10秒の歌声オーディオデータがあれば、本人そっくりのリアルタイム歌唱ができるという「Vocoflex」。ベータテスターの申し込みをしていたのですが、ついに試用できたので、そのファーストインプレッションをお届けします。
筆者は2013年に他界した妻の歌声を元にした「妻音源とりちゃん」というプロジェクトをここ10年以上続けており、過去の音声データから新しい歌を引き出すことについては強い関心を抱いています。最初はUTAU-Synthを使った音素接続、生成AIが登場してからは、Diff-SVC、RVCと、新しい技術を導入して妻の歌声を再現することに努めてきました。

現在使っているRVCは、1時間分の歌声(本人歌唱の3曲分と、UTAU-Synthで生成した楽曲、そしてビデオなどに収録された音声など)を学習して作った音声モデルで、1曲まるごとの声質変換に数秒もかからず、音質そのものにも大きな不満はありません。これだけでも十分なくらいなので、1年以上、RVCでの運用を続けてきました。
RVCも低レイテンシーで使うことは可能です。VC Clientなど、GPUなしでも動作するアプリを使えば、MacBook AirなどのノートPCで動かすことは可能。ですが、低遅延とはいっても、遅延を少なくすればするほど音質は低下しますし、そもそも自分で歌ったものが声質変換されて流れるまでの時間は大きく、リアルタイムでの声質変換歌唱は不可能でした。
そこに、45msecという、演奏者がなんとかなるレベルの低レイテンシーを実現したというVocoflex登場の話を聞き、これはライブでも使えるのではないかという希望のもと、ベータテスターを申し込んだというわけです。
声質はちゃんと変換できるのか?
ただ、まずは音質変換がちゃんとできるかどうかが問題です。本人歌唱に近いものでなければ、意味がありません。
そこで、妻の2種類の音源をVocoflexに読み込ませて試してみました。
1982年頃、MZ-80K2Eという8ビットコンピュータ、それに接続するドラム音源などを内蔵したシーケンサー(まだMIDIはなかった)CMU-800を使い、妻の実家のアップライトピアノ、自分のエレピ、ストリングシンセなどで多重録音したものからAI音源分離ソフトのUVR5でボーカルトラックを抜き出し、それをVocoflexで読み込ませるというかなりハードな試みです。
次の動画の最初の音源が1982年のオリジナル歌唱。次が、Vocoflexで筆者が歌ったものをリアルタイム声質変換したものです。元の歌唱データはかなり劣悪なのに、意外にちゃんとした声になっているのが驚きです。
