



世界で最も難しいAI試験という「人類最後の試験」(Humanity’s Last Exam)において、これまでの最高得点はDeepSeek R1の9.4%でしたが、o3-mini-highが13%を獲得し抜き去りました。
しかし、数日後にdeep researchが26.6%を獲得しトップに躍り出ました。deep researchは2月3日に発表された、ChatGPT Proユーザーに提供中のリサーチ機能です。調査/分析能力の高さがSNS等で話題になっています。
AIアプリストア「Spaces」がHugging Faceに登場しました。ユーザーはAIアプリを共有でき、検索して探すことができます。現在、50万個(執筆現在)のAIアプリが収容されています。
さて、この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第82回)では、AIが生成する映像内の不自然な動き(動作中に余分な手足が出現したり・物が体をすり抜けたりなど)を回避する動画生成AI「VideoJAM」や、歌唱を入力に人物画を歌わせることができる動画生成AI「OmniHuman-1」を取り上げます。
また、3ドルで視覚言語モデルを強化する手法「R1-V」や、テキストのみで映像に動的コンテンツを追加できるVFX技術「DynVFX」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、GoogleのAIモデルが国際数学オリンピックで金メダル相当のパフォーマンスを達成した研究を単体記事で掘り下げています。
会話や歌唱に応じて人物画やキャラクター画像を喋らせる動画生成AI「OmniHuman-1」をByteDanceが開発
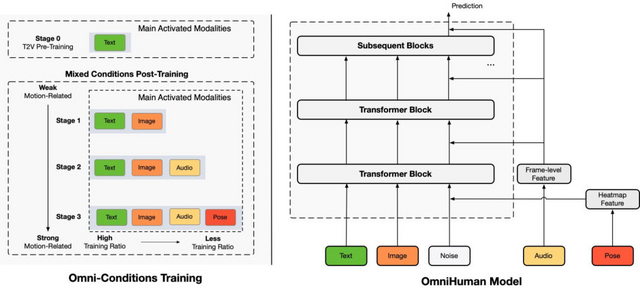
ByteDanceの研究チームが開発した「OmniHuman-1」は、音声と画像を入力として、自然な頭の動きや表情、ジェスチャーを含むリアルな人物動画を生成できる新しいフレームワークです。技術的基盤としてDiffusion Transformer(DiT)を採用しています。
OmniHuman-1の特徴的な点は、人間のアニメーションモデルのスケールアップにおいて、テキスト、音声、ポーズなどの複数の条件付けシグナルを組み合わせる手法を提案していることです。これらの条件は弱いものから強いものまで段階的に訓練され、より強い条件付けタスクはより弱い条件付けタスクとそのデータを活用できる仕組みになっています。
また、条件が強いほど低いトレーニング比率を使用するという原則に基づいて設計されています。これらの手法により、単一条件では使用できないデータの活用が可能となり、また異なる条件付けシグナルが互いを補完することで、より豊かで正確なモーション生成を実現しています。
トレーニングには18.7K時間におよぶ人物関連データが使用されており、このうち13%が口の動きとポーズがはっきり見える映像が選別されています。
特徴として、異なるアスペクト比や体の比率に対応できること、顔のクローズアップから全身まで様々な人物コンテンツに対応できること、会話と歌唱の両方に対応できること、人物と物体の相互作用や複雑なポーズを扱えること、そして異なる画像スタイルに対応できることが挙げられます。
実験結果では、OmniHuman-1は既存のモデルと比較して、ポートレートおよび身体アニメーションの両方のタスクで優れたパフォーマンスを示しています。



OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models
Gaojie Lin, Jianwen Jiang, Jiaqi Yang, Zerong Zheng, Chao Liang
Project | Paper
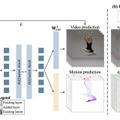
AIが生成する映像特有の“余分な手足が出現する・物が体をすり抜ける”などの現象を回避する動画生成AI「VideoJAM」
近年、高品質な動画を生成する技術は目覚ましい進歩を遂げていますが、動きや物理法則、物体間の相互作用を正確に表現することには依然として課題が残されています。
例えば、体操の動きのような複雑な動作を生成する際には、余分な手足が出現するなどの深刻な変形が見られます。また、フラフープが人体をすり抜けるなど、基本的な物理法則に反する挙動も観察されています。これらは、データセットに十分含まれているにもかかわらず、不自然な動きが生成されてしまいます。
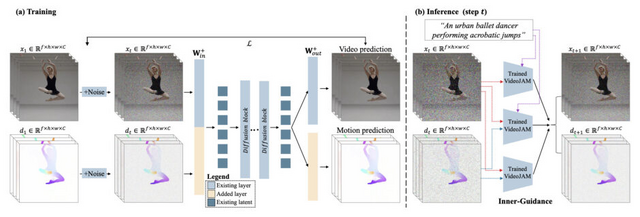
これらの問題に対処するため、研究チームは「VideoJAM」という新しいフレームワークを開発しました。このシステムは、動画モデルに明示的な動きの事前知識を組み込むことで、見た目と動きを統合的に学習することを可能にします。具体的には、訓練時に動画に対応する動きの表現を組み合わせ、モデルが両方の信号を予測できるように設計されています。
実装面では、アーキテクチャに2つの線形層を追加するだけという簡素な設計となっています。1つ目の層は入力段階で見た目と動きの信号を統合し、2つ目の層は出力段階で学習された統合表現から動きの予測を抽出します。さらに、生成時には「Inner-Guidance」と呼ばれる新しい仕組みを導入し、モデルが学習した動きの知識を効果的に活用できるようにしています。
実験結果によると、VideoJAMを既存の動画モデルに適用することで、様々なモデルサイズや動きのタイプにおいて、動きの一貫性が大幅に向上することが確認されました。また、データや規模の変更を必要とせず、どのような動画モデルにも容易に適用できる汎用性の高い手法であることも特徴です。


