




OpenAIのSoraを皮切りに、快手のKLINGやLuma AIのDream Machineなど高精度な動画生成AIが続々登場しています。そんな中、Runwayが「Gen-3 Alpha」を公開しました。このAIはプロンプトから5秒または10秒の動画を有料で生成し、その精度の高さが注目を集めています。さらに、音声やテキストに応じたリップシンク機能も搭載しています。

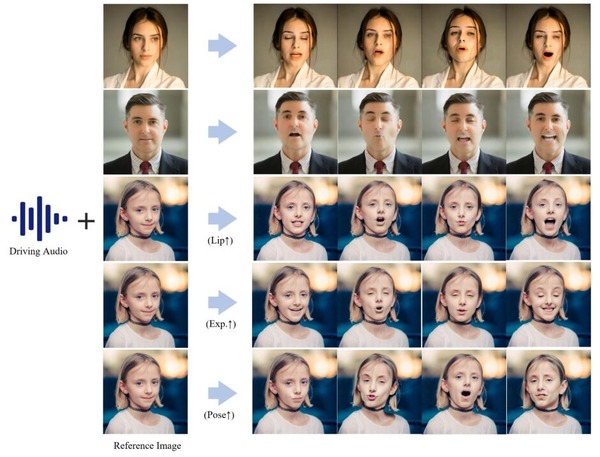
さて、この1週間の気になる生成AI技術をピックアップして解説する「生成AIウィークリー」(第54回)では、KLINGを開発した快手が、画像内のキャラクターの顔を自在に動かす技術「LivePortrait」を発表しました。従来の類似技術と異なり、顔の表情や頭部の動きの1フレームを12.8ミリ秒で生成できる高速さが特徴です。動きの精度も高く、調和のとれた合成映像を生成します。
生成AI論文ピックアップ
静止画内の顔の表情や頭部をリアルに動かすAI「LivePortrait」、1フレーム0.01秒で動作を生成
ショート動画共有アプリを開発する中国の快手(Kuaishou)は、静止画内のキャラクターの表情や頭部などを動作させるAIフレームワーク「LivePortrait」を発表しました。快手は、動画生成AI「KLING」の開発元としても知られています。
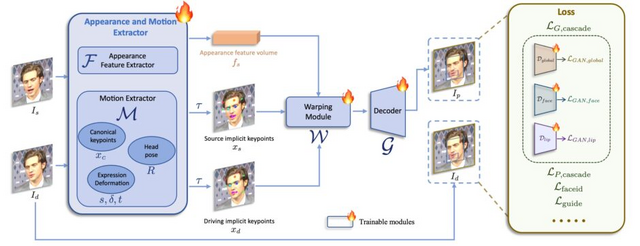
LivePortraitは、唇や眼球、眉毛などの細部の動きもリアルに制御できます。また処理も高速で、GPU(RTX 4090)を使用した場合、1フレームを12.8ミリ秒で生成できるという速度を誇ります。また、拡散モデルを用いた最新の手法と比較しても、同等以上の品質を達成しています。
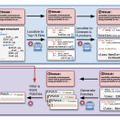
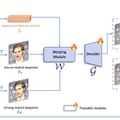
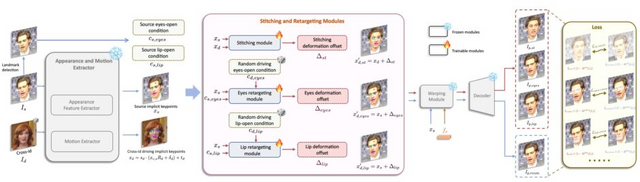
この技術の核となるのは「Implicit keypoints」と呼ばれる手法で、顔の特徴を効率的に表現します。まず、入力された静止画(ソース画像)から顔の特徴を抽出し、同時に動きを与える動画(ドライビング動画)から動きの情報を取り出します。次に、これらの情報を使ってImplicit keypointsを計算し、顔の特徴を動きに合わせて変形させます。最後に、変形した特徴から動画を生成します。
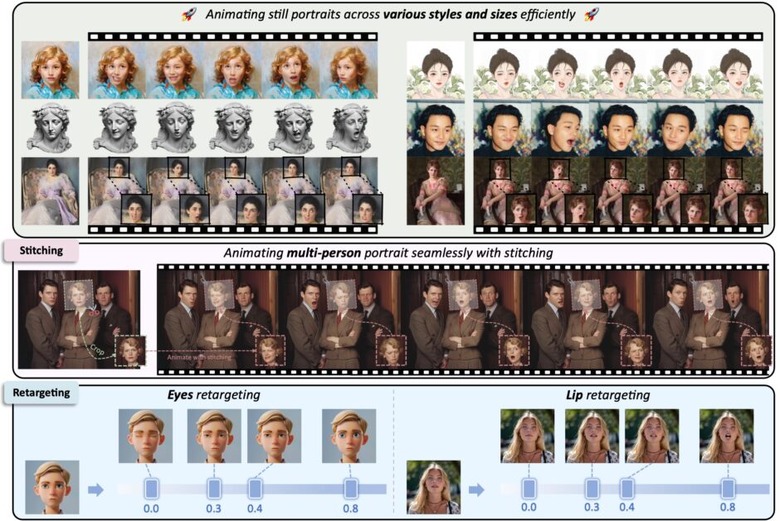
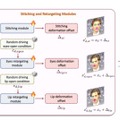
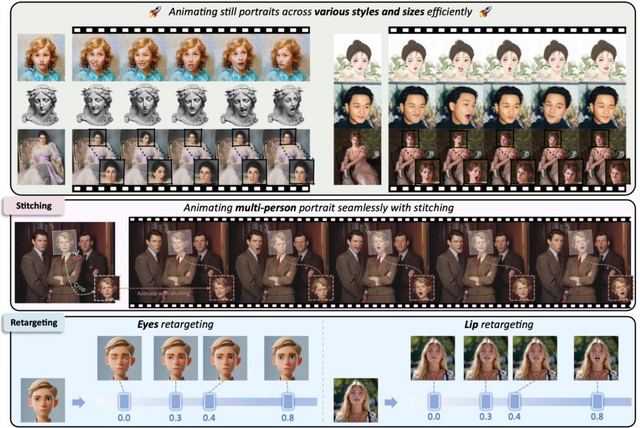
さらに、LivePortraitは細かな制御性も特徴としています。目や唇の動きを個別に制御する「リターゲティングモジュール」や、生成した顔を元の画像に自然に合成する「ステッチングモジュール」を開発し、より柔軟な表現を可能にしました。これにより、1枚の写真から自然な動きを持つ映像を生成したり、声や歌などの音声に合わせて口の動きを同期させたりすることもできます。
