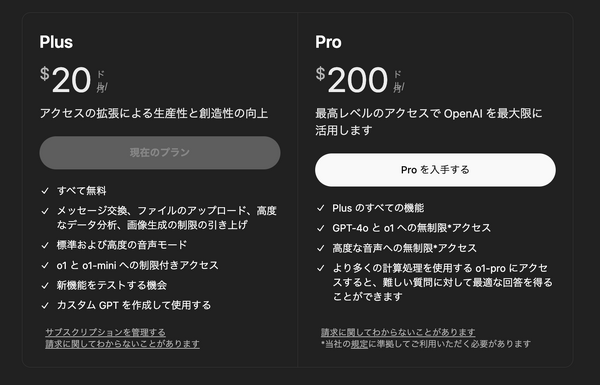



OpenAIは、ChatGPTの新しい有料プラン「ChatGPT Pro」を発表しました。価格は月額200ドルで、最高レベルの「OpenAI o1」を含むすべてのモデルを無制限で使用することができます。
Google DeepMindは、言語モデル「Gemini-Exp-1206」を発表しました。業界標準のリーダーボード(Chatbot Arena)で総合ランキング1位を獲得しています。またGoogleは、高品質な動画を生成できる新しいAIモデル「Veo」と画像生成モデル「Imagen 3」をVertex AI上で提供開始することを発表しました。
ローカルLLMでは、Metaが「Llama 3.3 70B」をリリースし、アリババグループがQwen-VLモデルの最新版「Qwen2-VL-72B」を発表しました。
また動画生成AI「Hailuo」が、2Dアニメイラスト特化型モデル「Hailuo I2V-01-Live」を発表しました。
さて、この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第74回)では、Googleによる高性能な天気予報AI「GenCast」、Googleの新しい視覚言語AIモデル「PaliGemma 2」を取り上げます。
また、Googleによる画像1枚からプレイ可能な3D環境ゲームを生成するAIモデル「Genie 2」、OpenAIのSoraに影響を受けたオープンソースの動画生成AI「Open-Sora」の技術論文をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、AIシステムが“量子もつれ”の新しい生成方法を発見した研究を単体で掘り下げます。
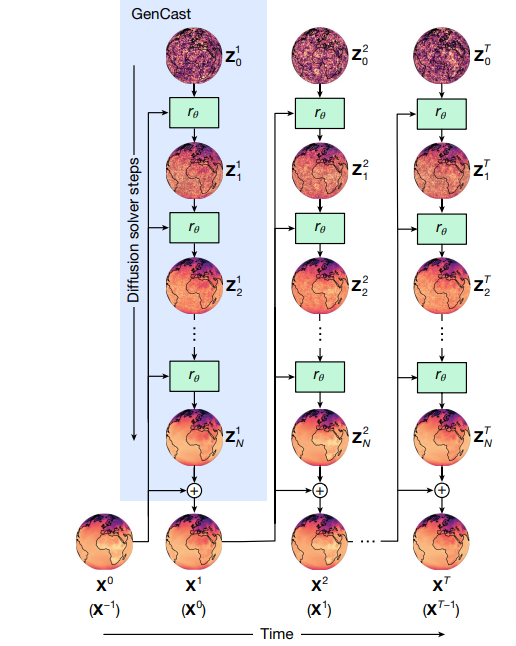
Google DeepMind、世界最高の気象予報システムを上回る性能のAIモデル「GenCast」開発
Google DeepMindの研究チームが開発した「GenCast」は、気象予報の不確実性を考慮し、複数の可能性のある気象シナリオを予測できる確率的天気予報モデルです。従来の数値予報モデルに比べて、予報の精度が高く、計算速度も大幅に向上しています。
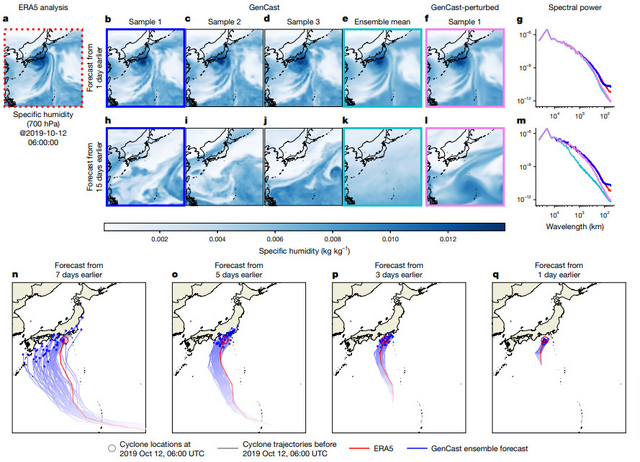
