






1枚の画像とプロンプトから短いアニメーションを生成する動画生成AI「Luma Dream Machine」に、2枚の画像を入力として、その間の映像(中割り)を生成する機能「Keyframes」が実装されました。この新機能は非常に強力で、始めの画像から終わりの画像までをできるだけ自然に繋げるアニメーションを生成します。特に、似たような画像同士の場合、滑らかな中割り映像を作り出します。

Googleがオープンな言語モデル「Gemma 2」を開発者向けに公開しました。90億パラメータと270億パラメータの2サイズを提供しています。
さて、この1週間の気になる生成AI技術をピックアップして解説する「生成AIウィークリー」(第53回)では、生成する動画時間の延長や無音ビデオに適した音を生成するなど動画AIに関する内容が盛りだくさんです。
生成AI論文ピックアップ
既存のAIが生成する動画の時間を長くするモデル「ExVideo」、Stable Video Diffusion生成動画を5倍以上の長さに拡張>
言語より視覚に重きを置く、オープンなマルチモーダル大規模言語モデル「Cambrian-1」はGPT-4VやGemini Proと同等レベル
既存のAIが生成する動画の時間を長くするモデル「ExVideo」、Stable Video Diffusion生成動画を5倍以上の長さに拡張
動画生成技術が急速に進歩する中、長時間の動画を生成することはまだ大きな課題となっています。この問題に取り組むため、研究者たちは「ExVideo」という手法を開発しました。ExVideoは既存の動画生成モデルを拡張し、より長い動画を生成できるようにする新しいアプローチです。
ExVideoの仕組みは、動画生成モデルの重要な部分である時間的モジュールを巧みに拡張することにあります。具体的には、3D畳み込み層、時間的注意機構、位置エンコーディングなどを改良し、モデルがより長い時間スケールで動画を理解し生成できるようにしています。
この手法の大きな特徴は、元のモデルの持つ汎用性を損なうことなく拡張できる点です。そのため、様々なスタイル(リアル、アニメ、ピクセルアートなど)や解像度(512×512、576×1024、1024×576、1024×1024など)の動画を生成することが可能です。
また、限られた計算リソースでも効率的に学習できるよう、パラメータの凍結や混合精度トレーニングなどの技術を活用しています。
研究チームは、この手法をオープンソースモデル「Stable Video Diffusion」に適用しました。その結果、元のモデルが生成できる最大25フレームから、128フレーム(5倍以上の長さ)の動画生成に成功しました。
さらに、ExVideoは既存のテキストから画像への生成モデルと組み合わせることができます。これにより、ユーザーが簡単なテキスト入力をするだけで、長時間の高品質な動画を生成できるシステムの構築が可能になります。


ExVideo: Extending Video Diffusion Models via Parameter-Efficient Post-Tuning
Zhongjie Duan, Wenmeng Zhou, Cen Chen, Yaliang Li, Weining Qian
Project | Paper | GitHub
言語より視覚に重きを置く、オープンなマルチモーダル大規模言語モデル「Cambrian-1」はGPT-4VやGemini Proと同等レベル
Cambrian-1は、画像と言語の両方を理解できる新しいAIモデルです。従来のAIが言語能力の向上に重点を置いていたのに対し、Cambrian-1は視覚的な理解能力の向上に焦点を当てています。
このモデルは8B、13B、34Bの3つのサイズで提供され、それぞれ約80億、130億、340億のパラメータを持っています。
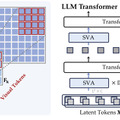
研究チームは20種類以上の画像認識モデルを比較検討し、「Spatial Vision Aggregator」(SVA)という新技術を開発しました。SVAにより、高解像度の画像情報を効率的に処理できるようになりました。
また、AIの視覚理解能力をより正確に測定するため、「CV-Bench」という新しい評価基準を作成しました。
Cambrian-1の学習には、インターネット上の多様な画像と文章データを使用し、バランスの取れたデータセットを作成しています。
結果として、Cambrian-1は多くの評価基準でオープンソースのモデルを上回り、GPT-4VやGemini Proなどの最新の商用AIモデルと同等以上の性能を示しています。特に視覚的な理解を必要とするタスクで優れた結果を出しています。

