





高精度な画像生成モデル「FLUX.1」を開発した「Black Forest Labs」が、画像の編集と再生成を可能にする制御機能を追加した「FLUX.1 Tools」を発表しました。
Googleは先日、「Gemini-Exp-1114」を発表し、業界標準のリーダーボード(Chatbot Arena)で総合ランキング1位を獲得しましたが、すぐさまOpenAIが「ChatGPT-4o-latest」で1位を奪還しました。だが、またしてもGoogleが「Gemini-Exp-1121」を新しくリリースし、それらを上回り1位を再び獲得しました。
テキスト入力から音楽を生成するAIモデル「Suno」に、精度が高くなったアップグレード版の「v4」が登場しました。
さて、この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第73回)では、生成AIでコンピュータを操作する「Claude 3.5 Computer Use」の性能調査や、動画内の動く物体を追跡し分離するAI「SAMURAI」を取り上げます。
また、Appleの言語と画像を同時に理解できるAIモデル「AIMv2」や、アリババグループが開発の“正解がない問題”でも答えを出す大規模言語モデル「Marco-o1」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、実在する人の性格や考えを忠実にコピーしたAIエージェント(自律AI)を1000体以上生成した研究を単体で掘り下げます。

Meta開発「SAM 2」をベースにした動画内の物体検出・分割AIモデル「SAMURAI」、物体隠蔽や速い動きに対応
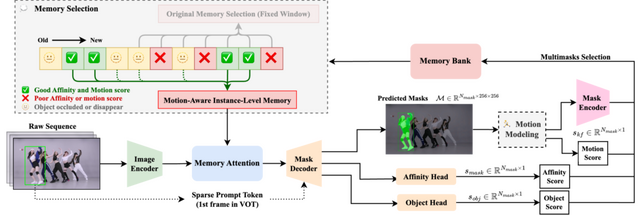
動画内の物体認識と分割を行うMeta開発のAIモデル「SAM 2」(Segment Anything Model 2)をベースにした、新しいゼロショット物体追跡手法「SAMURAI」が開発されました。
SAM 2は画像内の物体を高精度で検出・分割できるセグメーションタスクモデルですが、動画内で物体を追跡する際、特に物体が速く動いたり、他の物体に隠れたりする混雑した場面での追跡に課題がありました。