研究チームが実施した評価では、GenCastは欧州中期予報センター(ECMWF)の最先端アンサンブル予報システム「ENS」と比較して、評価した1,320項目の97.2%で優れた予測精度を示しました。特に短期予報(3-5日)、表面変数、および高気圧レベルでの気温と比湿の予測において10-30%の精度向上が確認されました。
GenCastの特徴的な点は、15日先までの全球予報を0.25度の解像度で生成でき、その計算に要する時間がわずか8分程度という高速性です。
さらに、GenCastは極端な気象現象の予測においても優れた性能を発揮します。2メートル気温や10メートル風速などの極値予測、熱帯低気圧の進路予測、風力発電量の予測などで、ENSを上回る精度を達成しました。
研究チームによれば、このAIモデルは再解析データを用いて40年分のデータで訓練されています。生成AIの一種である拡散モデルを採用することで、複数の現実的な気象シナリオを生成できる点が特徴です。
Probabilistic weather forecasting with machine learning
Ilan Price, Alvaro Sanchez-Gonzalez, Ferran Alet, Tom R. Andersson, Andrew El-Kadi, Dominic Masters, Timo Ewalds, Jacklynn Stott, Shakir Mohamed, Peter Battaglia, Remi Lam & Matthew Willson
Project | Paper | GitHub
OpenAIのSoraに影響を受けた、オープンソースの動画生成AI「Open-Sora」の技術論文が公開
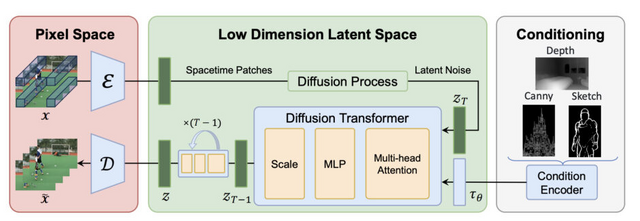
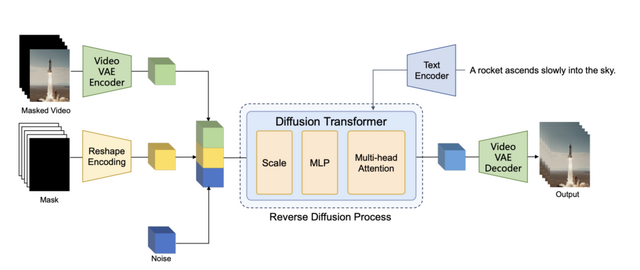
OpenAIのSoraに影響を受けた、オープンソースの動画生成AI「Open-Sora Plan」の開発について、研究チームが技術報告書を公開しました。このプロジェクトは、テキストプロンプト、複数の画像、その他(輪郭線、深度マップ、スケッチなど)を入力として、高品質で長時間の動画を生成することを目指しています。
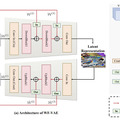
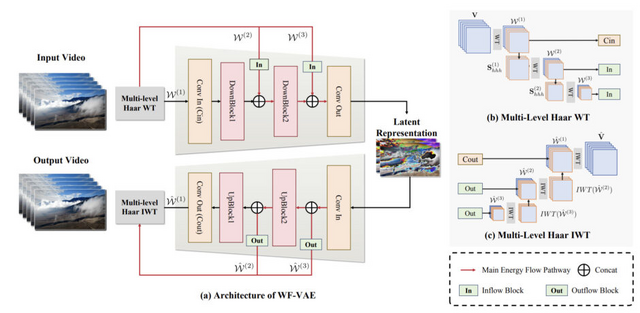