VideoJAM: Joint Appearance-Motion Representations for Enhanced Motion Generation in Video Models
Hila Chefer, Uriel Singer, Amit Zohar, Yuval Kirstain, Adam Polyak, Yaniv Taigman, Lior Wolf, Shelly Sheynin
Project | Paper
わずか3ドルで視覚言語モデルを強化する手法「R1-V」、2Bモデルが72Bモデルを上回る性能に
GitHubで公開されているR1-Vプロジェクトは、既存の視覚言語モデル(VLM)を低コストで強化する研究成果です。検証可能な報酬を用いた強化学習手法により、従来の教師あり学習よりも優れた性能を実現しました。
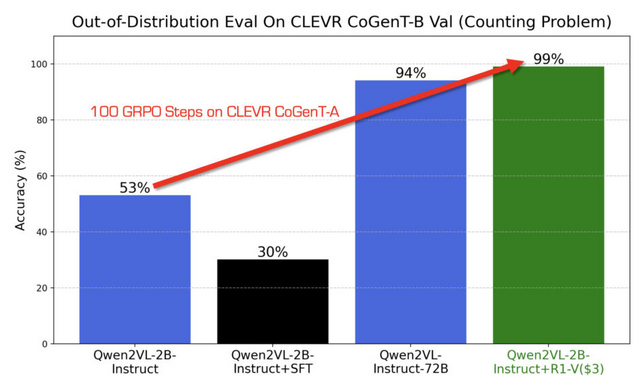
注目すべき点は、2Bパラメータという比較的小規模なモデルが、わずか100ステップの訓練で72Bモデルを上回る性能を示したことです。訓練には8台のA100 GPUを30分使用し、コストはわずか2.62ドルでした。
Qwen2-VL-2B-Instructモデルを強化した結果、計数問題の正確性が53%だった精度が、訓練後は99%の正確性に向上しました。

R1-V
Deep-Agent
GitHub
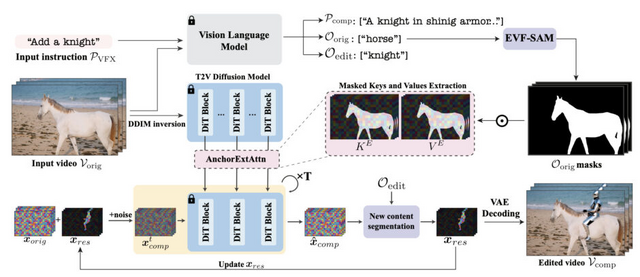
テキストのみで実写映像に動的コンテンツを追加できるVFX技術「DynVFX」
「DynVFX」は、実世界の動画に新しい動的なコンテンツを追加するVFX手法です。この技術は、入力動画とユーザーが提供する簡単なテキスト指示のみで、シーンに自然に溶け込む新しいオブジェクトや複雑な視覚効果を合成することができます。
このタスクには、いくつかの課題があります。まず、生成されるコンテンツは、オリジナルのシーンに自然に溶け込むよう、位置や外観、動きを考慮する必要があります。これには、オクルージョン(遮蔽)の適切な処理、カメラ位置に応じた適切な相対サイズと遠近感の維持、他の動的オブジェクトとのリアルな相互作用などが含まれます。
この手法は、動画変換モデル「CogVideoX-5B」を活用し、追加学習や微調整なしで高品質な合成を実現します。システムはユーザーの指示を受け取ると、Vision Language Model(VLM)を使って詳細な指示に変換し、それを基に新しいコンテンツを生成します。
また、Anchor Extended Attentionと呼ばれる新しい注意機構を導入したことにより、新しく生成されるコンテンツの位置や動きを、元の映像のコンテキストに合わせて正確に制御することができます。また、反復的な更新プロセスを通じて、追加されたコンテンツと元のシーンとの自然な調和を実現しています。
この技術を使用することで、例えば実写映像に巨大なクジラ、子犬、騎士など、様々な要素を追加することができます。追加された要素は、カメラの動きや遮蔽、他の動的オブジェクトとの相互作用を考慮しながら、シーンに自然に統合されます。
研究チームは、この手法の有効性を様々な実世界の映像で実証し、既存の手法と比較して優れた結果を示しました。



DynVFX: Augmenting Real Videos with Dynamic Content
Danah Yatim, Rafail Fridman, Omer Bar-Tal, Tali Dekel
Project | Paper