









もっと簡単に高画質の絵を出したい!
前回は画像生成AIなStable Diffusionを動かすにあたって、一番ポピュラーなインターフェースである AUTOMATIC1111のインストール方法と簡単な使い方をご紹介した。

AUTOMATIC1111はこれ一本で何でも出来る優れものなのだが、その分、設定項目が多く、ぱっと見、何が何だか分からない人も多いのではないだろうか。筆者も当初はそうだった。
加えてStable Diffusion 1.5 (SD 1.5)標準Modelだと、画像生成を指示する呪文(Prompt)でいくら頑張っても大したものが出ないため、実用的に使うには別途Modelダウンロードする必要があるなど、初心者にとっては面倒なことが山積みだ。
そこでStable Diffusionを使う新たなインターフェース、Fooocusをご紹介したい。インストールはbat一発、起動/アップデートもbat一発、Modelも初期起動時に自動的にダウンロードと非常にシンプルなことが特徴のひとつ。
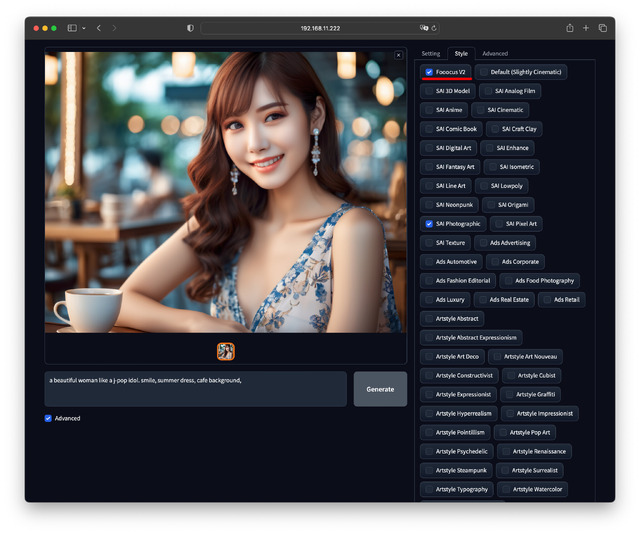
そしてなにより、起動直後の画面はご覧のようにPromptしか入力する部分が無く、悩む場所は皆無なのに、出てくる絵が驚異的という優れたインターフェースだ。
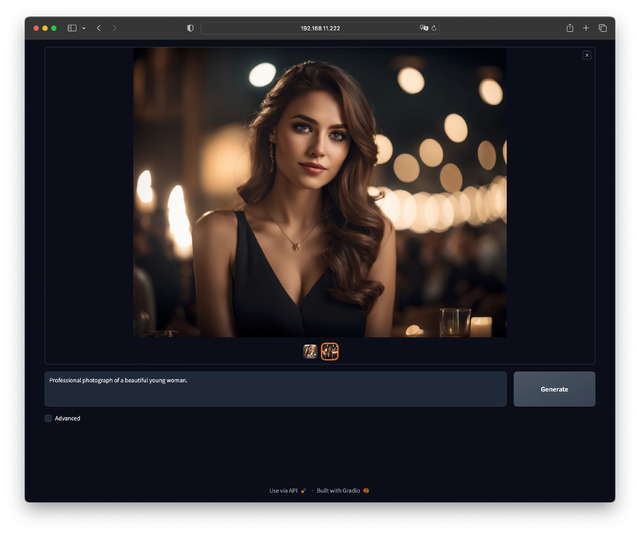
簡単なPromptでこのような絵がいきなり出るカラクリはいろいろあるのだが、まずベースとなる画像生成モデルがSD 1.5ではなく、より新しい SDXL 1.0だからが最大の理由だ。このため必要なマシンリソースが少し上がってしまい、必要なVRAMが増える。
NVIDIAのGPU
VRAM 8GB以上
ただこれに該当するPCを用意できなくても、クラウドのGoogle Colabでも動かすことができるので安心して欲しい。
FooocusをローカルPCにインストールして使ってみる
