






1週間分の生成AI関連論文の中から重要なものをピックアップし、解説をする連載です。第13回目は、画像生成AIを高品質にする手法、画像と文章を中間言語を用いずに入出力するモデルなど5つの論文をまとめました。
生成AI論文ピックアップ
数行のコード追加でStable Diffusionなどの生成画像を高品質にする手法「FreeU」
拡散モデル内でのノイズ除去ではU-Netをよく使いますが、その中の「skip connections」と「main backbone」と呼ばれる部分がとても大事です。skip connectionsは画像の細かい部分、例えば線やテクスチャに影響を与えます。一方で、main backboneは画像の全体的な形や色をクリアにする役割があります。
ただ、これら2つの部分がバランス良く動かないと、画像がおかしくなる可能性があります。この知見を基に、研究チームは「FreeU」と名付けた新しい戦略を提案します。この戦略は、追加のトレーニングや微調整(ファインチューニング)なしに画像の品質を良くします。
FreeUの枠組みは、既存の拡散モデルに簡単に組み込むことができます。わずか数行のプログラムを追加するだけで生成品質を向上させることができるのです。推論段階で2つの調整要素を変更するだけでOKです。また計算コストも増やさないと説明しています。
実験評価では、Stable Diffusion、DreamBooth、ReVersion、ModelScope、Rerenderといった基礎となるモデルを使って比較テストを行いました。FreeUを推論段階で使用することで、生成された画像やビデオの品質が明らかに向上することが確認されました。

FreeU: Free Lunch in Diffusion U-Net
Chenyang Si, Ziqi Huang, Yuming Jiang, Ziwei Liu
Project Page | Paper | GitHub
大規模言語モデルのトークンを効率よく増やす手法「LongLoRA」 Llama2を10万トークンに
大規模言語モデル(LLM)は通常、事前に定義されたコンテキストサイズで訓練されています。例えば、Llamaは2048トークン、Llama2は4096トークンです。しかし、この事前に定義されたサイズが、長い文章の要約や長い質問への回答など、多くの用途において制限となっています。
この制限を解消するために、いくつかの最近の研究では、LLMをより長いコンテキストサイズで訓練またはファインチューニングしています。しかし、長いシーケンスでLLMを一から訓練するのは計算負荷が高く、既存の事前訓練済みLLMをファインチューニングするのもコストがかかります。
この研究では、「LongLoRA」という新しいファインチューニング手法を紹介しています。この手法は、高い計算コストをかけずに、LLMが一度に考慮できるコンテキストを効率的に増やすことができます。これは「S2-Attn」という方法を用いて、長いコンテキストを小さなグループに分け、それぞれのグループで処理することで、長い情報を効率的に処理します。
例えば、もともと8192単語のテキストを処理する場合、LongLoRAはこのテキストを2048単語の4つのグループに分けます。そして、各グループ内でattentionを行い、隣り合うグループと情報を共有するように設計されています。
この手法は、他の既存の技術、例えばFlashAttention-2とも互換性があります。つまり、他の方法で既に最適化されたモデルにもこの新しい手法を簡単に適用できます。
さらに、LongQAという新しいデータセットも紹介されています。これは、長い質問とそれに対する答えを含むデータセットで、技術文書やサイエンスフィクション、他の書籍に関するさまざまな質問が含まれています。これを使用してモデルを訓練することで、モデルの対話能力を向上させることができます。
Llama2の7B、13B、70Bといったさまざまな大きさのモデルでコンテキストサイズを拡張する実験が行われました。結果、NVIDIA A100 GPUが8つ搭載された1台のコンピュータで、LLaMA2の7Bモデルを最大で10万のコンテキストサイズまで、または70Bモデルを最大で3万2千のコンテキストサイズまで増やすことができました。

LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, Jiaya Jia
Paper | GitHub
2.6兆トークンで訓練された、130億のパラメータを持つ多言語モデル「Baichuan 2」
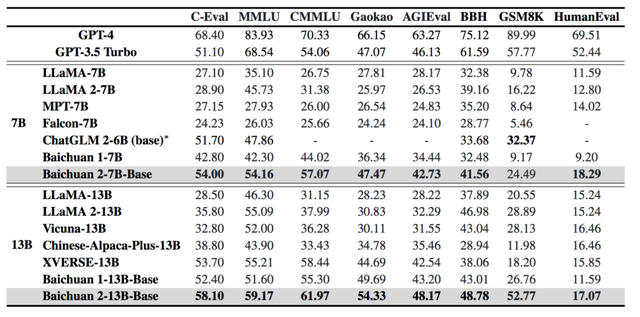
この研究では、多言語に対応した大規模な言語モデル「Baichuan 2」を紹介します。Baichuan 2には、7B(70億パラメータ)と13B(130億パラメータ)の2つのモデルがあり、これまでにない規模である2.6兆トークンによって訓練されています。
この大量の訓練データのおかげで、Baichuan 2は一般的なベンチマークテストで、前バージョンであるBaichuan 1よりも約30%高い性能を発揮しています。
特に、Baichuan 2は数学やプログラミングの問題においても高い性能を示し、医療や法律といった専門領域でも優れた成績を達成しています。Baichuan 2-7B-ChatとBaichuan 2-13B-Chatという、人間の指示に従うように最適化されたチャットモデルも公開されています。これらのモデルは対話と文脈理解に特に優れています。
このモデルは、公開されているベンチマークテスト(MMLU、CMMLU、GSM8K、HumanEvalなど)で、同規模の他のオープンソースモデルと比較して、同等かそれ以上の性能を示しています。さらに、医療や法律などの専門領域でも高い成績を上げています。
この評価結果から、Baichuan 2は多言語対応でありながら、高い性能と広範な適用可能性を持っていることが確認できます。
Baichuan 2: Open Large-scale Language Models
Aiyuan Yang, Bin Xiao, Bingning Wang, Borong Zhang, Ce Bian, Chao Yin, Chenxu Lv, Da Pan, Dian Wang, Dong Yan, Fan Yang, Fei Deng, Feng Wang, Feng Liu, Guangwei Ai, Guosheng Dong, Haizhou Zhao, Hang Xu, Haoze Sun, Hongda Zhang, Hui Liu, Jiaming Ji, Jian Xie, JunTao Dai, Kun Fang, Lei Su, Liang Song, Lifeng Liu, Liyun Ru, Luyao Ma, Mang Wang, Mickel Liu, MingAn Lin, Nuolan Nie, Peidong Guo, Ruiyang Sun, Tao Zhang, Tianpeng Li, Tianyu Li, Wei Cheng, Weipeng Chen, Xiangrong Zeng, Xiaochuan Wang, Xiaoxi Chen, Xin Men, Xin Yu, Xuehai Pan, Yanjun Shen, Yiding Wang, Yiyu Li, Youxin Jiang, Yuchen Gao, Yupeng Zhang, Zenan Zhou, Zhiying Wu
Paper | GitHub | Hugging Face
スマホで物体検出をリアルタイムかつ高精度で行う新モデル「Gold-YOLO」
オブジェクト(物体)検出の技術は、速度と精度のバランスを求めて進化しています。特に、YOLO(You Only Look Once)シリーズのようなシンプルで速度と精度が安定したモデルは、非常に高く評価されています。
この研究では、特にモバイルデバイス向けのリアルタイム物体検出におけるYOLOシリーズの新しいモデル「Gold-YOLO」を提案します。
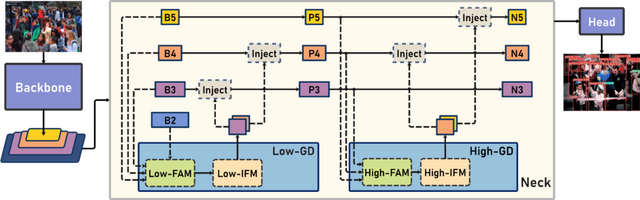
オブジェクト検出モデルは、主に「Backbone」(モデルの基礎となる部分)、「Neck」(Backboneから抽出された特徴を高度に変換する部分)、そして「Head」(物体のカテゴリや位置を具体的に決定する部分)の3つの部分から成り立っています。
現行のモデルには、Neckの部分で情報をうまく統合できないという問題が存在します。特に、異なる「層」の情報を統合する際に情報の損失が発生することが問題となっています。
この問題を解決する新しい方法として、「Gather-and-Distribute」(GD)メカニズムが提案されています。このメカニズムは、異なる層からの情報を全体的に集め、高い層に分散することで、情報の統合を効率よく実現します。これにより、Neck部分の性能が大幅に向上します。
新しい物体検出アーキテクチャである「Gold-YOLO」は、このGDメカニズムを取り入れることで、より高い精度の物体検出を実現しています。さらに、Gold-YOLOはImageNetでの事前学習により、モデルの収束速度と精度を大幅に向上させています。
既存のYOLOモデルとの比較でも、Gold-YOLOは顕著な精度を誇っています。具体的には、Gold-YOLO-Sは、先行研究のYOLOv6-3.0-Sよりも高いAP(Average Precision)を達成しています。
Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism
Chengcheng Wang, Wei He, Ying Nie, Jianyuan Guo, Chuanjian Liu, Kai Han, Yunhe Wang
Paper | GitHub | Gitte
画像と文章を“そのまま”入出力できる生成モデル「DreamLLM」 中間表現使わずに
「DreamLLM」という新しい技術は、他の類似技術と異なり、画像やテキストをそのままの形(生データ)で入力として受け取り、同じ形式で出力します。たとえば、有名な絵画の絵と「この絵を説明して」という指示を入力すると、DreamLLMは的確な説明文を生成できます。
多くのAIモデルは、データ(特に画像)を処理する際にそれを何らかの中間表現に変換します。しかし、DreamLLMは、このような中間表現を作成する代わりに、データをその原形のまま処理します。このアプローチの利点は、モデルがデータの本質をより直接的に捉え、より高精度な結果を出力する可能性が高いという点です。
さらに、DreamLLMは、インターネット記事などでテキストと画像が複雑に組み合わさっているようなデータでも、それをうまく理解し新しいデータを同じような形式で生成できます。
通常、このような複雑なデータの分析や生成は難しいのですが、DreamLLMは「token」と呼ばれるマークを使用して、テキスト内で画像がどこに配置されるべきかを予測します。
DreamLLMは、テキストと画像の理解能力で高い評価を受けています。具体的には、MMBenchとMM-Vetというテキストと画像の組み合わせを評価するテストで高得点を獲得し、MS-COCOという画像生成の精度を測るテストでも低いエラー率を記録しています。

DreamLLM: Synergistic Multimodal Comprehension and Creation
Runpei Dong, Chunrui Han, Yuang Peng, Zekun Qi, Zheng Ge, Jinrong Yang, Liang Zhao, Jianjian Sun, Hongyu Zhou, Haoran Wei, Xiangwen Kong, Xiangyu Zhang, Kaisheng Ma, Li Yi
Project Page | Paper | GitHub











