前回の連載で紹介したStable Diffusion開発チームの新会社Black Forest Labsによる画像生成AI「FLUX.1」が注目を集めています。動画生成AIの「Gen 3」との組み合わせによる映像や、LoRAやControlNetなどの周辺技術も登場しています。そして、Black Forest Labsはテキストから動画を生成するText to Videoの予告を公開しました。

Preferred Networks(PFN)の子会社Preferred Elements(PFE)は、独自開発の国産大規模言語モデル「PLaMo」(プラモ)を発表しました。日本語性能においてGPT-4を上回る精度を達成しています。商用版のPLaMo 1.0 Primeは今秋リリース予定とし、現在はβ版の無料トライアルの申し込みを受け付けています。
さて、この1週間の気になる生成AI技術をピックアップして解説する「生成AIウィークリー」(第59回)では、オープンソースの動画生成AI「CogVideoX」や、動画理解でGPT-4VやClaude 3.5 Sonnetなどを精度で上回るMLLM「MiniCPM-V 2.6」を取り上げます。また、Appleが発表した、画像生成AI「マトリョーシカ拡散モデル」も見どころです。
生成AI論文ピックアップ
テキストから動画を生成する高性能なオープンソースAIモデル「CogVideoX」
清華大学の研究チームが開発した、テキストから動画を生成するAIモデル「CogVideo」は、94億のパラメータを持ち、既存の公開モデルを大幅に上回る性能を示しています。
CogVideoは、事前学習済みの画像生成モデル「CogView2」の知識を継承しており、独自のフレームワークを用いてテキストと動画の意味的なつながりを強化しています。また、時間と空間のデュアルチャンネルアテンション機構とSwin Transformerの概念を応用することで、効率的な動画生成を実現しています。
今回、CogVideoを進化させたアップグレード版がGitHubで新しく更新されました。「CogVideoX-2B」と呼ばれるこのモデルは、最大226トークンの入力プロンプトを受け取り、720×480ピクセルの解像度で6秒間の動画を生成します。



CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, Jie Tang
Paper | GitHub
iPadでリアルタイムに動作するMLLM「MiniCPM-V 2.6」動画理解でGPT-4Vを上回る精度