人間の肖像画だけでなく、動物の顔にも応用可能です。また、グループ写真内の複数の人物を同時にアニメーション化することもできます。さらに、KLINGで生成した動画内の動く人物の表情を制御することも可能です。


LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control
Jianzhu Guo, Dingyun Zhang, Xiaoqiang Liu, Zhizhou Zhong, Yuan Zhang, Pengfei Wan, Di Zhang
Project | Paper | GitHub
“10億の人格”を活用して大規模合成データを生成する手法をテンセントが開発
AI技術の進歩に伴い、大規模言語モデル(LLM)の訓練に用いる合成データ(モデルやアルゴリズムによって生成されたデータ)の重要性が高まっています。従来の合成データ作成手法には、既存データを基にする方法や重要概念のリストを使用する方法などがありましたが、拡張性や多様性に限界がありました。
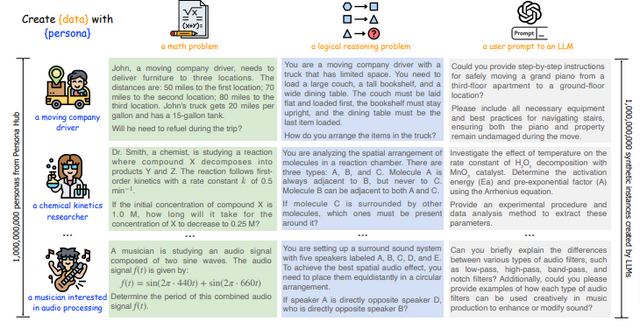
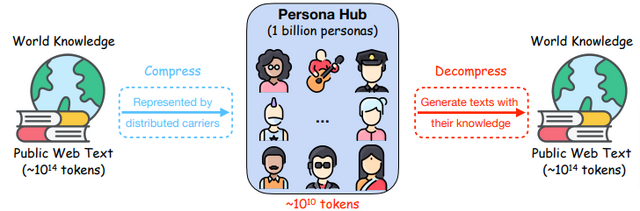
この研究では、膨大なウェブデータから自動構築された10億もの多様なペルソナ(世界の総人口の約13%に相当)を活用して、大規模かつ多様な合成データを生成することを可能にします。これにより、各ペルソナの固有の知識、経験、興味、性格、職業を反映したデータ生成を実現します。
この手法の中心となるのは「Persona Hub」と呼ばれるシステムです。これは、ウェブ上の膨大なデータから自動的に収集された10億の多様なペルソナのコレクションです。従来、データ作成は主に人間が担当する領域でしたが、このPersona Hubを活用することで、LLMが様々な視点から多様な合成データを生成できるようになります。
例えば、数学および論理的推論問題の生成では、複雑な問題を様々な難易度で作成することができます。また、ユーザーの指示(プロンプト)の生成では、多様なバックグラウンドを持つユーザーが求めそうな指示を予測して生成することができます。さらに、幅広い知識を含むテキストの生成、ゲームのNPC(ノンプレイヤーキャラクター)の設定、そしてLLMが利用可能なツール(関数)の開発にも成功しています。
特に注目すべき成果として、この手法を用いて7Bパラメータのモデルを微調整したところ、数学的推論能力を測るMATHベンチマークで64.9%という高い精度を達成しました。これはGPT-4 Turboに匹敵する性能です。
Scaling Synthetic Data Creation with 1,000,000,000 Personas
Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, Dong Yu