まず先の要件にあったPCが手元にあるケース。GitHubからファイルをダウンロード、展開し、run.batを起動。たったこれだけでOK。
初期起動時はGB級のファイルを数本ダウンロードするため少し時間はかかるものの、これは初回だけだ。
さきほどPrompt入力のみの画面をお見せしたが、もう一つの顔として、Advancedにチェックを入れるとSettings、Style、Advancedのタブが現れる。
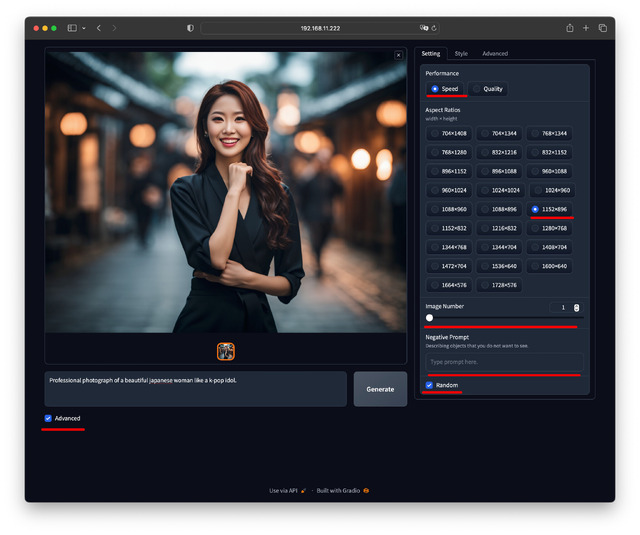
それぞれの設定項目として、まず Settings タブにはクオリティ (Speed または Quality)、アスペクト比(縦横比と解像度)、Image Number (一度に作る画像の数)、Negative Prompt、Random がある。
デフォルトは順に、Speed、1152 x 896、2、無し、Randomとなっている。
ここを例えば、縦位置の画像が欲しい場合は解像度を 832✕1216、1枚ずつ確認したい場合はImage Numberを1などと設定する。
Randomのチェックは、生成画像の元となる乱数を毎回生成するかどうか。AUTOMATIC1111でいうところのSeedだ。チェックを外すと、同じSeed を元にして大まかな構図等を固定したまま、他の要素を調整して生成できる。
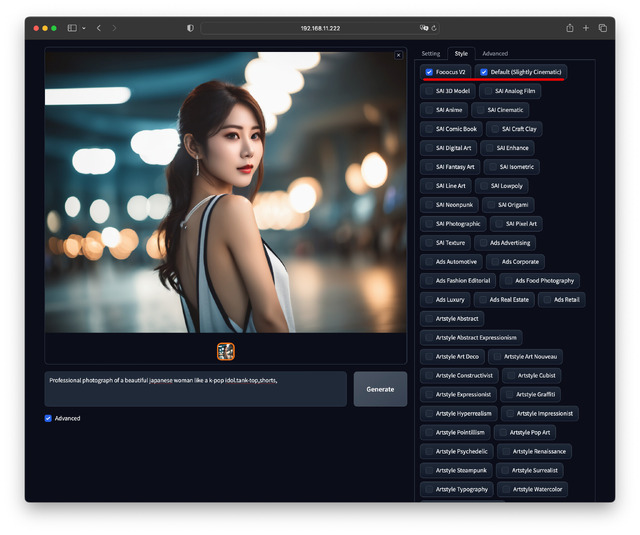
Styleタブは用意された絵柄を選ぶ、Fooocus独自の部分だ。例えば写真やアニメ、ロボット、あるいはサイバーパンク風、アールデコ風などを選ぶことができる。デフォルトはSlightly Cinematic。
100以上というものすごい数のStyleが並んでおり、UI的にここだけは個人的に疑問の部分だ。
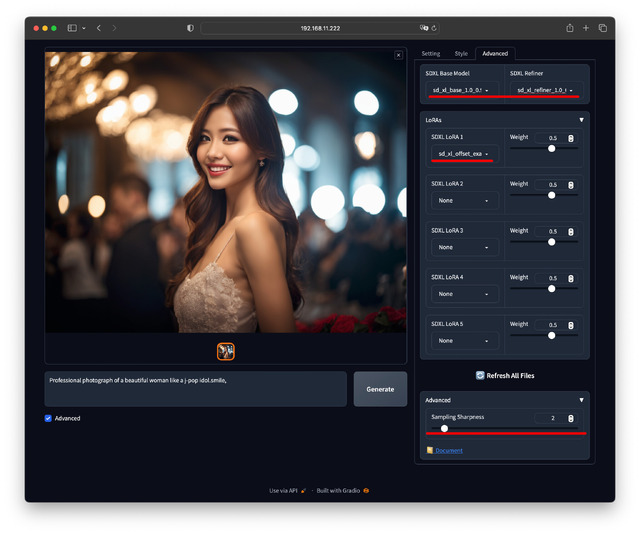
Advancedタブは、Base Model、Refiner、そしてLoRAを指定する部分となる。