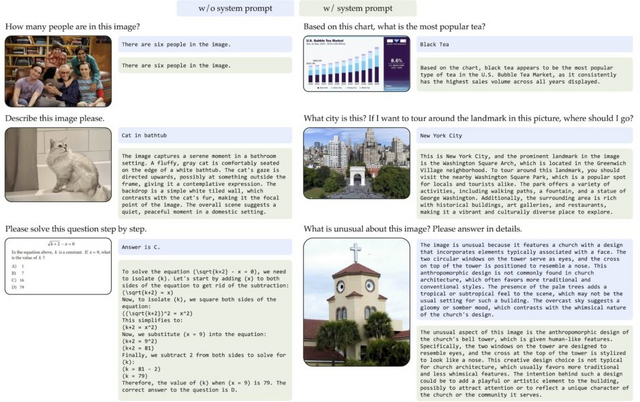
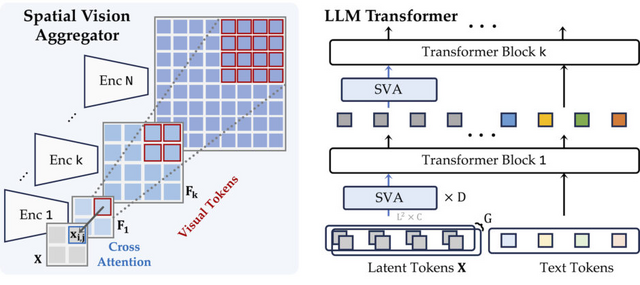

Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai Charitha Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, Austin Wang, Rob Fergus, Yann LeCun, Saining Xie
Project | Paper | GitHub
イベントカメラを使用するAIビデオ超解像技術「EvTexture」、特にテクスチャ領域で画質向上
スマートフォンやデジタルカメラで撮影した低画質の動画を、鮮明な高画質動画に変換する技術「ビデオ超解像」があります。しかし、これまでのビデオ超解像技術には課題がありました。特に、布地の織り目や木の葉のような細かい模様(テクスチャ)を持つ部分を鮮明に再現することが難しかったのです。
この問題に取り組むため、研究チームが新しい手法「EvTexture」を開発しました。EvTextureの特徴は、「イベントカメラ」と呼ばれる特殊なカメラを活用している点です。通常のカメラは一定間隔で画像全体を撮影しますが、イベントカメラは各画素の明るさの変化を瞬時に捉えることができます。高い時間分解能と広いダイナミックレンジを持つため、動きの速いシーンでも詳細な情報を捉えることができます。
EvTextureは、このイベントカメラのデータを利用して、テクスチャの豊かな部分を効果的に復元します。システムは深層学習技術を駆使しており、主に二つの部分から構成されています。一つは動きの情報を処理する部分、もう一つはテクスチャを強化する部分です。
研究チームがVid4、REDS4、Vimeo-90K-Tなどの標準的な評価用データセットを用いてEvTextureの性能を検証したところ、既存の最先端技術と比べて画質向上が確認されました。特に、テクスチャの多い映像では、最大4.67dBもの画質改善を達成しました。



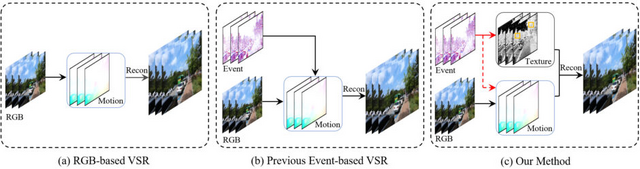
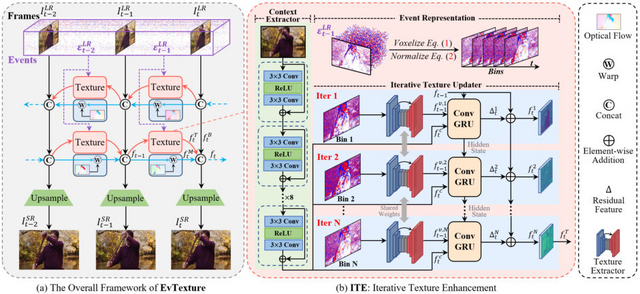
EvTexture: Event-driven Texture Enhancement for Video Super-Resolution
Dachun Kai, Jiayao Lu, Yueyi Zhang, Xiaoyan Sun
Project | Paper | GitHub
長い動画を理解できるオープンソースなAIモデル「LongVA」
画像や動画を理解する大規模なマルチモーダルモデルが注目を集めています。しかし、既存のモデルは長時間の動画を理解することが難しいという課題があります。
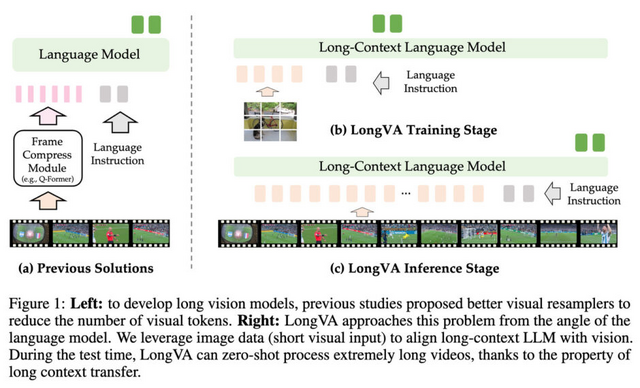
この問題に対して、研究者たちは新たなアプローチを提案しました。従来の方法では視覚トークンの数を減らすことに焦点を当てていましたが、今回の研究では言語モデル自体の長い情報の流れを理解し記憶する能力を拡張することで、動画理解の性能向上を図りました。
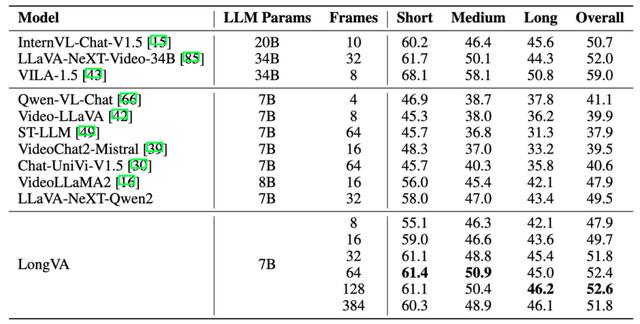
研究チームが開発したオープンソースなモデル「LongVA」(Long Video Assistant)は、言語モデルのコンテキスト長を22万4000トークンまで拡張し、2000フレーム以上、20万以上の視覚トークンを処理できるようになりました。LongVAは長時間の動画データで訓練することなく、短い画像データのみを使用して訓練されています。
また、研究チームは「V-NIAH」(Visual Needle-In-A-Haystack)という新しいベンチマークを開発しました。これは言語モデルの長い情報を理解する能力を測る「NIAH」を視覚領域に応用したもので、長時間動画理解能力を効果的に評価することができます。
V-NIAHで評価した結果、LongVAモデルは、2000フレームまでほぼ完璧な精度で情報を抽出し、3000フレームまで拡張しても高い精度を維持しました。これは、言語モデルの訓練時のコンテキスト長を超えて一般化できることを示しています。
またVideo-MMEベンチマークでは、LongVAは7Bパラメータ規模のモデルの中で最高性能を達成しました。入力フレーム数を8から128まで増やすと、性能が47.9%から52.6%まで向上しました。特に長い動画での性能向上が顕著でした。

Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, Ziwei Liu
Paper | GitHub
無音ビデオに音を挿入する音生成AI「FoleyCrafter」、動画内容に同期したそれっぽい音を生成
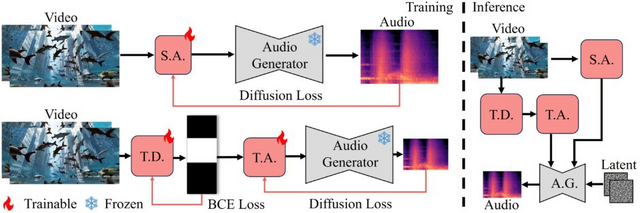
「FoleyCrafter」は、無音の動画に高品質で意味的に関連し、時間的に同期した音声を自動的に生成するフレームワークです。動画と同期した高品質の効果音を自動生成し、臨場感あふれるビデオを生成します。
この技術は、事前学習済みのテキストから音声への変換モデルを活用します。さらに、「意味的アダプター」と「時間的コントローラー」という2つの重要な要素を備えています。意味的アダプターは動画の内容に合わせて適切な音声を生成し、時間的コントローラーは音声と映像を正確に同期させます。
例えば、犬が吠える映像であれば、吠えた瞬間に鳴き声が挿入されたり、テニスをする映像であればラケットに当たる瞬間に当たった音が生成されます。
FoleyCrafterの特筆すべき点は、テキストプロンプトとの互換性です。ユーザーは文章で指示を与えることで、意図に沿った多様な音声生成が可能になります。例えば、海辺の風景に「カモメの鳴き声」というプロンプトを加えることで、その場面にふさわしい音声を生成できます。
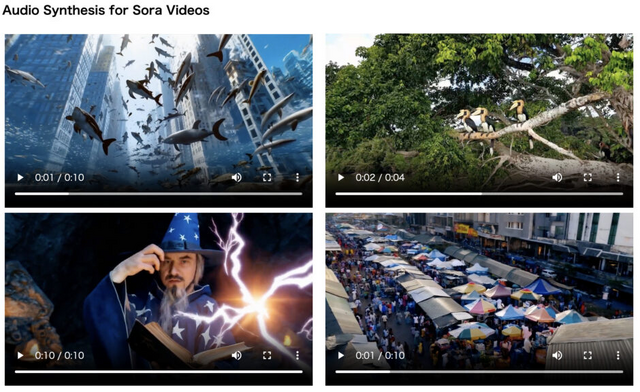

FoleyCrafter: Bring Silent Videos to Life with Lifelike and Synchronized Sounds
Yiming Zhang, Yicheng Gu, Yanhong Zeng, Zhening Xing, Yuancheng Wang, Zhizheng Wu, Kai Chen
Project | GitHub | Demo