「MiniCPM-V 2.6」は、MiniCPM-Vシリーズの中で最新かつ最も高性能なMLLMモデルです。iPadなどのエンドデバイスへのリアルタイムビデオ理解をサポートします。SigLip-400MとQwen2-7Bを基盤とし、合計8Bのパラメータを持っています。
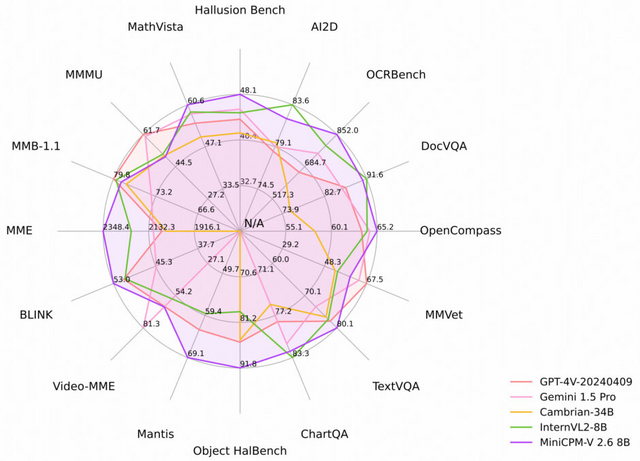
MiniCPM-V 2.6は、単一画像、複数画像、ビデオ理解においてGPT-4Vを上回ります。具体的には、単一画像理解タスクにおいて、GPT-4o mini、GPT-4V、Gemini 1.5 Pro、Claude 3.5 Sonnetといった大規模モデルを上回る結果を示しています。動画理解においては、字幕の有無にかかわらず、GPT-4V、Claude 3.5 Sonnet、LLaVA-NeXT-Video-34Bを超える性能を発揮しています。
OCR(光学文字認識)能力も卓越しており、最大180万ピクセル(1344×1344相当)の高解像度画像を、アスペクト比を問わず処理可能です。OCRBenchでは、GPT-4o、GPT-4V、Gemini 1.5 Proといった強力なモデルを上回る最先端の性能を達成しました。
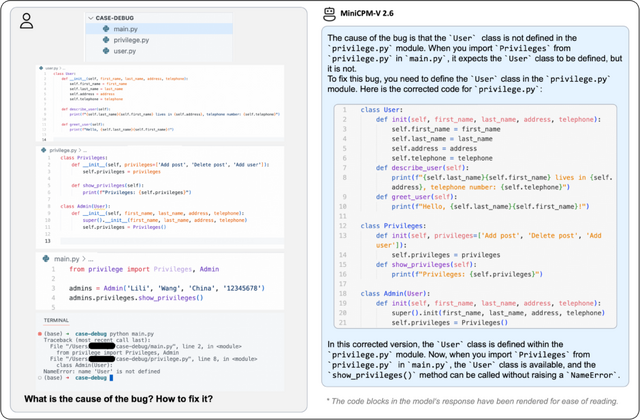
英語、中国語、ドイツ語、フランス語、イタリア語、韓国語などの多言語対応もサポートしており、コーディングのバグ原因や修正案も提案します。



MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, Qianyu Chen, Huarong Zhou, Zhensheng Zou, Haoye Zhang, Shengding Hu, Zhi Zheng, Jie Zhou, Jie Cai, Xu Han, Guoyang Zeng, Dahai Li, Zhiyuan Liu, Maosong Sun
Paper | GitHub | Hugging Face | Demo
Apple、高品質な画像を生成できるAI「マトリョーシカ拡散モデル」発表
この研究では、高品質な画像や動画を生成する新しいモデル「マトリョーシカ拡散モデル」(Matryoshka Diffusion Models、MDM)が提案されています。MDMは、入れ子人形のように小さな画像から大きな画像を効率的に生成する能力を持っています。
従来の高解像度画像生成手法は複雑で困難でしたが、MDMは複数の解像度を同時に扱い、それぞれの情報を巧みに組み合わせます。具体的には、「Nested UNet」アーキテクチャを用いて複数解像度の入力を同時にノイズ除去し、低解像度から高解像度へと段階的に学習を進めます。これにより、計算量を抑えつつ効率的な学習が可能となり、高解像度生成の最適化が大幅に改善されました。
