AIによる音声合成は、Diff-SVC、RVC、Vocoflex、Seed-VCなどのボイチェン方面で追いかけてきましたが、最近では商用サービスがTTS(Text To Speech)によるボイスクローニングを充実させてきたことに注目しています。
その一方で、オープンソース、フリーソフト側でもずいぶん進化しているのを見落としていました。そこに気づくきっかけとなったのは、「AivisSpeech」というソフトの登場です。
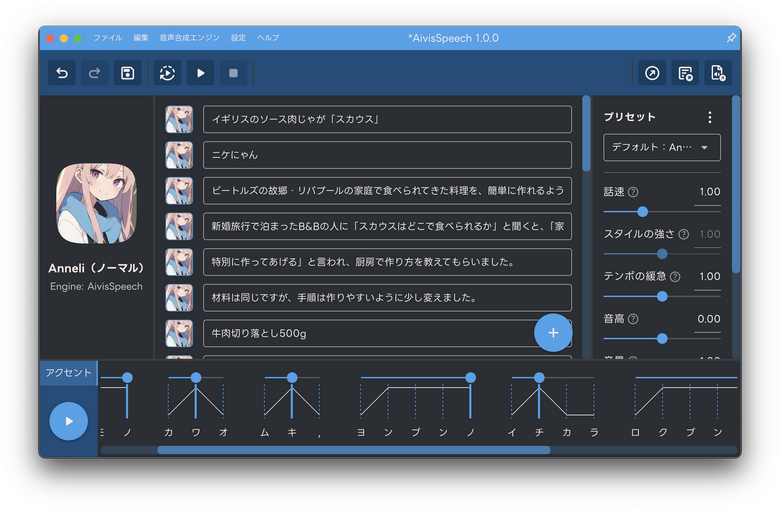
(▲AivisSpeech)
■AivisSpeechの登場
AivisSpeechとは、日本で開発されたAI音声合成ソフトで、いくつかのプリセットボイスが使える推論用アプリがMac、Windows向けに提供されており、すぐに試すことができます。
既存のアプリに似た使いやすいユーザーインタフェースで、感情表現やアクセントの修正などが直感的にできる他、音声をトレーニングしてその人の声にできる、ボイスクローニングも可能です。推論(読み上げ)だけならば、GPUなしのPCでも可能です。
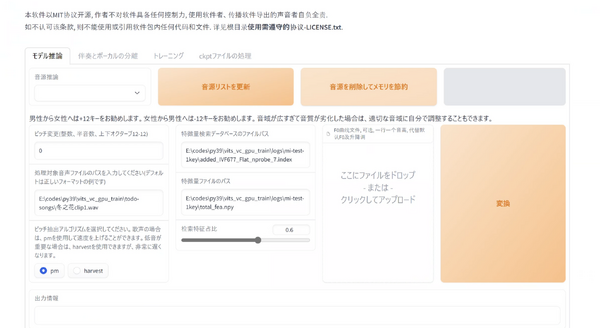
音声合成方式は独自のものですが、オープンソースのボイスクローニングTTSとして注目されている「Style-Bert-VITS2」で学習したモデルを変換して使うこともできます。
ボイスクローニングのための仕組みは現在開発中で、さらに、Style-Bert-VITS2からの変換スクリプトも一般ユーザーには非常に難しい形でしか提供されていませんが、とりあえずプリセット音声で試してみようと考えました。
■Style-Bert-VITS2で学習してみる
その前に、Style-Bert-VITS2で、妻のTTSを作ってみました。
きっかけは、AivisSpeechのボイスデータをユーザーが投稿するAivisHubに、一部ユーザーが故人の俳優のモデルを勝手に作成してアップロードしたことが問題になっていたことです。もちろんこれはやってはいけないことですが、それが問題になるくらいのクォリティだったということでもあります。
実用になる、妻(故人)のTTSを作るというのは以前からチャレンジしていたことでもあるので、これはやらなければと思いました。
限られた音声データでのTTSは、歌唱合成とはまた違った難しさがあります。
統計的手法の隠れマルコフモデルを使ったOpen JTalk、iPhoneのマイクから読み上げれば声のTTSが作れるコエステーションを、2016年と2018年に試しています。
