






Anthropicは、AIシステムを色々なデータやツール、アプリと安全に繋ぐことができる「Model Context Protocol」(MCP)を発表しました。社内データベースやGoogle Driveのファイル、GitHubのコードやSlackの会話内容などにチャットAIがアクセスできてやり取りできるようになります。
動画生成AIを提供する「Runway」は、画像生成モデル「Frames」を発表しました。このモデルでは、独特なスタイル出力を特徴としており、1980年代映画の特殊メイク効果、1970年代のレコードジャケット、日本のZINE風など、様々なスタイルの世界観を作り出すことができます。
Luma AIが、動画生成AI「Dream Machine」の大型アップデートをしました。新しく発表した画像生成AI「Luma Photon」が組み込まれています。

さて、この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第73回)では、NVIDIAが主導して開発した、高解像度の画像を高速に生成するモデル「Sana」と、テキストから3Dアセットを生成するAI「Edify 3D」をご紹介します。
また、FLUX.1などの画像生成AIに制御機能を追加する「OminiControl」や、スクリーンショット画像だけを見て、人間のようにパソコンやスマートフォンの画面を理解・操作できるAIシステム「ShowUI」を取り上げます。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、大規模言語モデル(LLM)の数十億のパラメータの中でたった1つのパラメータを削除するだけで、モデルのテキスト生成能力が完全に崩壊することを発見したApple主導の研究を単体で掘り下げています。

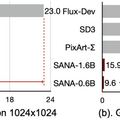
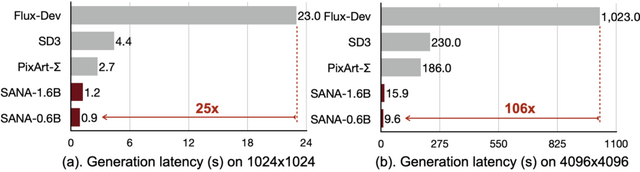
高解像度画像を100倍以上高速に作り出すNVIDIA開発の画像生成AI「Sana」
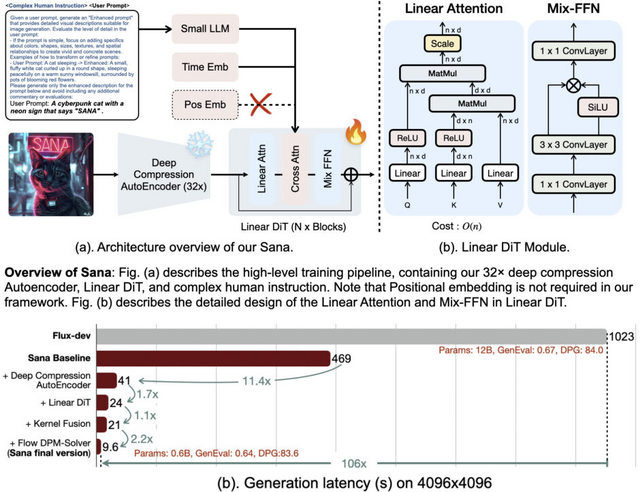
NVIDIAなどの研究チームは、効率的な高解像度画像生成が可能な新しいテキスト画像生成フレームワーク「Sana」を発表しました。このモデルは、4096×4096ピクセルという高解像度の画像を生成することができ、ノートPCのGPUでも動作する点が特徴です。
Sanaの中核となる技術として、従来の8倍圧縮と比べて32倍の圧縮が可能な深層圧縮オートエンコーダーを採用しています。また、高解像度での処理を効率化するため、従来の注意機構を線形注意機構に置き換えることで、画質を損なうことなく処理速度を向上させています。
さらに、テキストエンコーダーとして最新の小規模言語モデル(Gemma)を採用し、複雑な人間の指示に対する理解力を向上させています。
特筆すべき点として、Sana-0.6Bはパラメータ数が現在の最先端モデル(Flux-12Bなど)と比較しても競争力のある性能を示しており、モデルサイズは20分の1でありながら、処理速度は100倍以上高速です。16GBのノートPCのGPUでも動作可能で、1024×1024ピクセルの画像生成に1秒未満しかかかりません。

SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, Song Han
Project | Paper | GitHub
テキストから高品質な3Dアセット生成するAIモデル「Edify 3D」をNVIDIAが開発
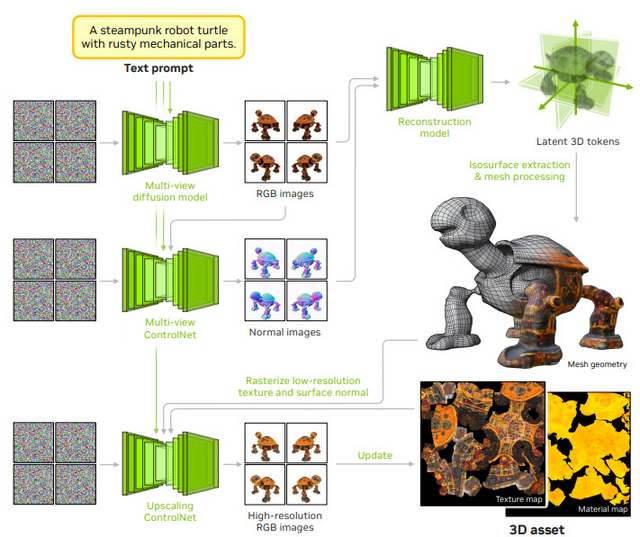
「Edify 3D」は、テキストから高品質な3Dアセット生成のためのAIモデルです。
このモデルは、まず拡散モデルを使用して、指定されたオブジェクトのRGB画像と表面法線画像を複数の視点から合成します。その後、これらの多視点画像を用いて、オブジェクトの形状、テクスチャ、物理ベースレンダリング用のマテリアルを再構築します。
特徴的な点は、2分以内という短時間で高品質な3Dアセットを生成できることです。生成されるアセットには、詳細な形状、整理された形状トポロジー、4K解像度までのテクスチャ、そしてPBRマテリアルが含まれます。
技術的には、拡散モデルとトランスフォーマーという2種類のニューラルネットワークを基盤としており、マルチビュー拡散モデルと再構築モデルを組み合わせて使用しています。
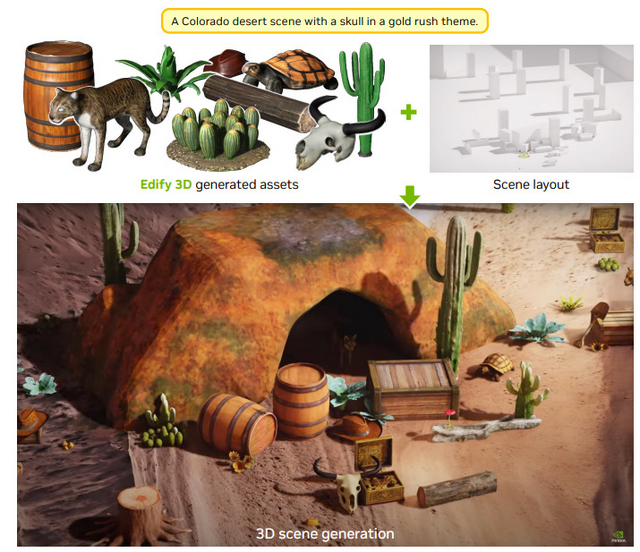
応用例として、Edify 3Dは3Dシーン生成にも活用できます。テキストプロンプトから3Dシーンのレイアウトを生成し、それに基づいて複数の3Dアセットを配置することで、一貫性のある3Dシーンを作り出すことができます。