LoRAの概要は第六回の記事を参照してほしい。AUTOMATIC1111ではPromptに<lora:xxxx:0.5>とテキストで入力したが、Fooocusではこの項目のLoRAsで使いたいLoRAを選び、重みは横のスライダーで調整する。
最大5つまで使用できるが、1つ目はデフォルトでsd_xl_offset_example-lora_1.0が入っている。これは作者によると重み0.5以下であれば常に良い結果になるとの話しなので、そのままでいいだろう。
一点、SDXLではBase Modelに加えRefinerの二段構えでより詳細に生成する仕掛けになっているが、このRefinerもModelの一つで、絵柄の傾向に影響を与える。
人に関しては西洋系中心で学習したらしく、アジア系にRefinerをかけると半端に西洋人化してしまうので、日本人などを出す時はNoneにした方が良い。
FooocusをGoogle Colabで実行する
Google Colabでの実行はもっと簡単だ。GitHubのこのリンクでNoteが開くので、実行ボタンを押せばインストールが始まり、起動するとURLが出るので、それをクリックすればFooocusが使えるようになる。
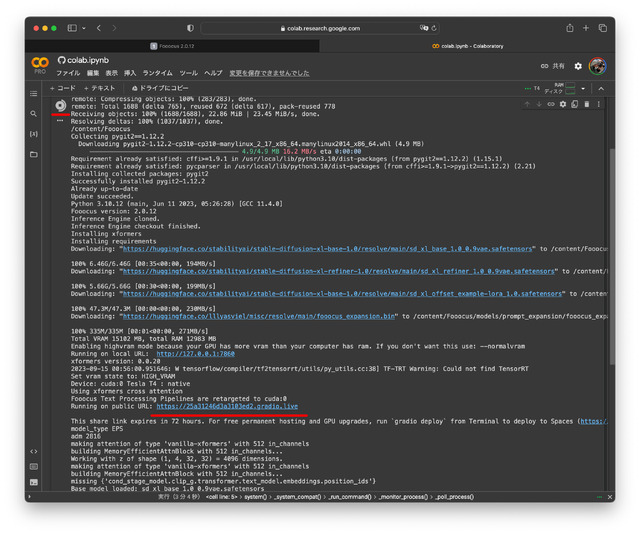
無料で試して楽しめそうなら、もう少しGPU利用可能時間の多い有料のGoogle Colab Proにするのもいいだろう。強力なGPUを買うよりずっと安上がりだ。
Fooocusの遊び方
簡単なPromptで凄い絵が出るカラクリの2つ目はこのStyle指定にある。例えばよくあるパターンの呪文だと以下のようになる。
Prompt:
(8k, best quality, masterpiece, ultra highres:1.2),
photo of japanese woman, 20yo, camisole, shorts, smile, pool background,thigh focus, standing,Negative Prompt:
