


「年末のライブなんですが、今回、とりちゃんにコーラスをやってもらいたいと思っていて、リアルタイムで歌うことってできないですか?」
かつて妻が所属していて、今は自分が妻のパートであったキーボードを演奏している学生時代から続くバンドのリーダーからそんなメールが届いたのは2週間ほど前のこと。
2013年に他界した妻の歌声を元にしたバーチャルシンガー「妻音源とりちゃん」は、2013年9月の追悼コンサート以来、コロナ禍の時期以外はほぼ毎年、妻の歌声でライブに参加していたのですが、今回はリアルタイムで、という新たな課題が加わりました。
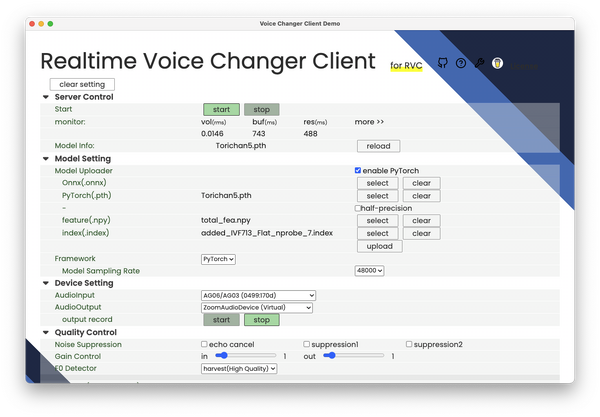
AIでリアルな発声ができるようになったとはいえ、バンドの演奏に合成音声をシンクロさせるのは至難の業。最新版の妻音源とりちゃん[AI]ではRVCという、低レイテンシーでのボイスチェンジャー機能が可能な技術を使っているとはいえ、ライブ演奏で実用に足るレベルかというと不安が残ります。安全策を考えると、サンプラーにいくつかのフレーズを割り当てておいてポン出しするということになるのですが……。
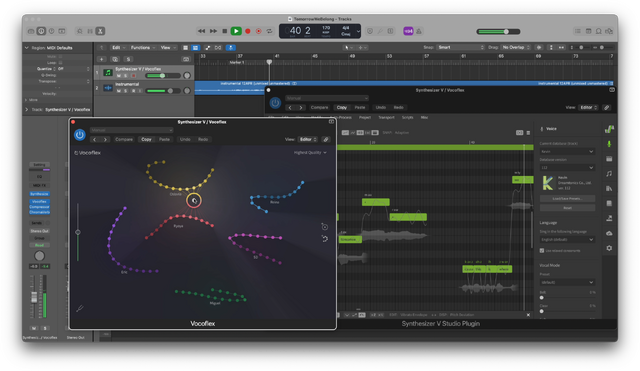
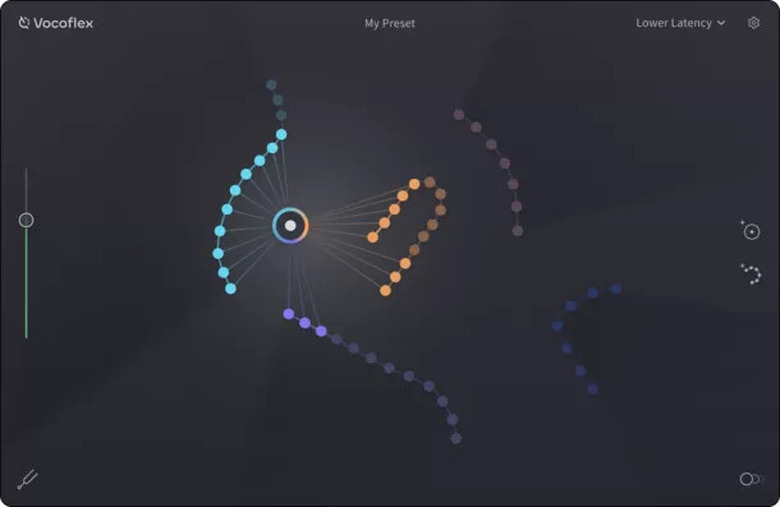
どのサンプラーにしようかと思案していたところ、歌声合成ソフトのSynthesizer Vや音声合成ソフトのVOICEPEAKを開発しているDreamtonicsから「Vocoflex」という新製品のニュースが飛び込んできました。
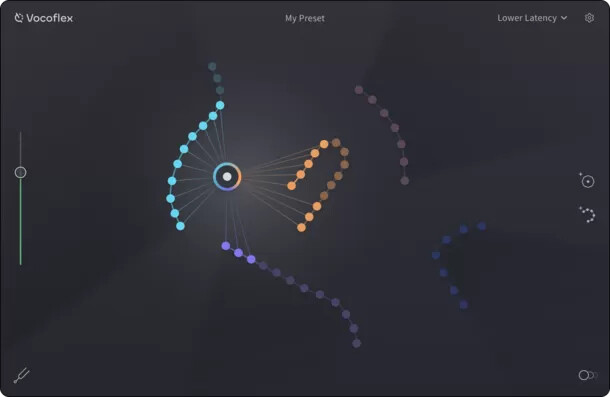
何か発表があると予告はされていたので、AIベースの何かだろうなと期待はしていたのですが、簡単にいうと、10秒間歌ったデータがあれば、その声を学習して、リアルタイムで音声変換できるようになる、というものです。
