







1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第5回目は、オーディオドラマを自動生成するAI技術など、5つの論文をまとめました。
生成AI論文ピックアップ
テキストから音声合成による“ラジオドラマ”を生成するAI「WavJourney」
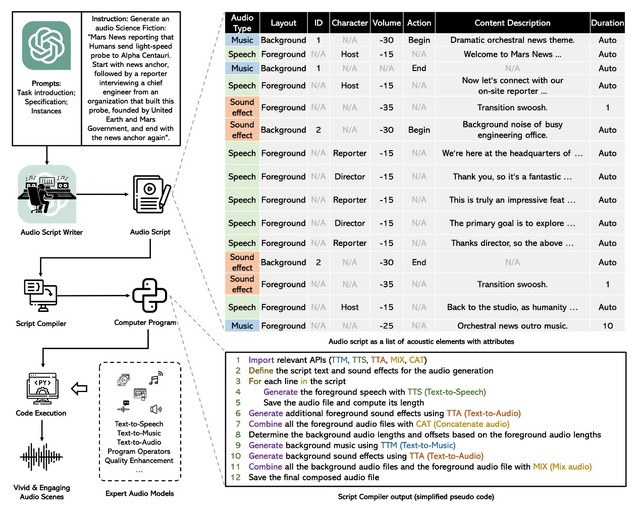
英国と香港の研究者らが提案する「WavJourney」は、与えられたテキスト命令に基づいてオーディオストーリーを自動的に設計し、音声、音楽、効果音の様々なサウンド要素を使用して対応するオーディオコンテンツを作成するための大規模言語モデル(LLM)です。
具体的には、WavJourneyはまずLLMに、あらかじめ定義された構造のフォーマットに従ったオーディオスクリプトを生成するように促します。これらのオーディオスクリプトには、音声、音楽、効果音のコンテクストが含まれており、それらの要素の関係も考慮します。
オーディオスクリプトをコンパイラに入力し、WavJourneyはそれに基づいてコンピュータプログラムを生成。このコンピュータプログラムには、タスク固有のオーディオ生成モデル、オーディオI/O関数、または計算操作関数が含まれています。そして、このプログラムが実行されることで、オーディオコンテンツが自動的に作成されます。
例として「ラブコメのラジオドラマを書いてください。カップルが高級レストランでデートしています。突然何かが起こり、雰囲気は台無しになりました」や、「電車が線路を走行し、続いて車両のドアが閉まり、警笛と踏切警報が鳴り響く中、男性が遠くで話している」といったテキストプロンプトで生成された音声サンプルなどがプロジェクトページで視聴可能となっています。
WavJourney: Compositional Audio Creation with Large Language Models
Xubo Liu, Zhongkai Zhu, Haohe Liu, Yi Yuan, Meng Cui, Qiushi Huang, Jinhua Liang, Yin Cao, Qiuqiang Kong, Mark D. Plumbley, Wenwu Wang
Project Page | Paper | GitHub
画像間のフレームを滑らかに埋める技術 動画生成AIに役立つ可能性
この研究では、事前に訓練された潜在拡散モデルを使用して、様々なドメインやレイアウトの画像間で高品質な補間画像を生成する手法を提案しています。この手法を用いることで、異なるスタイル、内容、ポーズを持つ画像のペアを組み合わせ、想像力豊かで高品質なシーケンスを作成することが可能です。
手法の概要として、新しいフレームを生成するために、2つの既存フレームのノイジーな潜在画像を補間します。元の入力画像からテキストプロンプトとポーズを抽出し、これを条件付け入力としてノイズ除去器に提供します。このプロセスを異なるノイズベクトルに対して繰り返すことで、複数の候補を生成することができます。そして、望ましい特性を持つ候補は、プロンプトに対するCLIP類似度を計算することで選択されます。
この手法は非常に汎用的であり、中間プロンプトの指定やセグメンテーション、バウンディングボックスなどの他の入力に対しても条件付けが可能であり、ビデオや画像生成における他の多くの手法と簡単に統合することができます。
現在の動画生成AIによるビデオ出力は、ランダムな動きのアニメーションが多く、細かなチラつきが見られることがありますが、この提案された画像補間技術を応用することで、フレーム間が一貫し、より滑らかなアニメーションを生成する可能性が期待されます。

Interpolating between Images with Diffusion Models
Clinton J. Wang, Polina Golland
Project Page | Paper | GitHub
使いやすい画像セグメンテーション用ライブラリ「Keras」
この研究は、セマンティックセグメンテーションのための包括的なライブラリ「Keras」を提案します。
ライブラリは、SegNet、FCN、UNet、PSPNetなど、セマンティックセグメンテーションで広く使用されているネットワークを含む、幅広いコレクションが提供されます。
使いやすいインタフェースを持っており、ユーザーは簡単に既存のセグメンテーションモデルを統合、カスタマイズ、拡張できます。
さらに、モジュール式で拡張可能な設計原理を採用しており、アーキテクチャの詳細と学習手順が記載されたドキュメントが提供されており、学習済みの重みも提供されているため、ユーザーはデータセット上でモデルを迅速に微調整できます。