このシステムは、主に3つの重要な部分から構成されています。1つ目は、動画データを効率的に圧縮・展開する「Wavelet-Flow Variational Autoencoder」(WF-VAE)です。これにより、少ないメモリで高速に処理を行うことができます。
2つ目は、動画の特徴を深く理解する「Joint Image-Video Skiparse Denoiser」です。このコンポーネントは、物体の動き方、カメラの動き、物理的な法則、人の自然な動作など、動画に含まれる様々な要素を総合的に理解し、それを基に新しい動画を生成します。
3つ目は、ユーザーの意図を反映するための条件制御システム「Condition Controllers」です。例えば、1枚の写真から動画を作ったり、2つの動画をなめらかにつなげたり、既存の動画の続きを生成したりすることができます。また、線画や深度マップなどを使って、生成される動画の細かい部分まで制御することも可能です。
Open-Sora Planは現在も活発に開発が進められているオープンソースプロジェクトです。より高品質な動画生成を実現するため、継続的な改良が行われており、最新のプログラムコードやモデルデータは、GitHubを通じて一般に公開されています。

Open-Sora Plan: Open-Source Large Video Generation Model
Bin Lin, Yunyang Ge, Xinhua Cheng, Zongjian Li, Bin Zhu, Shaodong Wang, Xianyi He, Yang Ye, Shenghai Yuan, Liuhan Chen, Tanghui Jia, Junwu Zhang, Zhenyu Tang, Yatian Pang, Bin She, Cen Yan, Zhiheng Hu, Xiaoyi Dong, Lin Chen, Zhang Pan, Xing Zhou, Shaoling Dong, Yonghong Tian, Li Yuan
Paper | GitHub
画像1枚からプレイできる3D環境ゲームを生成するAIモデル「Genie 2」をGoogle DeepMindが開発
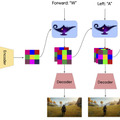
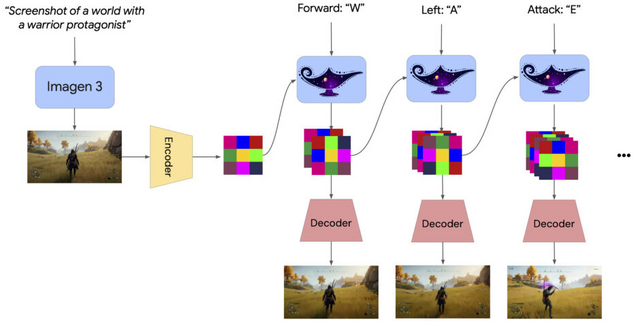
Google DeepMindは、1枚のプロンプト画像から3D環境ゲームを生成し、人間やAIエージェントがキーボードとマウスで操作できる基盤的世界モデル「Genie 2」を発表しました。