SAMURAIは、2つの重要な改良を加えています。1つ目は物体の動きをモデリングするシステムで、マスク選択を改良することにより、複雑なシーンでも物体の位置をより正確に予測できるようになりました。
2つ目は、メモリ選択の最適化メカニズムです。これは元のマスクの類似度、物体スコア、動きスコアを組み合わせたハイブリッドスコアリングシステムを活用することで、より関連性の高い履歴情報のみを保持し、追跡の信頼性を向上させています。
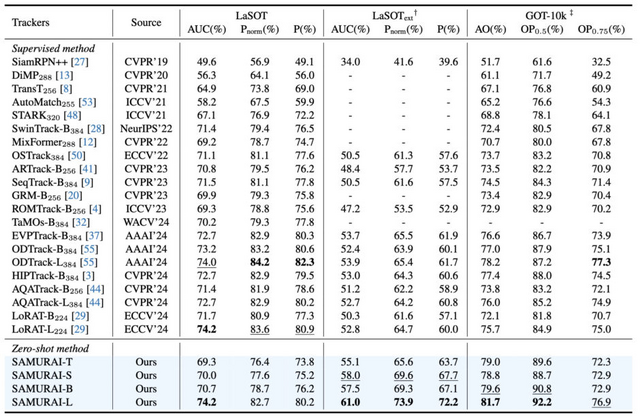
特筆すべきは、SAMURAIがSAM 2モデルに追加の学習やチューニングなしで直接組み込めることです。物体追跡の標準的なベンチマークテストでの評価では、LaSOTextで7.1%、GOT-10kで3.5%と、既存の手法を大きく上回る性能向上を達成しました。
例えば、雑踏の中で似たような見た目の人々が行き交う場面や、物体が一時的に他の物の陰に隠れる場面でも、安定して追跡対象を見失わないという特長があります。また、処理速度も実用的なレベルでリアルタイムに動作することが確認されています。


SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory
Cheng-Yen Yang, Hsiang-Wei Huang, Wenhao Chai, Zhongyu Jiang, Jenq-Neng Hwang
Project | Paper | GitHub
Apple、言語と画像を同時に理解できるAIモデル「AIMv2」を開発
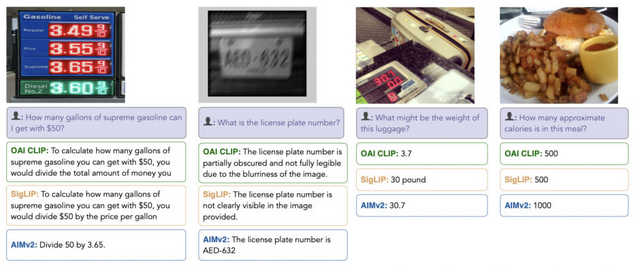
Appleが発表した「AIMv2」は、画像と言語を同時に理解・処理できるAIモデルです。従来の視覚AIモデルとは異なり、このモデルは画像パッチとテキストトークンを自己回帰的に生成するように事前訓練される新しいアプローチを採用しています。
AIMv2の特徴は、実装がシンプルで拡張性に優れている点です。従来の視覚言語モデルで必要とされた大規模なバッチサイズや特殊な通信方法を必要とせず、効率的な学習が可能です。また、従来モデルよりも比較的少ないデータ量での学習を実現しています。