Edify 3D: Scalable High-Quality 3D Asset Generation
NVIDIA: Maciej Bala, Yin Cui, Yifan Ding, Yunhao Ge, Zekun Hao, Jon Hasselgren, Jacob Huffman, Jingyi Jin, J.P. Lewis, Zhaoshuo Li, Chen-Hsuan Lin, Yen-Chen Lin, Tsung-Yi Lin, Ming-Yu Liu, Alice Luo, Qianli Ma, Jacob Munkberg, Stella Shi, Fangyin Wei, Donglai Xiang, Jiashu Xu, Xiaohui Zeng, Qinsheng Zhang
Project | Paper
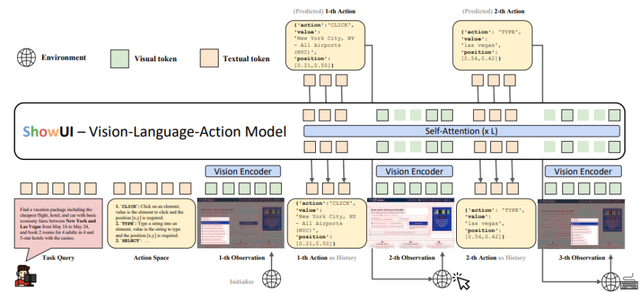
AIが人間のように画面を見て理解・操作する技術「ShowUI」
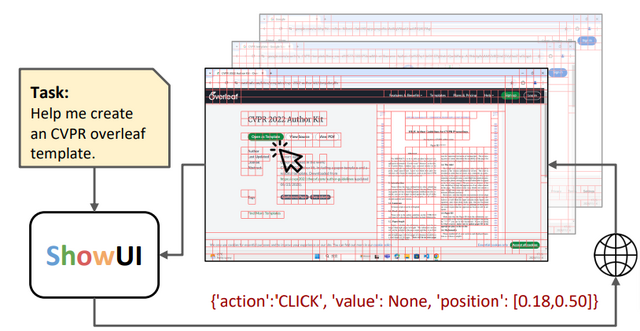
GUIとはパソコンやスマートフォンの画面上で見るボタンやメニューなどの操作部分のことですが、研究チームはこのGUIを人工知能が人間のように理解し操作できる新しいシステム「ShowUI」を開発しました。
これまでのAIシステムは、画面の裏側にある技術的な情報(HTMLやアクセシビリティツリーなど)に頼って操作を行っていましたが、人間のように画面を見て理解することは難しい課題でした。ShowUIは画像認識と言語理解、そして実際の操作を組み合わせることで、より人間に近い方法でGUIを扱えるようになっています。
ShowUIは視覚言語モデル「Qwen2-VL-2B」をベースに構築されており、画面上の要素を効率的に処理する仕組みがあります。画面のスクリーンショットを分析する際、似たような部分をグループ化して処理することで、計算量を33%削減し、処理速度を1.4倍に向上させることに成功しました。また、操作の履歴を記憶し、次の行動に活かす機能も備えています。
学習データについても工夫がなされており、ウェブサイト、スマートフォン、デスクトップアプリケーションなど、様々な種類のGUIデータを適切にバランスを取って使用しています。その結果、比較的少ない256,000件のデータで学習したにもかかわらず、画面上の特定の要素を75.1%という高い精度で認識できるようになりました。

ShowUI: One Vision-Language-Action Model for GUI Visual Agent
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Weixian Lei, Lijuan Wang, Mike Zheng Shou
Paper | GitHub
FLUX.1などのDiTベースの画像生成AIに制御機能を追加する「OminiControl」
「OminiControl」は、Black Forest Labsが開発した画像生成AI「FLUX.1」のようなDiffusion Transformers (DiT)モデル用に制御機能を追加するフレームワークです。
このフレームワークは、画像の輪郭(エッジ)や深度情報、カラー化、インペインティング/アウトペインティングによる制御から、特定の被写体の特徴を保持した画像生成まで、幅広いタスクを単一のフレームワークで処理することができます。
最大の特徴は、既存のモデル構造を最大限に活用しながら、わずか0.1%という極めて少ない追加パラメータで画像による制御機能を実現している点です。従来の手法ではControlNetで27.5%、IP-Adapterで7.6%もの追加パラメータが必要でしたが、OminiControlはモデル自身の能力を巧みに再利用することでこの課題を解決しています。
研究チームは、「Subjects200K」という新しいデータセットも公開しています。これは20万枚以上の画像ペアで構成され、各ペアは同一の被写体を異なる状況で撮影したような一貫性のある画像となっています。
実験結果では、従来のUNetベースの手法やDiTを改良した他の手法と比較して、より高品質な画像生成が可能であることが示されました。特に、被写体の特徴を保持しながら新しい画像を生成するタスクでは、顕著な性能向上が確認されています。




OminiControl: Minimal and Universal Control for Diffusion Transformer
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, Xinchao Wang
Paper | GitHub












![【DL版】【初期費用3,300円が無料 ※1契約者1回線/年に限り】IIJmioえらべるSIMカード エントリーパッケージ 月額利用(音声SIM/SMS)[ドコモ・au回線]・(データ/eSIM/プリペイド)[ドコモ回線]IM-B327 image](https://m.media-amazon.com/images/I/51sZVFzAH1L._SL160_.jpg)