プロンプト画像は、同社の画像生成AI「Imagen 3」によって生成されます。ユーザーは文章で望む世界を説明し、その案をもとに生成された画像の中からお気に入りを選んで、その新しく作られた世界に入り込んで操作することができます。
Genie 2は、ビデオデータセットを学習したワールドモデルで、最大1分間の一貫性のある世界生成が可能です。
物理演算、キャラクターアニメーション、オブジェクトとの相互作用、照明効果など、ゲームエンジンのような多彩な機能を備えています。同じ開始地点から異なる展開を生成できる「カウンターファクチュアル生成」や、視界外の世界の記憶と正確な再現といった高度な能力も持ち合わせています。
さらに、このモデルはAIエージェントの訓練環境としても機能します。例えば、同社のAIエージェント「SIMA」をGenie 2の生成した環境で動作させ、様々なタスクを実行させることができます。これにより、トレーニング時に経験していない新しい環境でのAIの性能評価が可能になります。
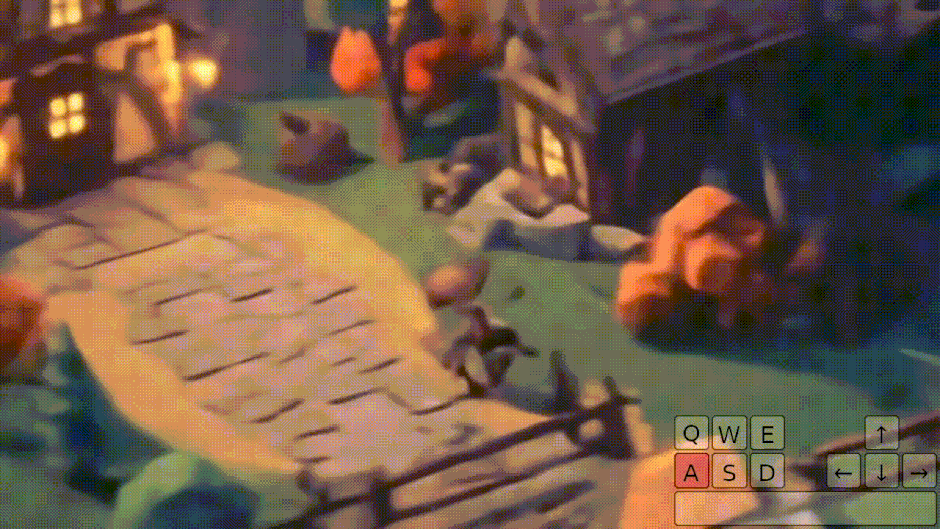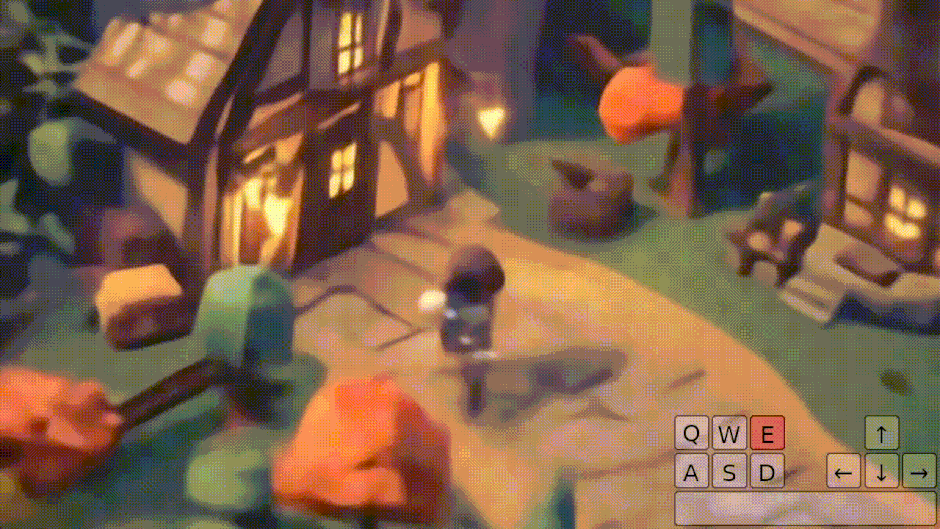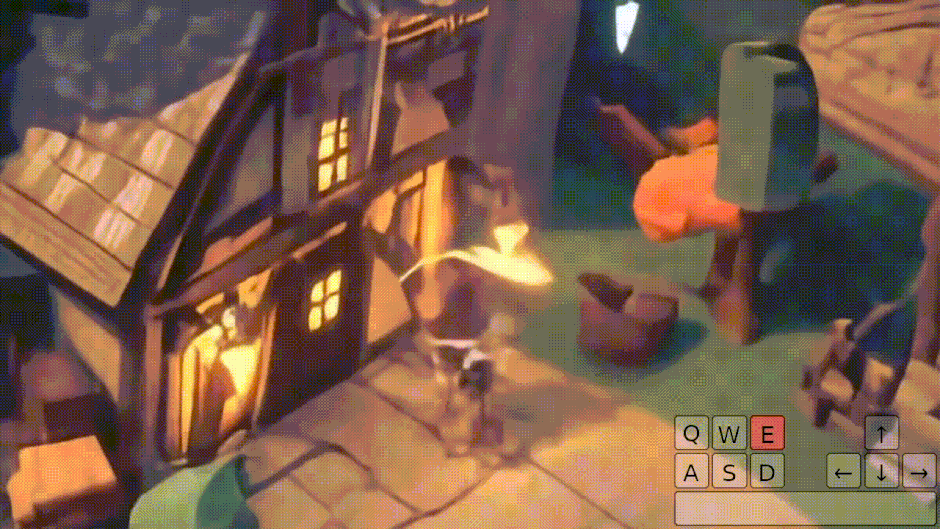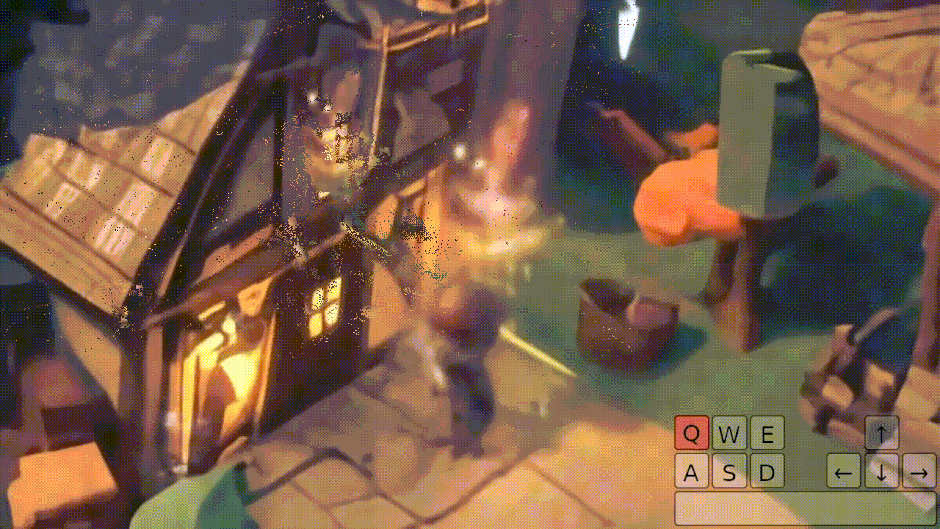
Genie 2: A large-scale foundation world model
Jack Parker-Holder, Philip Ball, Jake Bruce, Vibhavari Dasagi, Kristian Holsheimer, Christos Kaplanis, Alexandre Moufarek, Guy Scully, Jeremy Shar, Jimmy Shi, Stephen Spencer, Jessica Yung, Michael Dennis, Sultan Kenjeyev, Shangbang Long, Vlad Mnih, Harris Chan, Maxime Gazeau, Bonnie Li, Fabio Pardo, Luyu Wang, Lei Zhang, Frederic Besse, Tim Harley, Anna Mitenkova, Jane Wang, Jeff Clune, Demis Hassabis, Raia Hadsell, Adrian Bolton, Satinder Singh, Tim Rocktäschel
