





この1週間の気になる生成AI技術をピックアップして解説する「生成AIウィークリー」(第55回)では、1枚の完成したイラスト絵を入力に、そのイラストの制作過程のタイムラプス動画を生成する「PaintsUndo」や、画像とテキストをペアにした1コマを入力に、続きの物語を生成する「SEED-Story」などを取り上げます。
生成AI論文ピックアップ
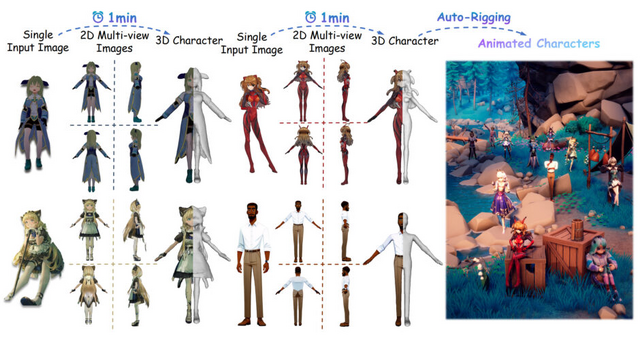
1枚の画像から3Dキャラクターを1分で生成するモデル「CharacterGen」
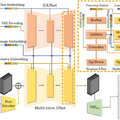
単一の2D画像から高品質な3Dキャラクターモデルを効率的に生成する新しい手法「CharacterGen」が開発されました。
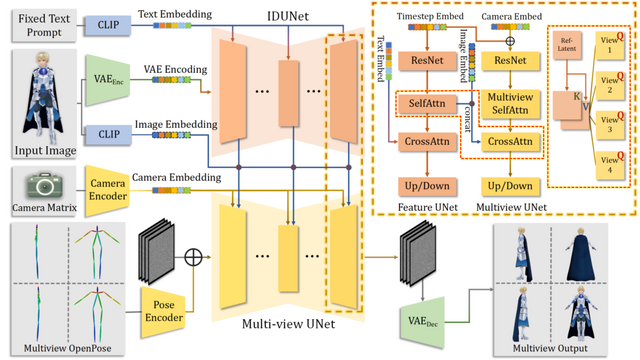
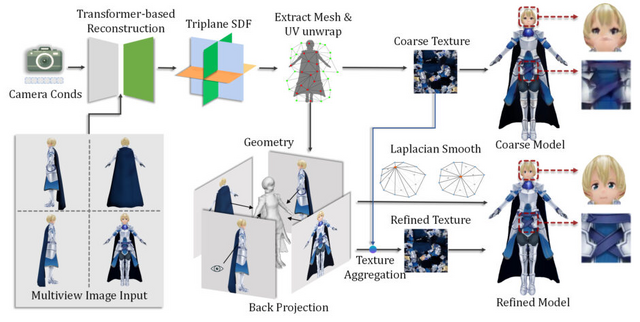
入力画像から4つの異なる視点(正面、左側面、背面、右側面)の画像を生成し、これらを用いて詳細な3Dメッシュモデルを作成します。また、生成された3Dモデルに対して高解像度のテクスチャマップを適用することで、見栄えの良い最終結果を得ることができます。
入力画像のキャラクターのポーズに関わらず、標準的な3Dモデリング用ポーズである「Aポーズ」に変換します。
この手法のトレーニングのために、研究チームは「Anime3D」という新しいデータセットを作成しました。このデータセットには1万3746の3Dアニメキャラクターモデルが含まれており、様々なポーズと視点から描画されています。
CharacterGenの処理速度は、1つの3Dキャラクターモデルを生成するのに約1分です。評価実験の結果、CharacterGenが2D画像からの3Dキャラクター生成において、品質と速度の両面で既存の手法を大きく上回る性能を持っていることを示しています。