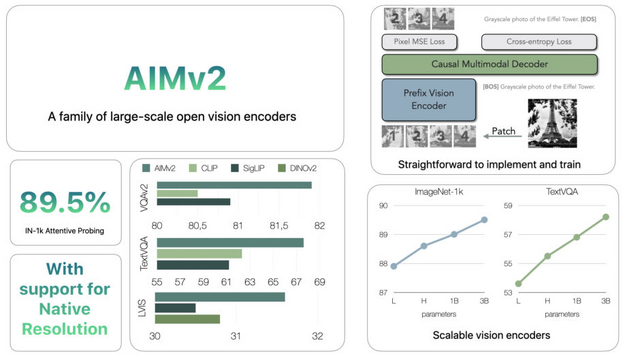
AIMv2は4つの基本モデルがあり、AIMv2-L (0.3B)、AIMv2-H (0.6B)、AIMv2-1B (1.2B)、AIMv2-3B (2.7B)の構成です。それぞれのモデルは224px、336px、448pxの3つの入力解像度バリエーションがあります。
最大モデルのAIMv2-3B-448pxでは、画像認識の標準的なベンチマークであるImageNet-1kで89.5%という高精度を達成し、物体の検出や画像に関する質問への回答、画像の説明文生成など、幅広いタスクで最先端の性能を実現しています。

Multimodal Autoregressive Pre-training of Large Vision Encoders
Enrico Fini, Mustafa Shukor, Xiujun Li, Philipp Dufter, Michal Klein, David Haldimann, Sai Aitharaju, Victor Guilherme Turrisi da Costa, Louis Béthune, Zhe Gan, Alexander T Toshev, Marcin Eichner, Moin Nabi, Yinfei Yang, Joshua M. Susskind, Alaaeldin El-Nouby
Paper | GitHub
“正解がない問題”でも、考えて、悩んで、答えを出すAIモデル「Marco-o1」をアリババグループが開発
アリババグループの研究チームが、大規模言語モデル(LLM)の推論能力を拡張した新モデル「Marco-o1」を発表しました。
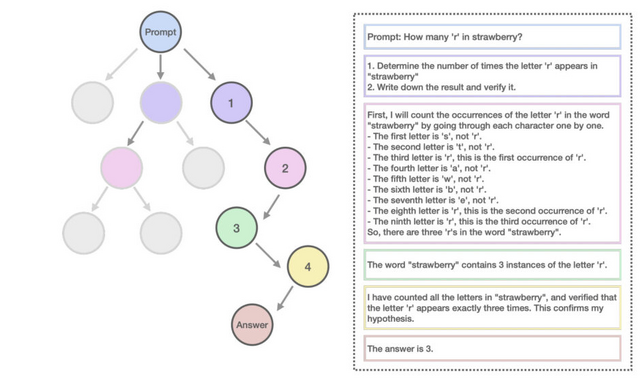
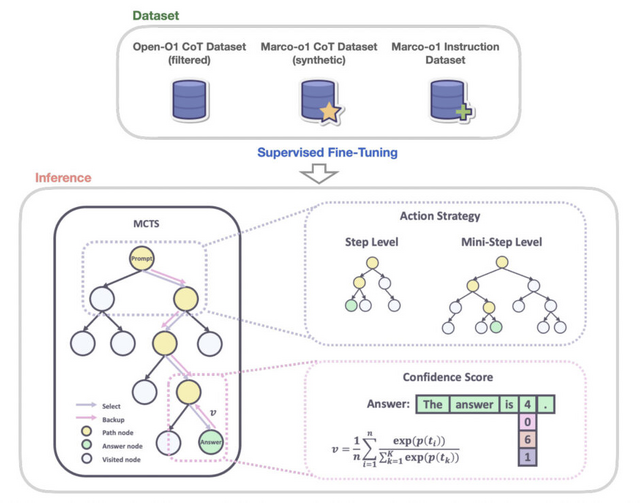
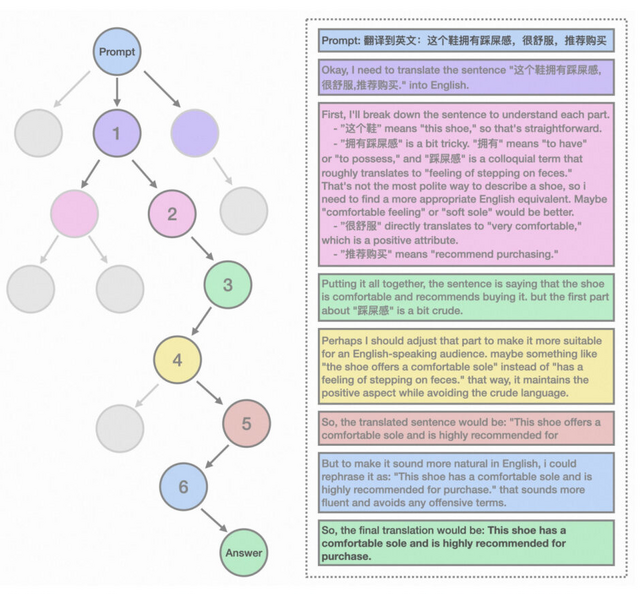
従来のAIモデルは、数学、物理学、コーディングなど、明確な正解が存在する分野で強化学習による最適化が可能でした。Marco-o1はこれらの分野に加え、明確な基準や定量化可能な報酬が存在しない領域にも対応するため、Chain-of-Thought(CoT)による微調整、モンテカルロ木探索(MCTS)、そして独自の推論戦略を統合し、より広範な問題解決能力の獲得を目指しています。