Project
Google DeepMind、より強化された新しい視覚言語AIモデル「PaliGemma 2」発表
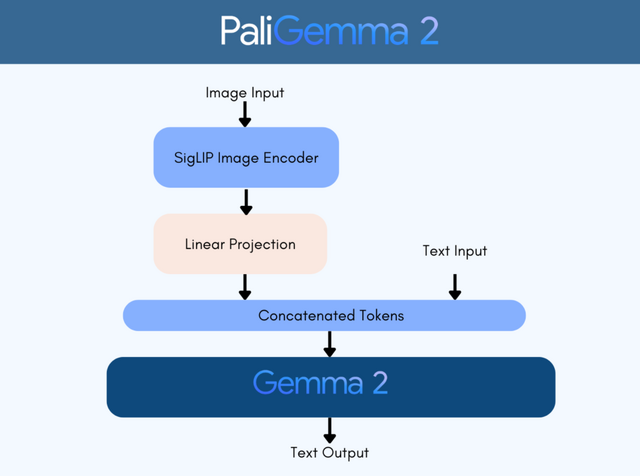
Google DeepMindは、画像と言語を組み合わせた多目的なAIモデル「PaliGemma 2」を発表しました。このモデルは、以前のPaliGemmaをベースに、より高性能な言語モデル「Gemma 2」を組み込んで機能を強化したものです。
PaliGemma 2は、画像認識を担当する「SigLIP-So400m」と、3つの異なるサイズ(3B、10B、28B)のGemma 2言語モデルを組み合わせています。また、3種類の画像解像度(224×224、448×448、896×896)に対応し、様々なタスクに適応できるように設計されています。
このモデルは3段階の訓練を経て開発されました。第1段階では、画像認識と言語モデルの基本的な組み合わせを学習し、第2段階では高解像度での処理能力を向上させ、第3段階では特定のタスクに合わせて微調整を行います。
PaliGemma 2は、画像の説明文生成、視覚的質問応答、物体の位置特定など、30以上の学術的なベンチマークテストで評価され、多くの課題で優れた性能を示しました。特に、文書内のテキスト認識、表の構造認識、分子構造の認識、楽譜の認識、医療画像のレポート生成など、新しい応用分野でも高い性能を発揮しています。

PaliGemma 2: A Family of Versatile VLMs for Transfer
Andreas Steiner, André Susano Pinto, Michael Tschannen, Daniel Keysers, Xiao Wang, Yonatan Bitton, Alexey Gritsenko, Matthias Minderer, Anthony Sherbondy, Shangbang Long, Siyang Qin, Reeve Ingle, Emanuele Bugliarello, Sahar Kazemzadeh, Thomas Mesnard, Ibrahim Alabdulmohsin, Lucas Beyer, Xiaohua Zhai
Paper | Blog | Hugging Face