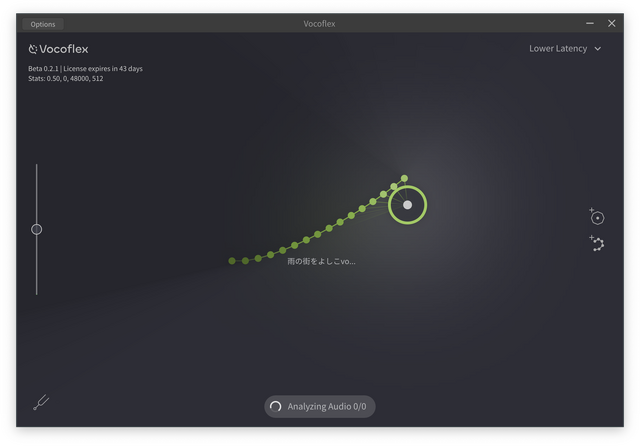
3番目には、2012年にiPhoneのGarageBandでEarPodsを使って録音した妻のボーカルトラック。4番目には、その音声ファイルを読み込ませてVocoflexで歌唱したもの。こちらはさらにクリアな音質になっています。少し抑えた感じの歌い方ですが、本人性は感じられるものになっており、RVCで生成したものよりもノイズが少なく、音質も良いのに驚きます。学習データは非常に少ないはずなのに。
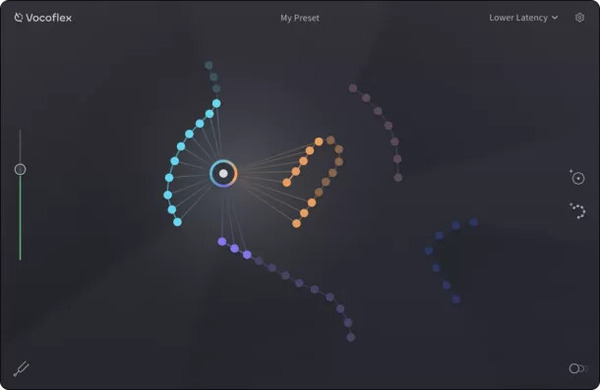
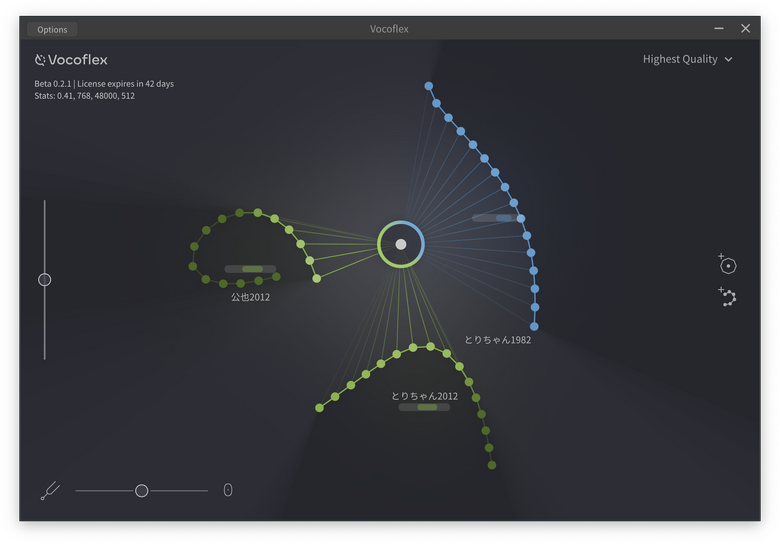
5番目に入れたのは、1982年と2012年のAIモデルをミックスしたものです。Vocoflexは画面のポインタを動かすことで、この2つ(あるいはそれ以上)をミックスしたり切り替えたりをリアルタイムでできるのです。本人の歌声にはミックスした方が近いように感じます。歌うパートや表現に応じてポインタを動かせば一本調子を避けることもできます。パラメータの数字やスライダーでをいじるのではなく、直感的に操作できるのはまさにライブ向きと言えるでしょう。
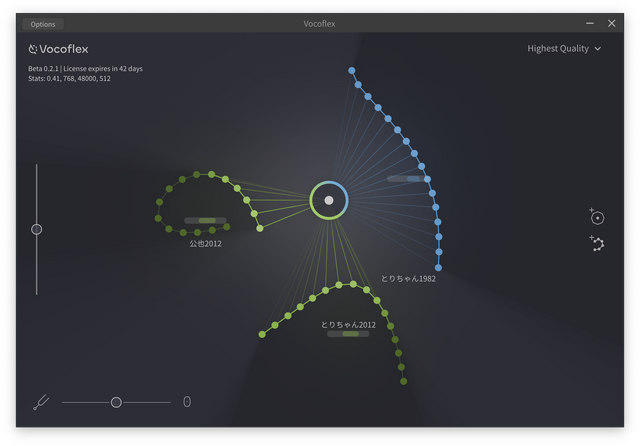
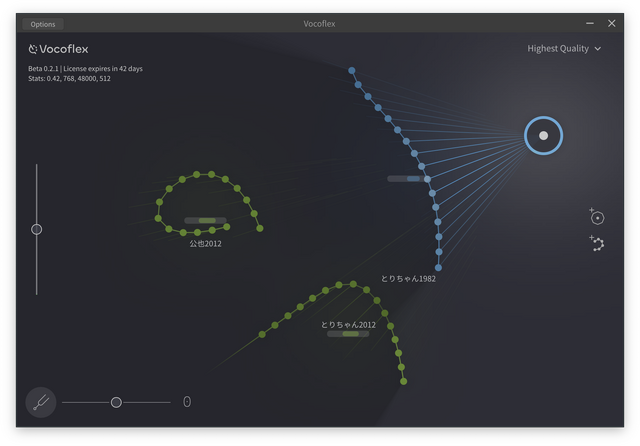
最後に入れたのは、筆者の歌唱データ。このガラガラの声がちゃんとリアルタイムで女性の歌声に変換できるのです。筆者は数年前にひどい風邪をひいてから声がガラガラになって以前の美声が出せなくなっているのですが、これも2012年の音声データを元にした声質変換すれば、「昔の声で出ています」が可能になります。さらに遡って、学生時代の歌声もボーカル抽出すればできます。これはだいぶ声が衰えてしまったプロの歌手においても、全盛期のみずみずしいトーンで歌うといったことが可能になります。
歌手にとって声帯の劣化は大きな問題です。酒、ドラッグ、タバコにより声が変わってしまうだけでなく、長時間の歌唱による負荷、年齢を重ねることによる経年劣化から逃れることは不可能。しかし、良かった時代の歌声が少しでも残っていれば、現在のテクニックでそれを活かすことができるのです。
ライブで使えるレベルの歌声変換技術はそれだけ大きな意味があるのです。
1982年に自分が歌った曲のオーディオデータが残っていたので、これをAIで音源分離し、Vocoflexに学習させてみました。