Paper | GitHub
ナレッジグラフを用いて回答精度を向上させる、マイクロソフト開発のLLM拡張技術「GraphRAG」がGitHubに登場
Microsoftが開発した「GraphRAG」は、データ情報の関連性をグラフ化することで大規模言語モデル(LLM)における回答精度を向上させる拡張技術です。GitHubにおいてリポジトリが公開されました。
従来の「RAG」(Retrieval-Augmented Generation)は、ユーザーの質問に関連する情報を外部から検索し、AIの回答生成に活用する手法です。これにより、専門的な質問や個別の質問に対する回答精度が向上します。
しかし、RAGは複数の情報源から関連性を見出して新しい結論を導き出すような場合に精度低下が起こります。また、大量のデータや長い文書の全体的な意味や要点を理解し、まとめる場合にも性能が低下します。
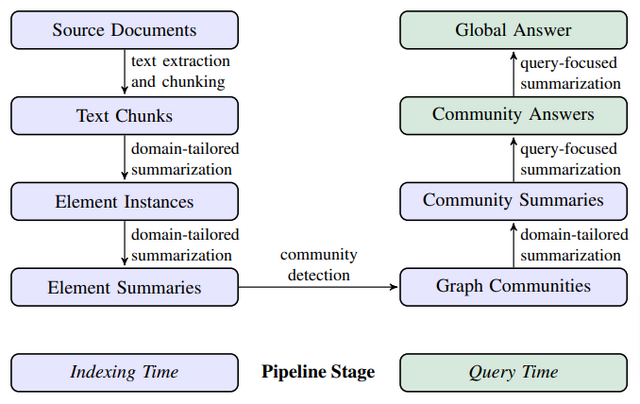
GraphRAGはこの課題を解決します。まずLLMがデータ全体を読み込み、そこに出てくる人物や場所、組織などの情報と、それらの関係性を見つけ出し、ナレッジグラフを作成します。次に、このナレッジグラフを使って、類似した情報をグループにまとめていきます。これにより、データの中にある重要な概念やテーマを事前に要約することができ、データ全体の理解が容易になります。
質問に答える際には、このナレッジグラフとグループ分けされた情報を活用することで、より適切で包括的な答えを提供できるようになります。この手法により、複数の情報源から関連性を見出して新しい洞察を生み出したり、大規模データ全体のテーマや傾向を把握したりすることが可能になります。
研究チームは、ニュース記事のベンチマークデータセットなどを使用して、データセット全体の理解を必要とするクエリを用いてGraphRAGを評価しました。その結果、GraphRAGが一貫してベースラインRAGを上回る性能を示しました。


From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Jonathan Larson
Project | Paper | GitHub | Blog
プロンプトの複雑さに応じ、強いLLMか弱いLLMかを自動選択するモデル「RouteLLM」
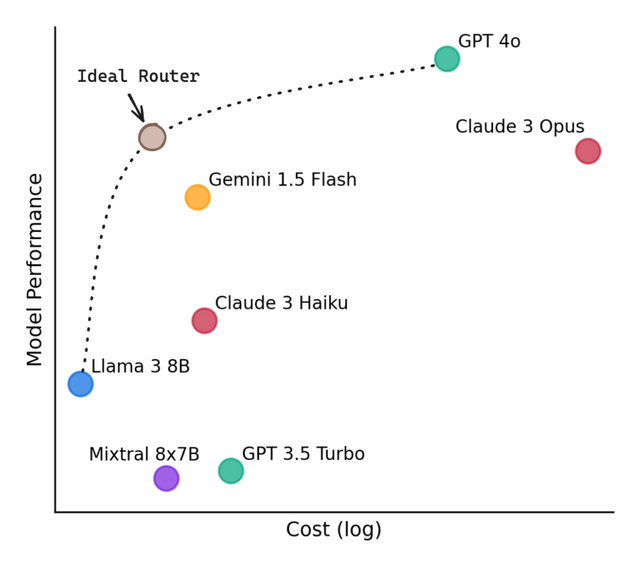
大規模言語モデル(LLM)のより高性能なモデルは優れた結果を出しますが、その分コストが高くなります。一方で、低コストのモデルは経済的ですが、複雑なタスクを処理する能力が限られています。
この課題に取り組むため、研究チームは「RouteLLM」という枠組みを開発しました。この枠組みの下で、研究チームは複数の効率的なルーターモデルを提案しています。これらのモデルは、ユーザーからのクエリを分析し、そのクエリの複雑さに応じて、強力だが高コストなモデル(例:GPT-4)と、比較的弱いが低コストなモデル(例:Mixtral-8x7B)の間で動的にルーティングを行います。