・Open JTalkの音響モデルを作ってもらったので自分と会話ができちゃうのだ
そこから6年が経過し、生成AI技術が大きく進化した今、TTSもまた実用域に入っているようです。
ElevenLabsかOpenAIのTTS、ボイスクローン技術を使ったと思われるアバターサービスのHeyGenでは、数十秒の音声データがあれば、日本語を含むTTSが可能になりました。
しかし、日本語読み上げの精度がまだ低く、かなりの修正を入れなければなりません。
そこで、重要になるのは、日本語の文章を、最小限の修正できちんと読み上げてくれるTTSの存在です。日本語TTSとしては、古くはエーアイのAITalkエンジンを使ったVOICEROID(2008年)、OpenJ Talkの開発者らが作ったCeVIO(2013年)といった商用ソフトは当時から高品質で、現在も人気が高いですが、一方で、ユーザーが自由に自分の声をTTSにできるわけではありませんでした。
声を再現できるTTSは、声の特徴を抽出するために、必要な音素を集められるよう網羅した音素バランス文、例えば「あらゆる現実をすべて自分のほうへねじ曲げたのだ」などを大量に読み上げる必要がありました。
ところで、これが伊丹十三の文章であるということは今調べて初めて知りました。
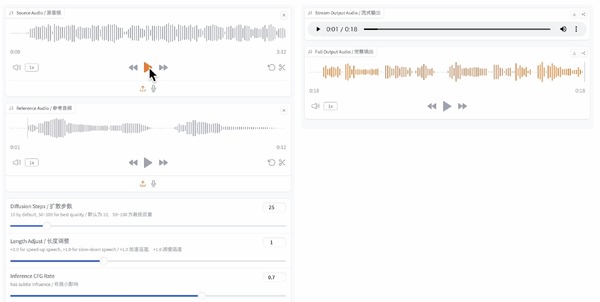
だいぶ脱線してしまいましたが、AivisSpeechを試す前に、Style-Bert-VITS2で学習を試してみます。「入力されたテキストの内容をもとに感情豊かな音声を生成するBert-VITS2のv2.1とJapanese-Extraを元に、感情や発話スタイルを強弱込みで自由に制御できるようにしたものです」と解説にあるように、人間らしい読み上げが可能なようです。
Windows用インストーラも用意されているので、手軽に導入できました。
妻が韓国のテレビに出演したときの音声が2分くらい取得できたので、それにノイキャンを施して学習させました。
学習用の音声データを分割したりそれを文章に書き起こしたりするのは本来であれば大変な作業ですが、今時はWhisperを使ってオートマチックにできちゃうんですね……。
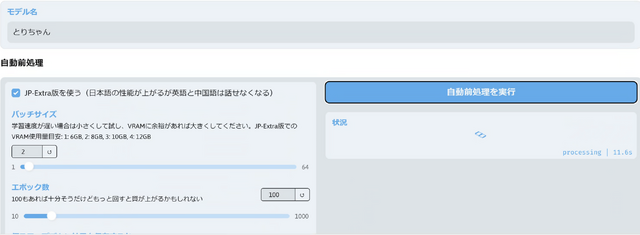
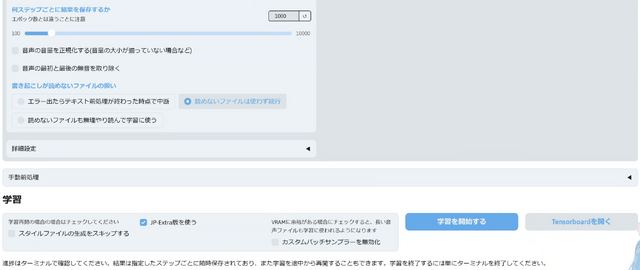
結果、ホワイトノイズはだいぶ乗ってしまいますが、本人らしさはかなり出ています。