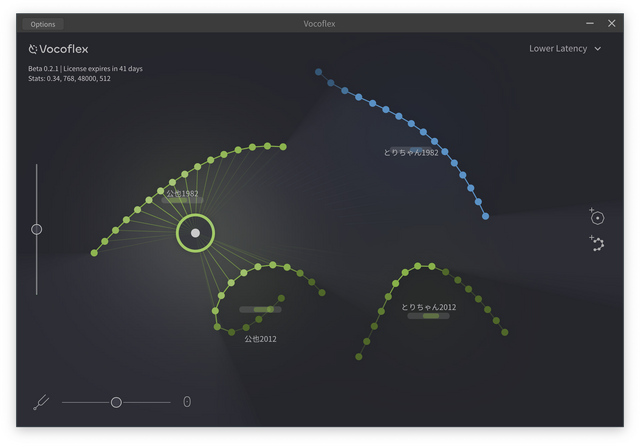
▲1982年と2012年の自分の歌声をミックスして、2024年の自分が歌っている
これもカセットに録音されたデータを無理やり分離したものなのですが、なかなか良い品質に仕上げてくれています。
レイテンシーは大丈夫なのか?
気になるのはレイテンシーが許容範囲かどうか、です。耳に自然に入ってくる自分の声に対し、変換した声が遅れて入ってくるわけなので、その遅延の程度によっては発話・歌唱が困難なことがあります。
Vocoflexの45msecという数字は、Lowest Latency、つまり音質的には最も低いもので計測したものであり、最高品質にすると、100msec超えということになります。
レイテンシーについては使う楽器によって体感する遅延が異なります。例えばリモート環境でセッションを行うヤマハのSYNCROOM(旧NETDUETTO)では、300km離れたベースプレーヤーとのセッションでも20msecくらいで、演奏上は全く問題を感じませんでした。一方、30msec程度と言われているBluetooth MIDIキーボードで演奏すると、もっさり感があり、遅延を録音後に調整したりしています。
じゃあボーカルはどうかというと、ケースバイケースとなってしまいます。バラードなどのゆったりした歌であれば歌手もオーディエンスもあまり違和感を覚えないでしょうが、速いパッセージが続く連続し、さらに他のパートとのユニゾンがあるような歌だと遅延が致命的なものになると思います。常時突っ込み気味に歌うことである程度は解決できるかもしれませんが。
Vocoflexで自分の声と出音で試してみましたが、これならなんとかなりそうな感じはしています。Lowest Latencyでもちゃんと本人っぽい声質なので。
一度スタジオに入ってバンドメンバーとやってみるか、ライブに実戦投入するなどして検証する必要がありますね。楽しみです。
ここまで声質が良いと、RVCを使う理由はなくなってしまいます。RVCは学習のステップ数で最適解を探すくらいしか調整しようがないのに対し、Vocoflexは複数音源のモデルをミックスすることにより、直感的に声質の微調整ができるので、本物により近づけることが可能。
年末ライブでは、Vocoflexを使って妻音源とりちゃん[AI]のリアルタイム歌唱を友人たちに披露できるはずです。しかし、それを駆動するのは自分の歌声なので、現在の声も大事にしないといけないですね。