RouteLLMの核心は、人間の選好データを活用して訓練されたルーターモデルにあります。これらのルーターは、入力されたクエリの意図、複雑さ、領域を推測し、それに最も適したモデルを選択します。さらに、データ拡張技術を用いることで、ルーターの性能をさらに向上させています。
研究チームは、MT Bench、MMLU、GSM8Kなど、広く認知された複数のベンチマークを使用してRouteLLMの評価を行いました。その結果、RouteLLMは、応答の質をほとんど損なうことなく、特定のケースではコストを2倍以上削減できることが示されました。
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, Ion Stoica
Paper | GitHub | Hugging Face | Blog
ソフトウェア開発の問題を解決する、自律型AIを排除したアプローチ「Agentless」
大規模言語モデル(LLM)を活用したソフトウェア開発支援が急速に進展しています。特に注目を集めているのが、LLMを基盤とした自律型エージェントシステムです。これらのエージェントは、コード生成、プログラム修正、テスト生成など、さまざまなソフトウェア開発タスクを自動化することができます。
しかし、このようなエージェントベースのアプローチには課題も多く存在します。まず、ツールの使用と設計が複雑で、不適切な設計や使用がパフォーマンスの低下やコスト増加を招く可能性があります。次に、エージェントの意思決定プロセスの制御が難しく、最適でない探索や理解しづらい決定につながることがあります。最後に、エージェントには自己反省能力が限られており、不適切な情報を適切に処理できないため、誤った判断が後続の決定に悪影響を及ぼす可能性があります。
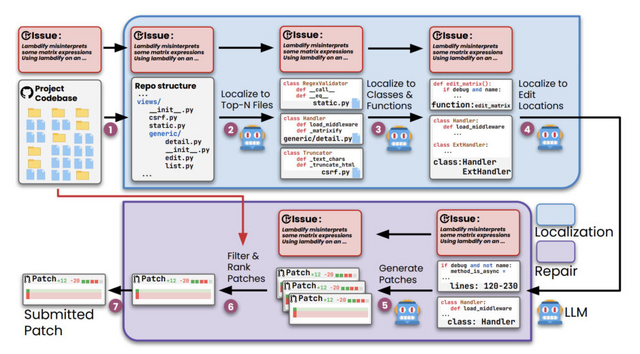
研究チームは、LLMを活用しつつ、複雑な自律型エージェントを使用せずに、ソフトウェアの問題箇所を特定し、段階的に修正を行う効率的なソフトウェア開発支援システム「Agentless」を開発しました。
このシステムは、まず問題箇所の特定において、リポジトリの構造を分析し、修正が必要なファイル、クラス、関数、そして具体的な編集位置を段階的に絞り込みます。次に、修正段階では、特定された編集位置に基づいて複数の修正パッチを生成し、それらをフィルタリングして最適なパッチを選択します。
このプロセス全体でAgentlessはLLMを活用していますが、従来の複雑なエージェントシステムとは異なり、LLMに自律的な意思決定や複雑なツール操作を任せることはありません。
研究チームは、実世界のソフトウェア開発問題を含むSWE-bench Liteベンチマークを用いてAgentlessを評価しました。その結果、Agentlessは300問中82問(27.33%)を解決し、既存のオープンソースの自律型エージェントベースアプローチを上回る性能を示しました。