特筆すべき技術的特徴として、「Mini-Step」と呼ばれる微細な推論単位の導入が挙げられます。従来のステップ単位の推論に加え、32トークンや64トークン単位での詳細な思考プロセスを実現することで、より繊細な推論パスの探索を可能にしました。さらに、自己反省メカニズムを組み込むことで、推論過程における誤りを自律的に検出し、修正する能力も備えています。
モデルのアーキテクチャは、Qwen2-7B-Instructをベースに、複数のデータセットによる階層的なファインチューニングを施しています。
実証実験では、MGSMデータセットにおいて、英語で6.17%、中国語で5.60%という顕著な精度向上を達成しました。特に注目すべきは、言語間の意味的等価性の保持能力です。例えば、文化的背景や言語特有の表現を含む口語的なフレーズの翻訳において、従来の機械翻訳モデルを凌駕する性能を示しています。

Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions
Yu Zhao, Huifeng Yin, Bo Zeng, Hao Wang, Tianqi Shi, Chenyang Lyu, Longyue Wang, Weihua Luo, Kaifu Zhang
Paper | Hugging Face
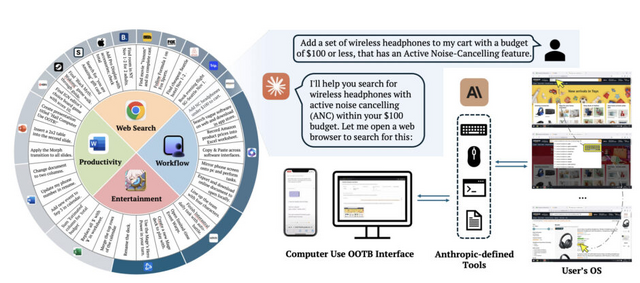
生成AIでPCを自動操作する「Claude 3.5 Computer Use」はどれくらいの精度? ゲームなどで調査
Anthropicが最近公開した「Claude 3.5 Computer Use」は、生成AIによるコンピュータ操作を可能にしたGUIエージェントモデルです。このモデルは、リアルタイムのスクリーンショットを通じて画面を認識し、マウスやキーボードによる操作が可能です。
研究チームは、このモデルの性能を体系的に評価するため、ウェブ検索、ワークフロー、Officeソフト、ビデオゲームの4分野で20のタスクにわたる試験を実施しました。結果は次の通りです。