TTSで文章を読み上げたときの自然さはこれまで試した中では最高部類で、いったんLogic Proに読み込んでFlex Pitchのピッチエディタで気になるアクセント(イントネーション)を調整したら、使えるレベルになりました。
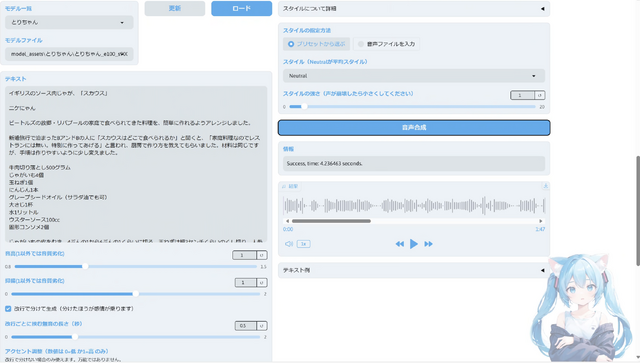
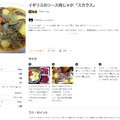
それで、作ってみたのがこちらの動画です。
妻が遺してくれたクックパッドのレシピを本人の声で読み上げてもらうというアイデアです。ビートルズの生まれ故郷であるリバプールの郷土料理「スカウス」を、新婚旅行の時にB&Bの女将さんから教わったレシピです。
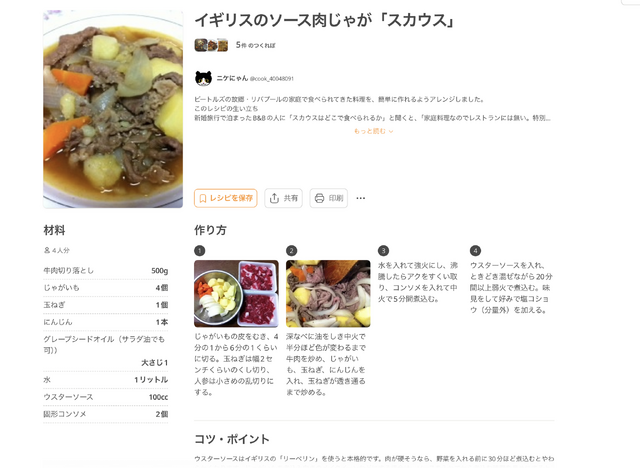
この料理は、いつもクックパッドを見ながら作っているのですが、これからはこのビデオを見ながら料理できます。
「もうこれでいいじゃないか」と思ったのですが、AivisSpeechを試して考えが変わりました。
日本語読み上げの精度がさらに上がっており、間違ったアクセントの修正が直感的に行えるようになっているのです。
デフォルト音声で同じ文章を読み上げたとき、漢字の読み間違いはほとんどありません(4分の1を「よんぷんのいち」というくらい)。
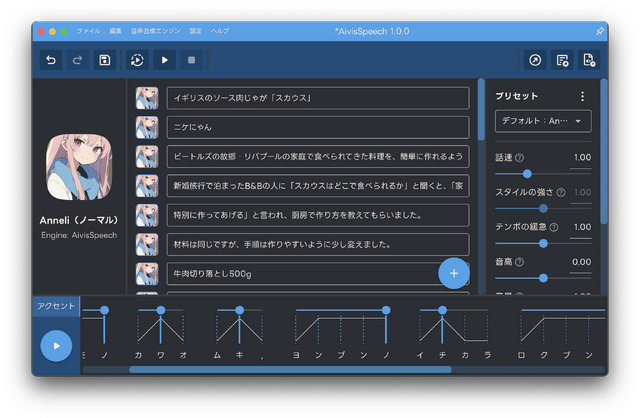
アクセントの修正も、左右にスライドさせるだけという直感的な操作で大抵の場合はうまくいきます。
同じ文章を、AivisSpeechに読み上げさせて、それを妻の声を学習したRVCでボイチェンしたものを、同じビデオのタイムラインに置いてみました。
アバターの年齢に合わせてピッチを半音上げていますが、これも自然な感じです。
AivisSpeechで学習したわけでも、Style-Bert-VITS2のモデルをONNX変換してAivisSpeechで使えるようにしたわけでもありませんが、近い将来はこんな感じで簡単に使えるだろうと期待が持てます。
開発者の方も、変換サーバ開発に尽力されているようなので、それまではRVCボイチェンでしのいでいこうと思います。
AivisBuilderを使ったAivisSpeechネイティブモデルの学習では、元音声のノイキャンや分離もやってくれるみたいなので、そちらにも期待です。
なお、BGMに使っている曲「Ballad for Scouse Mouse」は、リバプールの地元紙であるLiverpool Echoにかつて連載されていたマンガ「Scouse Mouse」をテーマに、Suno v4で作った歌です。