似たような技術はいくつかあります。例えば、マイクロソフトが発表したVALL-E X。OpenAIが発表したVoice Engineも短時間で学習した音声を再現できる、同種の技術です。それなりのサンプルの長さ(20分から1時間分)と学習時間(数十分から数時間)とGPU資源がかかるとはいえ、リアルタイムボイチェンという意味では筆者が常用しているRVCにも近いです。RVC以外のAI音声モデルを使えるVC Clientというボイスチェンジャーもまた同様のことができます。
Vocoflexは、4つあるモードのうち一番リアルタイムに近いもので45msecくらい。ゆっくり目の曲であったり、リードボーカルでなくてコーラスであればおそらくなんとかなるレベルの応答性の良さです。
筆者が使っているRVCでもおそらく近いことはできるでしょうが、レイテンシはおそらく数倍は大きいようです。やったとしても、歌声としては厳しい。一方、Vocoflexは歌声に最適化しているということで、リアルタイムでの使用においては優位であることが期待できます。リアルタイムでの変換を聞いてみましたが、破綻は感じられませんでした。
さらに、声質や、その変化の具合を調整できるようなので、学習した声のモデルをさらにオリジナルに近づけることも(遠ざけることも)可能です。
これはライブで妻の歌声でコーラスするのに最適じゃないですか。
ベータ版テストが開始されているので、申し込んでみました。二次審査まであって、そこで通れば使えるようになるようです。

年末のライブに間に合うように、使えるようになるといいなあ。
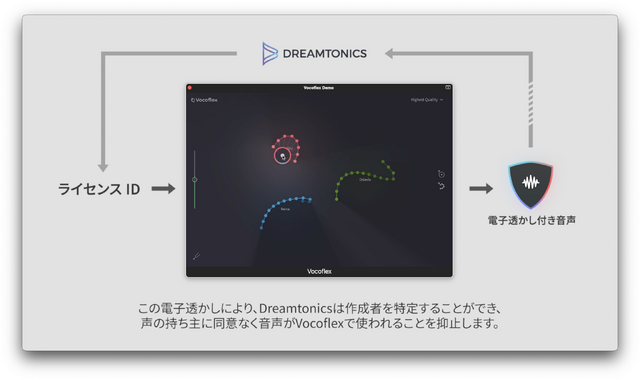
複数の人だったり、ぜんぜん違う楽器音とモーフィングさせることもできるようで、音声楽器としての可能性も大。Synthesizer V Studioとの連動もOK。なお、また、透かし技術が使われているので悪用はできないようになっているそうです。