Image Segmentation Keras : Implementation of Segnet, FCN, UNet, PSPNet and other models in Keras
Divam Gupta
Paper | GitHub
既存の画像生成AIを強化する「LLM-grounded Diffusion」 複数回の対話での生成、多言語生成が可能に
Stable Diffusionのような従来の拡散モデルは、空間的な推論や常識的な推論が必要なプロンプトに対して正確に従うことが難しいことがあります。しかし、LLM-grounded Diffusion (LMD) という新しいアプローチは、複雑な空間的推論や常識的推論を必要とするプロンプトから高品質な画像を生成することができます。
この手法は、テキストからレイアウトへの生成と、それに続くレイアウトから画像への生成の2段階プロセスで構成されます。第一段階では、LLMをコンテキスト内学習によってテキストガイド付きレイアウト生成器に適応させます。
第二段階では、第一段階で生成されたレイアウトを条件として、新しいレイアウト条件付き画像生成法を提案します。これらのことにより、指定された領域におけるオブジェクトインスタンスに対する精密な制御が可能になります。
この手法は市販のLLMや拡散モデルに適用できます。LMDを用いた拡散モデルは、ベースとなる拡散モデルよりも、プロンプトに従う推論を必要とするタスクで優れた性能を示しています。
また高度な推論能力を必要とするプロンプトからの画像生成が可能になるだけでなく、対話ベースのシーン指定による生成が行えます。さらに、基礎となる拡散モデルがサポートしていない言語のプロンプトからの生成も実行できます。

LLM-grounded Diffusion: Enhancing Prompt Understanding of Text-to-Image Diffusion Models with Large Language Models
Long Lian, Boyi Li, Adam Yala, Trevor Darrell
Project Page | Paper | GitHub | Hugging Face
ビデオ内の動く物体をマスク分割して高品質に追跡するシステム「HQTrack」
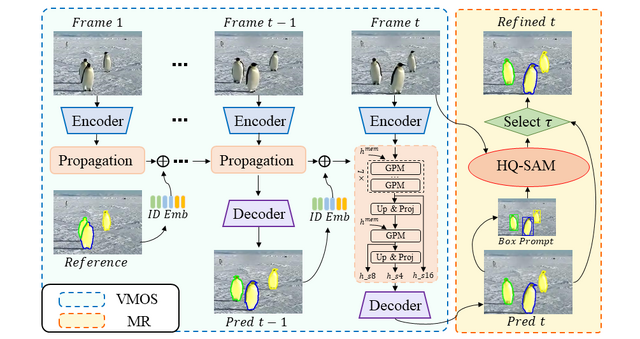
この研究では、動画内のオブジェクトをセグメーション(マスク分割)して高い精度で追跡するシステム「Tracking Anything in High Quality」(HQTrack) を提案します。
HQTrackは、主に2つの要素で構成されています。1つ目は「ビデオマルチオブジェクトセグメンテーション」(VMOS)で、これは動画の初期フレームにオブジェクトのマスクを示す情報があれば、それを動画全体のフレームに伝播してオブジェクトを追跡します。
ただし、VMOSはいくつかのクローズセットビデオオブジェクトセグメンテーション(VOS)データセットで学習されるため、この段階でのマスク結果は十分正確とは言えず、複雑なシーンなどへの汎用性には限界があります。
2つ目は「マスクリファイナー」(MR)で、これはセグメンテーションマスクの精製を担当する大規模な事前学習済みセグメンテーションモデルです。トラッキングマスクの品質をさらに向上させるために用いられます。
デモも公開されており、ユーザーはビデオフレーム内のオブジェクト(追跡したい対象)に点やボックスを付与することで、対象オブジェクトをマスクし、ビデオの全フレームにわたって追跡を行うことができます。
HQTrackは非常に強力なオブジェクト追跡とセグメンテーション能力を示しており、実際に「Visual Object Tracking and Segmentation (VOTS2023) チャレンジ」で2位に輝いた成果を持っています。

Tracking Anything in High Quality
Jiawen Zhu, Zhenyu Chen, Zeqi Hao, Shijie Chang, Lu Zhang, Dong Wang, Huchuan Lu, Bin Luo, Jun-Yan He, Jin-Peng Lan, Hanyuan Chen, Chenyang Li
Paper | GitHub | Demo




