステレオ音声を生成します。
MusicHiFiは、メルスペクトログラムベースの音楽生成モデルに組み込むことで音質を高めたり、低解像度の録音の音質改善やモノラル音楽のステレオ化に応用できます。
MusicHiFiの処理は、以下の3段階で行われます。まず、ボコーダーモジュールが低解像度のメルスペクトログラムから低解像度の音声波形を生成します。次に、帯域拡張モジュールが低解像度音声を高解像度音声にアップサンプリングします。最後に、モノラルからステレオへの変換モジュールがモノラル音声からステレオ音声を生成します。
各段階で、統一されたGANベースの生成器と識別器のアーキテクチャを採用しています。これにより、各モジュールの処理を効率化しながら、高品質な音声生成を実現しています。特に、帯域拡張モジュールでは、高解像度音声を生成する際に、低域の情報が失われることを防いでいます。モノラルからステレオへの変換モジュールでは、音の奥行き感を制御可能にしています。
客観評価と主観評価の実験により、MusicHiFiは従来手法と同等以上の音質を実現しながら、はるかに高速な処理速度を達成することが示されました。また、ステレオ感の制御性も優れていることが分かりました。
MusicHiFi: Fast High-Fidelity Stereo Vocoding
Ge Zhu, Juan-Pablo Caceres, Zhiyao Duan, Nicholas J. Bryan
Project | Paper
900FPS以上で写真のような高品質な大規模3Dシーンをリアルタイム生成する「RadSplat」をGoogleなどが開発
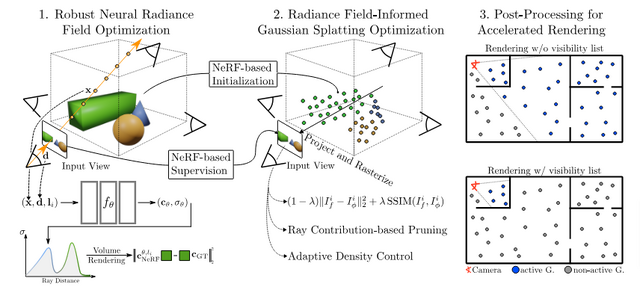
近年、ニューラルレンダリングの分野では、写真のような高品質な3Dシーンをリアルタイムで生成するための研究が盛んに行われています。特に、Radiance Fieldを用いた手法は、野外で撮影された大規模なシーンにおいても高品質な合成が可能であることが示されています。しかし、これらの手法は、ボリュームレンダリングによる計算コストが非常に高いという問題を抱えています。
一方、3D Gaussian Splattingを用いた手法は、ラスタライゼーションを利用することでリアルタイムレンダリングを実現できますが、最適化が不安定で、複雑なシーンでは品質が低下してしまうという課題があります。
これらの問題を解決するために、「RadSplat」と呼ばれる新しい手法が提案されています。RadSplatは、Radiance Fieldの安定性と3D Gaussian Splattingの高速性を組み合わせることで、複雑なシーンに対してもロバストかつ高速なリアルタイムレンダリングを実現します。
具体的には、まず、Radiance Fieldを事前学習し、点群ベースのシーン表現の最適化の際の事前知識として利用します。これにより、最適化の安定性が向上し、より高品質なシーン表現が得られます。次に、新しいプルーニング手法を導入することで、全体の点の数を削減しつつ高品質を維持することに成功しました。さらに、テスト時に新しいフィルタリング手法を適用することで、レンダリングをさらに高速化し、大規模な部屋サイズのシーンにもスケールできるようになりました。
実験の結果、900FPS以上という驚異的な速度でレンダリングを行いながら、複雑なシーンにおいて従来手法を上回る高品質な合成を実現しました。特に、大規模シーンでは、最先端の手法であるZip-NeRFと同等以上の品質を、3000倍以上高速にレンダリングできることが明らかになりました。これは、RadSplatが、ニューラルレンダリングの実用性を大きく前進させる画期的な手法であることを示しています。
高速かつ高品質なリアルタイムレンダリングが可能になったことで、ゲームやバーチャルリアリティなどの分野において、よりインタラクティブかつ没入感の高い映像体験の実現が期待されます。

RadSplat: Radiance Field-Informed Gaussian Splatting for Robust Real-Time Rendering with 900+ FPS
Michael Niemeyer, Fabian Manhardt, Marie-Julie Rakotosaona, Michael Oechsle, Daniel Duckworth, Rama Gosula, Keisuke Tateno, John Bates, Dominik Kaeser, Federico Tombari
Project | Paper
Soraの再現を目指すオープンソースText-to-Videoモデル「Open-Sora 1.0」がリリース
OpenAIが開発した動画生成AIモデル「Sora」は、多数のText-to-Videoモデルの中でも突出した性能を示し、世界中から注目を集めています。そんな中、HPC-AI Techの開発チームは「Open-Sora 1.0」という、Soraの再現を目指したオープンソースモデルを公開しました。
Open-Soraは、データ処理から学習の詳細、モデルのチェックポイントに至るまで、Soraの学習プロセス全体を模倣するように網羅しています。開発チームは、Open-Soraのモデルアーキテクチャ、学習済みモデルのチェックポイント、学習とデータ準備の詳細、デモ動画、チュートリアルなどを全てGitHubで公開しており、今後もOpen-Soraの最新情報を継続的にアップデートしていく予定だと述べています。
Open-Soraは、Diffusion Transformerアーキテクチャをベースに、時間方向のAttentionを追加して動画生成に対応しました。学習は、大規模な画像事前学習、動画事前学習、高品質動画データでのファインチューニングの3段階で行われ、効率的に高品質な動画生成を実現します。
ビデオデモの例として、海岸の岩に打ち寄せる海の映像、山の滝、サンゴ礁でゆっくり泳ぐ海亀、タイムラプスで撮影された星空の映像などが解像度512×512の2秒ほどの長さの生成作品で紹介されています。現在のOpen-Soraは40万件の学習データでしか学習されていないため、今後さらに改良していく計画です。

Open-Sora: Democratizing Efficient Video Production for All
HPC-AI Tech
GitHub | Blog |Gallery | Hugging Face