CharacterGen: Efficient 3D Character Generation from Single Images with Multi-View Pose Canonicalization
Hao-Yang Peng, Jia-Peng Zhang, Meng-Hao Guo, Yan-Pei Cao, Shi-Min Hu
Project | Paper | GitHub
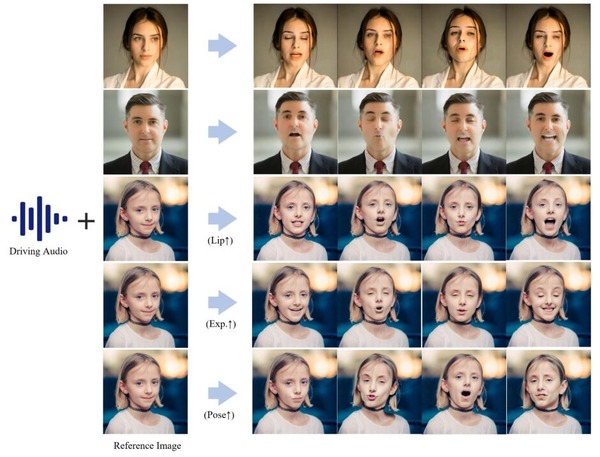
音声と静止画の顔を入力に、話している動画を生成するAI「EchoMimic」
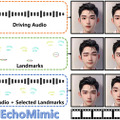
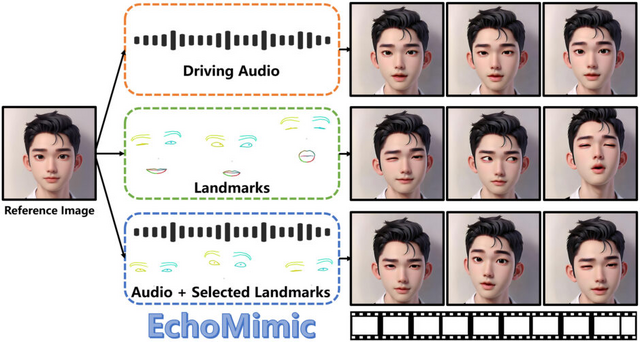
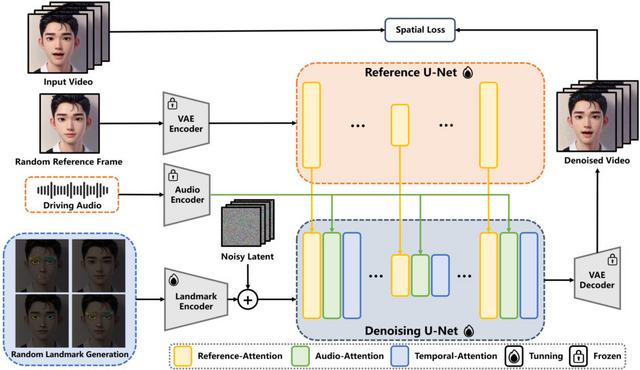
「EchoMimic」は、音声信号と顔のランドマーク情報を組み合わせることで、自然で表現豊かなポートレート動画の生成を実現します。この技術の特徴は、音声に合わせて口の動きや表情を生成できるだけでなく、顔のランドマーク情報を用いて細かい表情制御も可能な点にあります。
EchoMimicは、3つの駆動モードがあります。まず、音声駆動モードでは、入力された音声の特徴を分析し、それに合わせて口の動きや表情を生成します。音の高低やリズムに応じて、自然な口の動きや顔の表情が作り出されます。
ランドマーク駆動モードでは、顔の特徴点(目、鼻、口などの位置)を直接制御します。これにより、細かな表情の変化や個性的な動きを作り出すことができます。
そして、音声+ランドマーク駆動モードでは、上記2つを組み合わせます。音声に合わせた自然な口の動きを生成しながら、同時に選択した顔の部位を個別に制御することができます。
EchoMimicは、従来の手法と比較して、生成された動画の品質、時間的一貫性、口の動きと音声の同期性などの面で優れた性能を示しています。特に、動画の品質を評価する指標であるFIDやFVDで最高スコアを達成し、その優位性が実証されています。
EchoMimic: Lifelike Audio-Driven Portrait Animations through Editable Landmark Conditioning
Zhiyuan Chen, Jiajiong Cao, Zhiquan Chen, Yuming Li, Chenguang Ma
Project | Paper | GitHub
漫画の1コマを入力に、続きのコマを作り出す物語生成AI「SEED-Story」
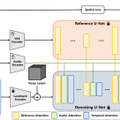
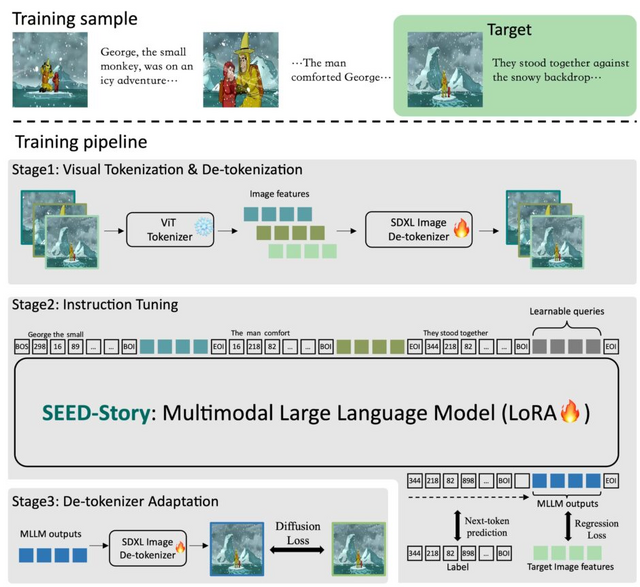
「SEED-Story」は、マルチモーダル大規模言語モデル(MLLM)を活用して長編のマルチモーダルストーリー(画像とテキストの物語)を生成します。ストーリーの開始部分となる画像とテキストを入力すると、物語テキストと文脈に沿った一貫したキャラクターやスタイルを持つ画像で最大25シーケンス(訓練時は10シーケンス)を生成することができます。
SEED-Storyは、MLLMの強力な理解能力を活用し、テキストトークンと視覚トークンの両方を予測します。また生成された画像の一貫性を高めるため、Visual de-tokenizerという手法を提案しています。さらに、効率的に長いストーリーを生成するため、マルチモーダル・アテンション・シンク・メカニズムという手法を導入しています。これにより、訓練時の長さを超える長いシーケンスの生成が可能になります。
研究チームは、マルチモーダルストーリー生成のためのデータセット「StoryStream」を作成しました。これは既存の最大のストーリーデータセットより多くの規模を持ち、より高解像度の画像、より長いシーケンス、より詳細な物語を含んでいます。
評価実験では、画像のスタイル一貫性、ストーリーの魅力、画像とテキストの整合性などにおいて優れた性能を示しました。