illustration,3d,sepia,(painting),cartoons,sketch,(worst quality:2),
Prompt一行目は画質に関するPrompt、Negative Promptは出てほしくないものが並ぶ。すなわちStable Diffusion側の都合上必要なものであって、特に理由があって意図的に操作しない限り、ユーザーは本来知らなくても良い部分だ。
Fooocusはここに手を入れ、インターフェース側で多数のStyleをあらかじめ定義してある。Styleごとに最適化した画質系のPromptとNegative Promptを用意し、ユーザーが入力したPromptをそこへはめ込む形式となっている。
photo of japanese woman, 20yo, camisole, shorts, smile, pool background,thigh focus, standing,
つまり先のPromptだと、この部分だけ書けばいいように工夫したと言うことだ。しかも指定したStyleに沿った絵が出るよう最適化済。
試しに同一Prompt / Seedで、Styleだけを4パターン変えてみた。最後の一つは複数指定だ。
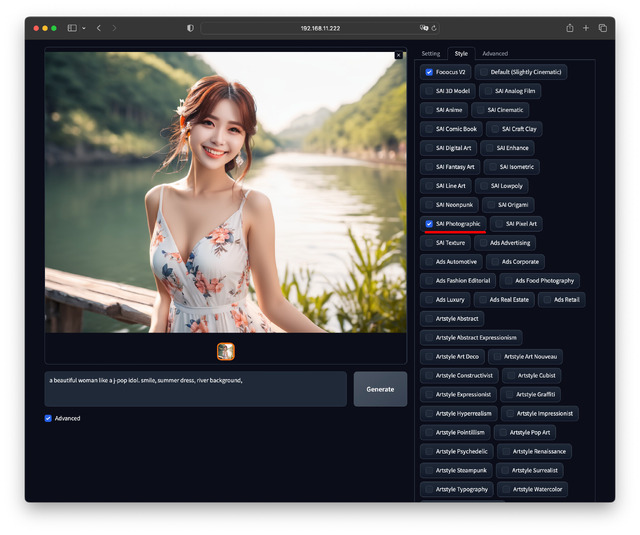
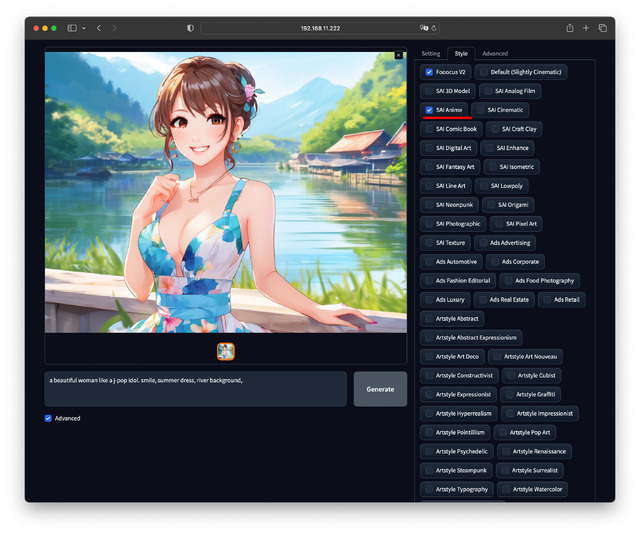
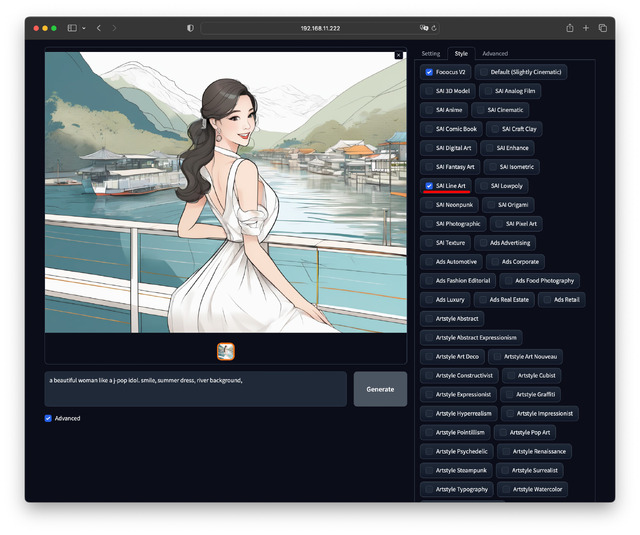
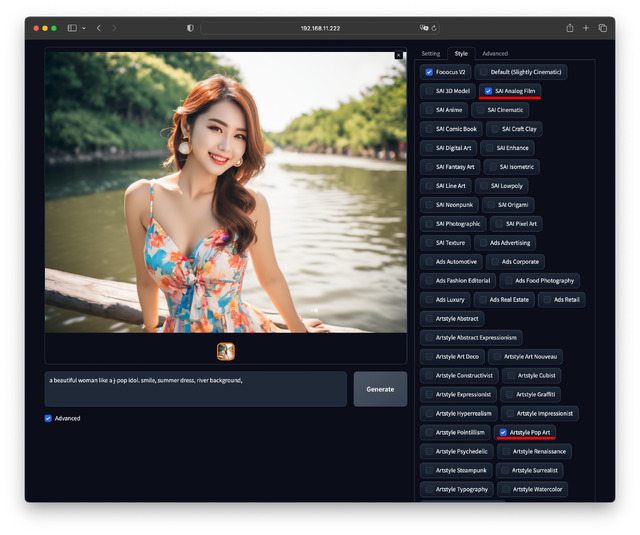
如何だろうか。何時も悩む画質系のPromptやNegative Promptへ何を書くかを考える必要も無く、素直に出したいもののみPromptへ書けば良く、ユーザーにとっては分かりやすい。