研究チームは、クラス条件付き画像生成やテキストによる画像・動画生成など、様々なタスクでMDMの有効性を実証しました。特に注目すべきは、1024×1024ピクセルという高解像度でのモデル学習に成功し、比較的小規模なCC12Mデータセット(約1200万枚の画像)を用いて強力なゼロショット汎化能力を示したことです。

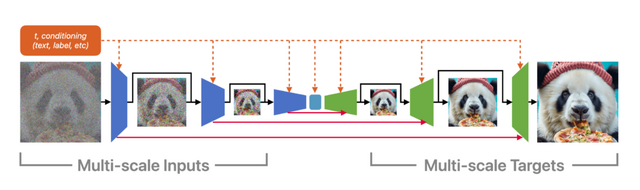
Matryoshka Diffusion Models
Jiatao Gu, Shuangfei Zhai, Yizhe Zhang, Josh Susskind, Navdeep Jaitly
Paper | GitHub
UVマップを使用してリアルな3Dモデルを生成する「Object Images」
3Dアセットを生成するAIモデルを構築する上で、幾何学的不規則性と意味的不規則性という2つの課題があります。幾何学的不規則性は3Dモデルの頂点や接続性が不均一であることを指し、意味的不規則性は複雑な部品構造やセグメンテーションを持つことを意味します。これらの特性により、従来の3D形状を機械学習モデルで扱うことが非常に困難でした。
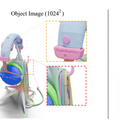
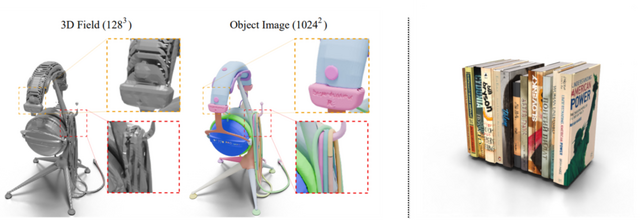
これらの課題に対処するため、研究者たちはUVマップを使用してリアルな3Dモデルを生成する「Object Images」を導入しました。このアプローチは、複雑な3D形状を64×64ピクセルの画像に変換することで、表面の幾何学、外観、およびパッチ構造を効果的にカプセル化します。実際には、1024×1024の高解像度を生成し、それを64×64に縮小して使用しています。
これにより、ポリゴンメッシュに内在する幾何学的および意味的不規則性の両方の課題に対処し、Diffusion Transformerのような画像生成のために開発された拡散モデルを3D形状の生成に応用することが可能になります。
研究チームは、このアプローチの有効性を検証するために、Amazon Berkeley Objects(ABO)というデータセットを使用しました。このデータセットには、プロのデザイナーが作成した約8000個の高品質な3Dモデルが含まれており、63種類のカテゴリーに分類されています。これらのモデルには、テクスチャやマテリアル情報、そして2D展開図が付属しています。
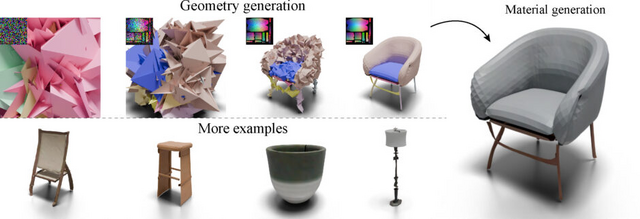