SEED-Story: Multimodal Long Story Generation with Large Language Model
Shuai Yang, Yuying Ge, Yang Li, Yukang Chen, Yixiao Ge, Ying Shan, Yingcong Chen
Paper | GitHub
3次元データを活用した新しい画像マッチング技術「MASt3R」
画像マッチングとは、関連する2枚の画像間で対応する特徴点を見つける技術で、3D再構成やカメラの位置推定など、多くのコンピュータビジョンタスクの基盤となっています。しかし、従来の2次元ベースのアプローチでは、極端な視点変化や照明条件の変化に対して脆弱であるという課題がありました。
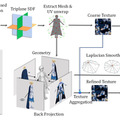
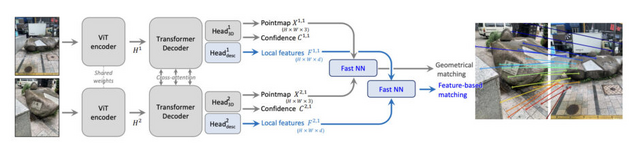
この問題に取り組むため、研究チームは3D情報を活用した新しい画像マッチング手法「MASt3R」(Matching And Stereo 3D Reconstruction)を開発しました。
MASt3Rは、DUSt3R(Dense Uncalibrated Stereo 3D Reconstruction)フレームワークを基盤としています。DUSt3Rは2枚の入力画像から3次元点群を予測する能力を持っていましたが、マッチングの精度には改善の余地がありました。MASt3Rはこの問題を解決するため、密な局所特徴マップを出力する新しいヘッドを追加し、特別な学習方法を採用しています。これにより、3D情報を活用しながら、高精度なマッチングが可能になりました。
MASt3Rの主な特徴として、極端な視点変化にも頑健なマッチングが可能になったことが挙げられます。従来の2D手法では困難だった180度の視点変化にも対応できるようになりました。また、高解像度画像に対応するため、粗から細へのマッチング戦略を採用しています。これにより、大規模な画像でも効率的に処理することが可能になります。
研究チームはMASt3Rを様々なベンチマークデータセットで評価しました。Map-free localizationデータセットでは、従来の最高性能の手法と比べて30%以上性能を向上させました。


Grounding Image Matching in 3D with MASt3R
Vincent Leroy, Yohann Cabon, Jérôme Revaud
Project | Paper | GitHub
イラスト1枚から制作過程の動画を生成するAI「Paints-UNDO」
ControlNetの開発者でもあるlllyasviel氏が、イラスト絵の描画工程を動画で表現するAI「Paints-UNDO」をGitHubで公開しました。このモデルは、完成した1枚のイラストを入力にスケッチや着彩などの制作過程をタイムラプス動画として出力します。
その名前は、デジタルペイントソフトで「元に戻す」(Windowsでは Ctrl + Z、MacではCommand + Z)ボタンを何度も押したような結果が得られることに由来しています。
スケッチから始まり、線画の作成、彩色、陰影付けといった基本的な描画技法、レイヤーの操作、画像の左右反転、色調整、さらには制作途中でのアイデア変更まで、デジタルアート制作における幅広い作業を表現することができます。
PaintsUndoはシングルフレームモデルとマルチフレームモデルの2種類で構成されています。シングルフレームモデルでは各段階の画像を生成し、マルチフレームモデルでは2つの像間の中間フレームを出力します。これらを組み合わせることで、25秒程度の制作過程動画を生成します。






















![カルピス CALPIS 濃いめ 490ml×24本 [カルピス][乳酸菌][アサヒ飲料] image](https://m.media-amazon.com/images/I/31B168zai0L._SL160_.jpg)