もともとSDXLのModelは振り幅が広く、リアル系Modelでもある程度イラスト系の絵が出せる。この特性をうまく利用したのがStyleとなる。
更にv2.0.0以降では、Midjourneyでいうプロンプト拡張機能的なものを導入。入力した呪文のイメージを膨らまし、少しずつ異なる絵も出せるようになった。Seed固定したままON/OFFしてみると面白い。いろいろ試した範囲だとONの方が結果が良かった。デフォルトONなのも納得だ。
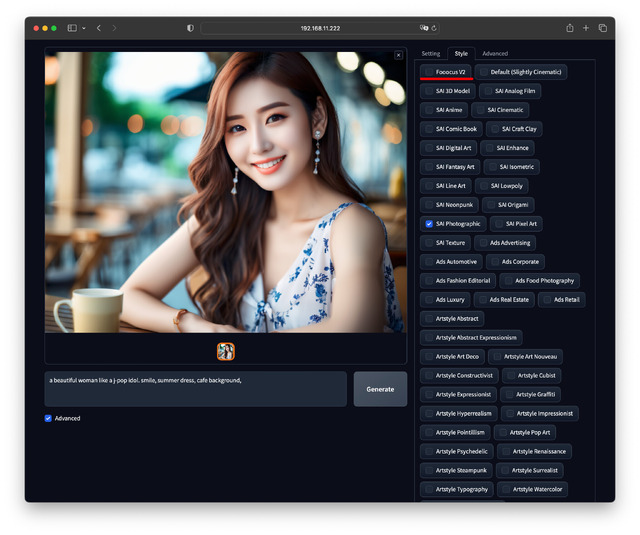
このようになかなか凄いSDXL / Fooocusだが、とは言え、 SDXLの標準Modelはアジア系人物の生成が苦手だ。恐らく西洋系ほど多く学習していないのが理由だろう。
しばらく標準Modelで遊んだ後、やはりもっとリアルなアジア系を出したいとなると、civitaなどからModelやLoRAをダウンロードし使うことになる。
この場合、[Fooocusをインストールしたフォルダ]/modelsにcheckpints/、loras/フォルダがあるので、そこへ入れれば良い(但しどちらもSDXL版)。
再起動は必要ないが、Advancedタブの下にある[Refresh All Files]をクリックする必要がある。リフレッシュするとリストが更新され、新たに追加したModelを選択できるようになる。
もう少しだけ自由度や機能が欲しい人向けのFooocus-MRE
以上のように、Fooocusを使えば手軽に色々な絵を出すことができる。絵柄のもととなるModelやLoRAも追加/変更できるため、自由に絵柄を変更することも可能だ。
ただもう少しStable Diffusion的な使い方、例えばModelに合わせてStep数やCFG scaleを変えたい、構図やポーズの指定にControlNetを使いたい、画像から画像を生成する img2imgを使いたいと言った部分には対応できない。そもそもアプリのコンセプトが、簡単にSDXLの高画質を!なので仕方ない部分でもある。