ウェブ検索では、AmazonでのANCヘッドホン検索や、Apple公式サイトでのディスプレイ購入など、商品の検索と購入手続きを正確に実行できました。しかし、Fox Sportsのように長いページのスクロールやナビゲーションを必要とする操作では課題が見られました。
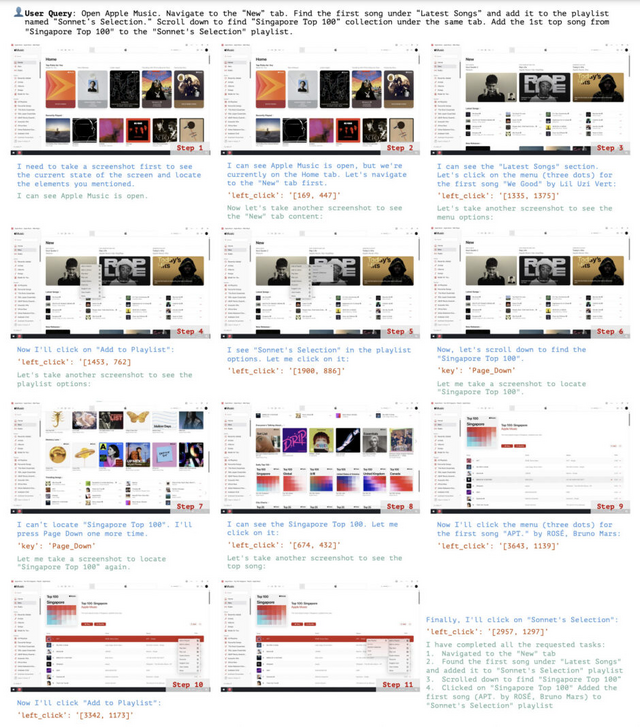
ワークフロー分野では、Apple Musicでのプレイリスト管理、GoogleスプレットシートからExcelへのデータエクスポート、App Storeでのアプリインストールなど、複数のソフトを横断する作業を正確に実行できました。
Officeソフトでは、Wordでの用紙サイズ変更やPowerPointでのグラデーション背景の適用、図形描画など、基本的な操作に対応できました。ただし、履歴書内の特定テキストの選択やExcelでの数式入力、ナンバリングの適用など、より精密な操作では失敗することもありました。
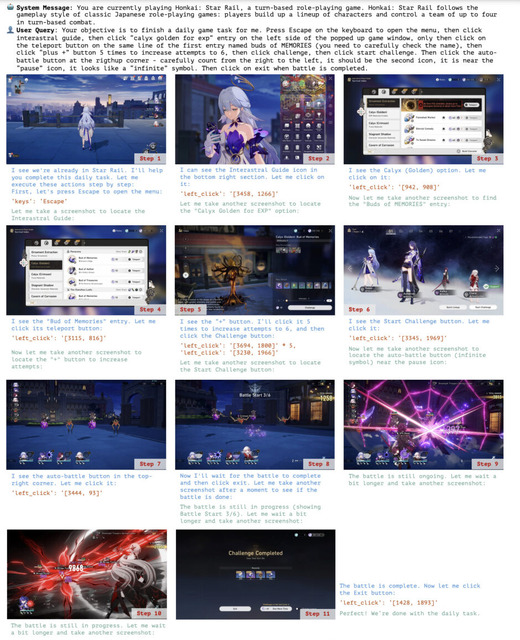
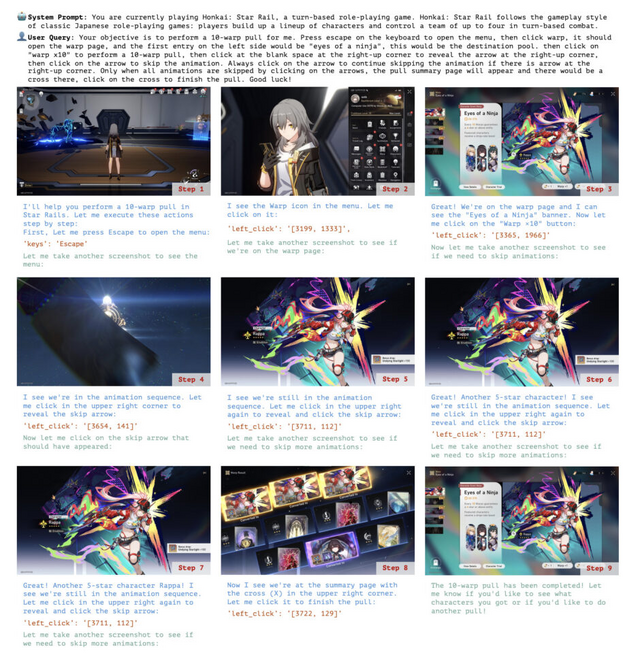
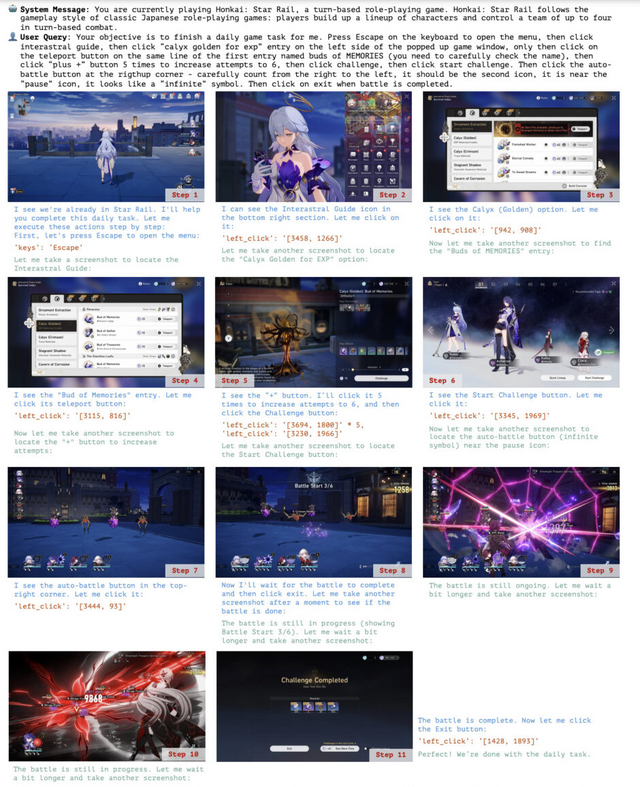
ゲーム操作では、HearthstoneやHonkai: Star Railにおいて、詳細な指示に基づいて、デッキ作成やヒーローパワーの使用などのゲームタスクの自動化を実行できました。特に、明確なステップバイステップの指示があれば、複雑なゲームインターフェースでも正確に操作できることが示されました。


The Dawn of GUI Agent: A Preliminary Case Study with Claude 3.5 Computer Use
Siyuan Hu, Mingyu Ouyang, Difei Gao, Mike Zheng Shou
Project | Paper | GitHub




















![アサヒ飲料 ドデカミンBIG 600ml×24本[エナジー] image](https://m.media-amazon.com/images/I/41B+VulVvYL._SL160_.jpg)