実験の結果、Object Imagesを用いて生成された3D形状は、最新の他の3D生成モデルと同等以上の品質を達成しました。特筆すべきは、細い構造や開いた表面など、従来の手法では生成が困難だった形状も正確に再現できた点です。さらに、物理ベースレンダリングに対応した高品質なマテリアル情報も同時に生成できることが示されました。
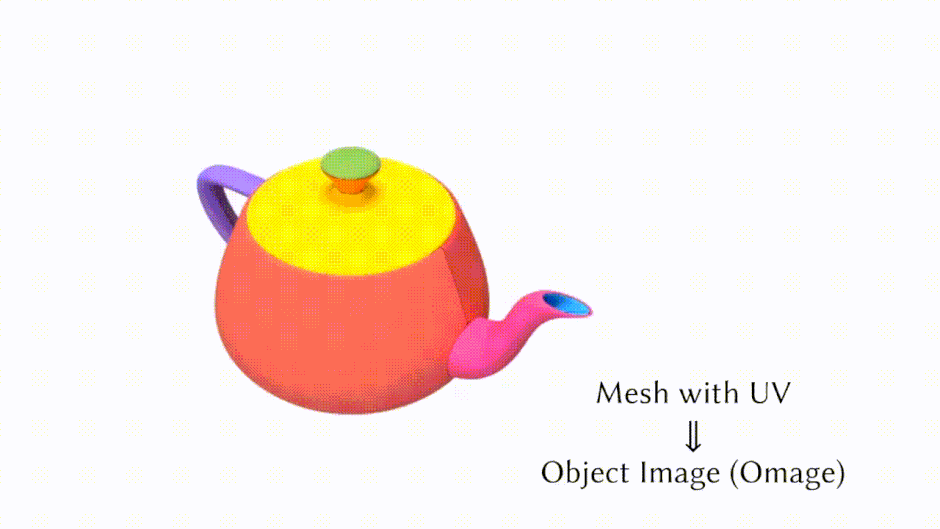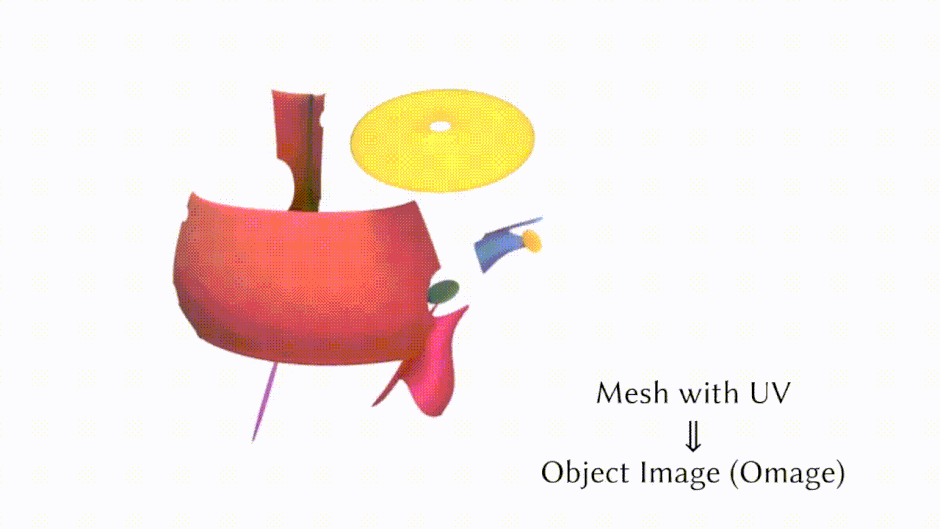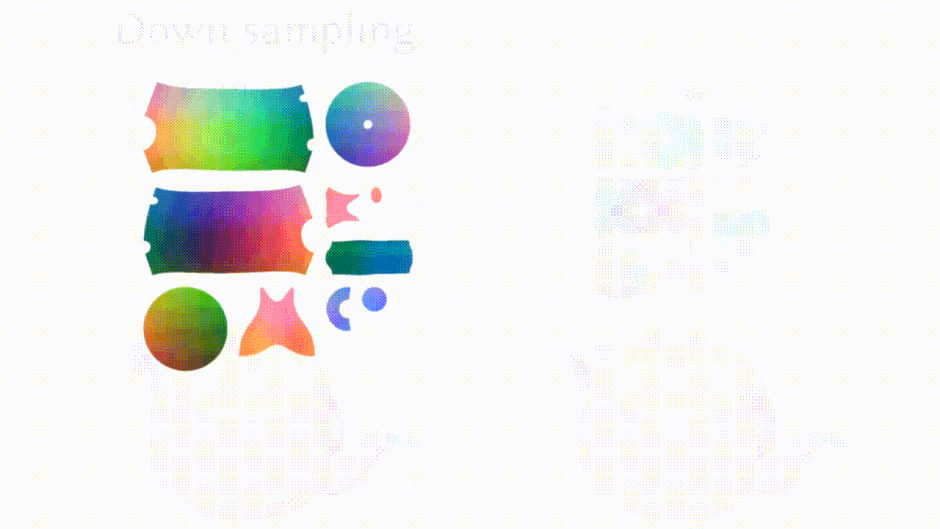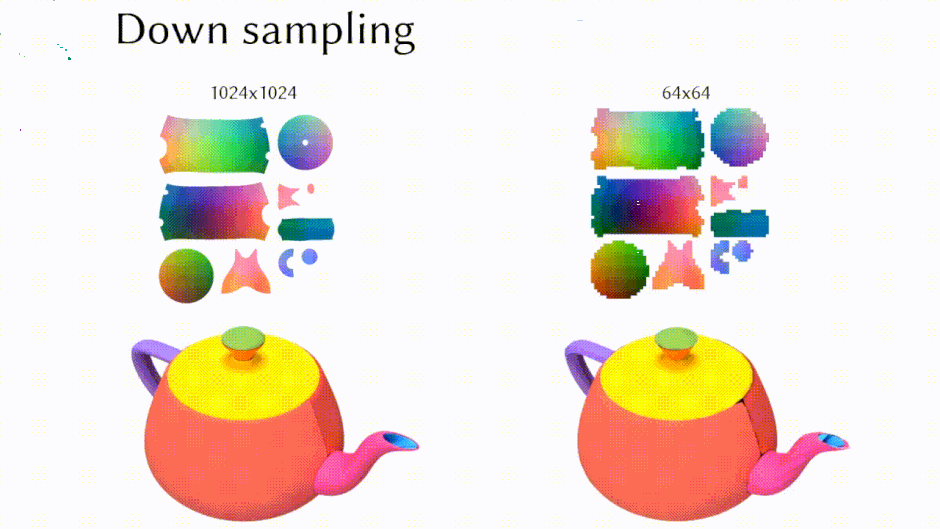

An Object is Worth 64×64 Pixels: Generating 3D Object via Image Diffusion
Xingguang Yan, Han-Hung Lee, Ziyu Wan, Angel X. Chang
Project | Paper
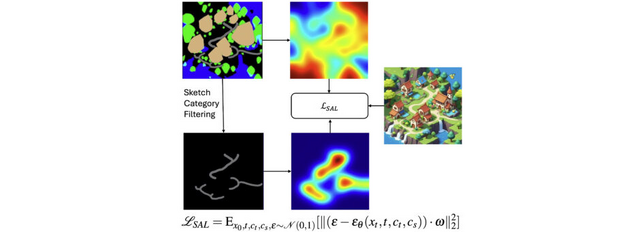
手書きのスケッチからプレイ可能な3Dゲームシーンを生成するAI「Sketch2Scene」
この研究では、手描きのスケッチやテキストの説明など、ユーザーのプロンプトからインタラクティブな (プレイ可能な)3Dゲームシーンを自動的に生成する新しいアプローチを提案します。
3Dシーン生成のための大規模な訓練データ不足という主な課題に対処するため、この手法は事前学習済みの大規模2D拡散モデルを活用し改良しています。
Sketch2Sceneの処理は主に3つの段階で構成されています。まず、ユーザーのスケッチとテキストプロンプトから2D等角投影画像を生成します。次に、生成された2D画像から地形のベースマップを抽出し、画像理解AIを使って地形の高さマップ、地表のテクスチャ、前景オブジェクトの配置情報などを抽出します。最後に、これらの情報を基に、3Dゲームエンジンで実際に動作する3Dシーンを構築します。
研究チームは、山や川のある自然景観、ポケモンスタイルの町並み、雪景色など、多様なシーンでの生成例を示し、システムの有効性を実証しました。特に、地形のベースマップ生成に関しては、既存手法と比較してより一貫性のある結果が得られることが示されています。
生成されたシーンはUnityなどの一般的なゲームエンジンで直接利用できるため、実用性が高いことも特長です。さらに、生成された3Dシーンは編集可能で、例えば木の種類や色を変更することで、同じシーンの異なるバリエーションを作成できます。