1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。
今回は、大規模言語モデル(LLM)の数十億のパラメータの中でたった1つのパラメータを削除するだけで、モデルのテキスト生成能力が完全に崩壊することを発見した論文「The Super Weight in Large Language Models」に注目します。
研究チームは、このパラメータを「スーパーウェイト」と名付けました。70億のパラメータを持つMetaのLlama-7Bモデルでは、このスーパーウェイトをゼロにするだけで、モデルのテキスト生成能力が完全に失われ、ゼロショットタスクの精度が大幅に低下しました。

▲左側では、スーパーウェイトを含む元のLlama-7Bが、妥当な文章を生成しています。右側では、スーパーウェイトを除去した後のLlama-7Bが、意味不明な文章を生成しています
パープレキシティ(文章の予測困難さを示す指標)が悪化し、入力プロンプトに対して意味不明の出力が示されました。興味深いことに、このスーパーウェイト以外の上位7000個の大きな値を持つパラメータを削除しても、モデルの性能はほとんど影響を受けませんでした。
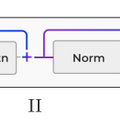
スーパーウェイトの特徴として、常に「mlp.down_proj」の重みの中に存在し(1個とは限らない)、必ず初期層に位置しています。
また、このスーパーウェイトは「スーパーアクティベーション」と呼ばれる特別に大きな活性化値を生み出します。このスーパーアクティベーションは、入力プロンプトに関係なく、常に同じ大きさと位置で発生し、モデル全体を通じて維持されます。
さらに、スーパーウェイトの役割について詳しく調べると、それは「the」や「.」「,」などの機能語の確率を抑制する効果があることが分かりました。スーパーウェイトを削除すると、これらの機能語の抑制効果がなくなり、出現確率が何倍に増加してしまいます。

▲スーパーウェイトの動作メカニズム
この発見は、モデルの圧縮や量子化にも重要な示唆を与えています。スーパーウェイトとスーパーアクティベーションを適切に処理することで、単純な量子化手法でも高い性能を維持できる可能性があります。
研究チームは、Llama、OLMo、Mistralなど、一般的に入手可能な様々なLLMモデルのスーパーウェイトの位置をインデックスとして公開しています。