そんな痒い所に手が届くアプリが、FooocusからFork(枝分かれ)したFooocus-MRE。筆者自体もこれが出てからAUTOMATIC1111を触る時間がかなり減ったほどのスグレモノだ。執筆時点ではFooocusの機能追加に追従しており、同じ機能+αの構成となっている。
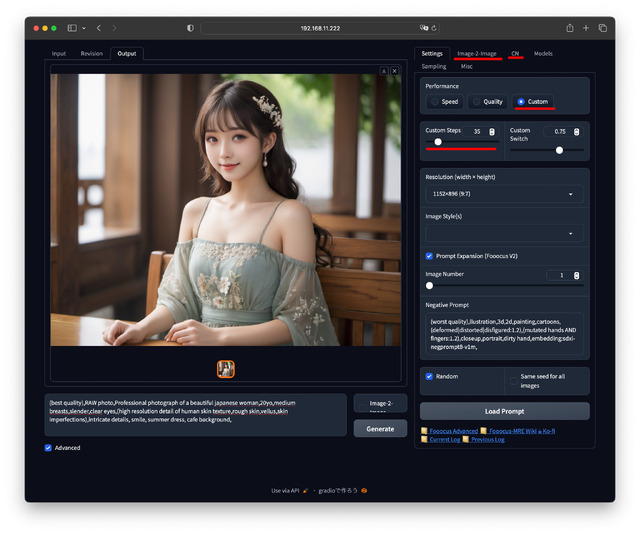
インストール方法はもともとベースがFooocusなのでほぼ同じ。起動直後の画面はこんな感じとなる。
もちろんGoogle Colabでも起動可能。本家のFooocusでは物足らなくなった人にはFooocus-MREをお勧めしたい。
上の画像の例ではStyle無しとし、クオリティ系のPrompt、Negative Promptなどもフルに入れ、ほぼAUTOMATIC1111と同じような使い方をしている。Modelはfuduki_mix。当然SDXL標準のModelより日本人らしい顔になる。
丁度執筆中にimg2imgでのUpscaleにも対応し、個人的に欲しい機能は出揃った。AUTOMATIC1111の出番が更に減りそうだ。
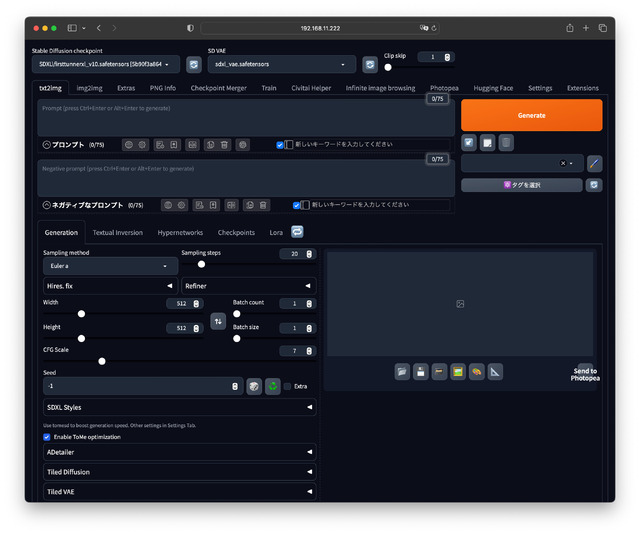
今回の締めのグラビア
今回は特に捻りも無く、普通にFooocus-MRE / SDXLを使ったカフェの写真だ。ModelはfirsttunnerXLを使用。SDXLの割にStep数20、CFG scale 4とかで済み(普通だと倍近く)=速く処理が終わる、肌やアジア系も自然なのでお気に入りの一つだ。

扉の写真は特に場所指定無くカフェ、グラビアはパリのカフェとした。少しは違いが出ているだろうか?(笑)
次回は、今回書き切れなかったFooocus-MREの特徴であるimage-2-imageやControlNetを使った具体的な遊び方を書いてみたいと思う。
生成AIグラビアをグラビアカメラマンが作るとどうなる? 連載記事一覧