
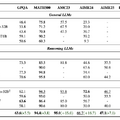




中国アリババは、大規模言語モデル(LLM)「QwQ-32B」を発表しました。32Bパラメータでありながら、DeepSeek-R1(671B)と同等の性能を達成したといいます。
中国テンセントは、自社の動画生成AI「HunyuanVideo」をベースにした画像から映像を生成する特化型オープンソースモデル「HunyuanVideo-I2V」を公開しました。
さて、この1週間の気になる生成AI技術・研究をいくつかピックアップして解説する「生成AIウィークリー」(第86回)では、大規模言語モデル「QwQ-32B」を改良した「START」や、PDFからのテキスト抽出が安く高品質にできるツール「olmOCR」を取り上げます。
またGPT-4o搭載ポケモンバトル向けAIエージェント「PokéChamp」、マイクロソフトの小規模言語モデル「Phi-4-Mini」と小型マルチモーダルモデル「Phi-4-Multimodal」をご紹介します。
そして、生成AIウィークリーの中でも特に興味深いAI技術や研究にスポットライトを当てる「生成AIクローズアップ」では、招待コードが高額取引されているくらい中国で過熱しているAIエージェント「Manus」を単体記事で取り上げています。
中国アリババ、大規模言語モデル「QwQ-32B」を改良した「START」発表。Pythonインタープリターで丁寧な推論
大規模言語モデル(LLM)の推論能力は、Chain of Thought(CoT)から始まり、OpenAIやDeepSeekの強化学習モデルによるLong Chain of Thoughtへと進化してきました。しかし、複雑な計算で幻覚(ハルシネーション)を起こすという問題があります。
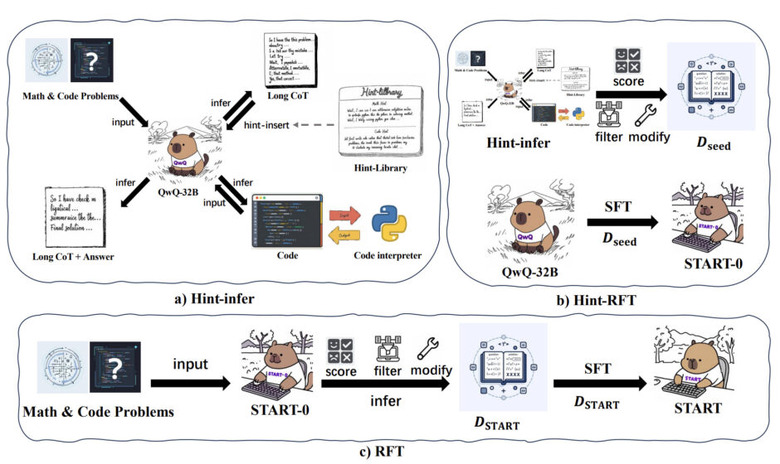
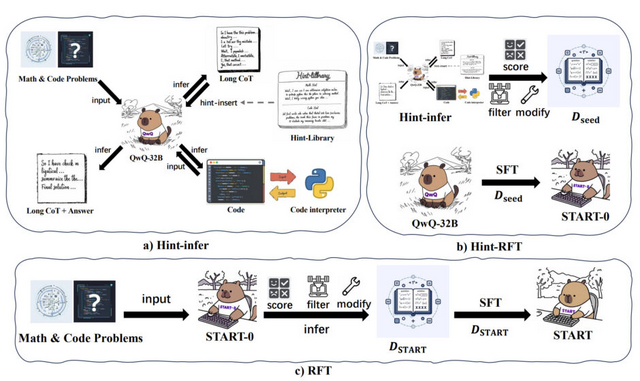
そこで本研究では、「START」(Self-Taught Reasoner with Tools)というモデルを開発しました。このモデルはコード実行を通じて、複雑な計算、自己チェック、多様な方法の探索、自己デバッグを行うことができます。
大規模推論モデル(LRM)は通常、複雑な推論タスクのトレーニング中に問題解決のみに焦点を当てるため、指示に従う一般化能力が失われることが挙げられます。LRMにおける次のトークン予測の性質を考慮し、LRMの推論プロセス中または最後に直接ヒントを挿入して、モデルにコードを書いてPythonインタープリターを呼び出すように促すことを試みました。
「Hint-infer」と呼ぶこの方法で、LRMが生成したツール呼び出しを含む推論軌跡をスコアリング、フィルタリング、修正し、その後LRMを微調整します。このフレームワークを通じて、QwQ-32Bモデルを微調整し、STARTを実現しました。
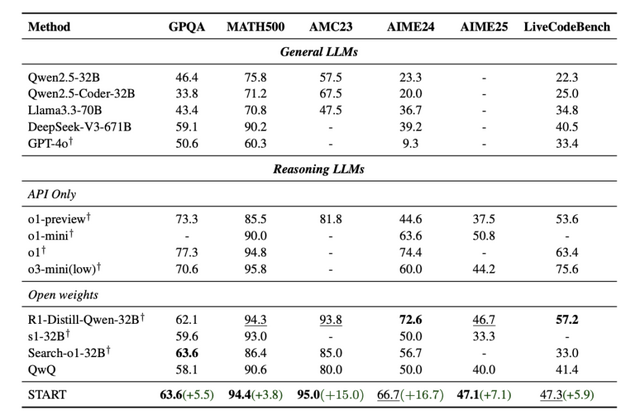
評価では、複雑なケース分析に遭遇すると、QwQ-32はハルシネーションを生成し、誤った回答を提供しますが、STARTはコードインタープリタを使用して自己デバッグし、正しい回答を提供します。数学的問題解決、科学的探究、コーディングチャレンジ、およびGPQAタスクを含む一連のベンチマークにわたる評価は、STARTが既存のモデル(QwQ、o1-mini、およびMATHベンチマークにおけるo1-previewを含む)を顕著に上回ることを示しています。

START: Self-taught Reasoner with Tools
Chengpeng Li, Mingfeng Xue, Zhenru Zhang, Jiaxi Yang, Beichen Zhang, Xiang Wang, Bowen Yu, Binyuan Hui, Junyang Lin, Dayiheng Liu
Paper
PDFからのテキスト抽出が安く高品質にできるツール「olmOCR」はGPT-4o APIより約56分の1のコスト
実際のPDFドキュメントで動作するように言語モデルをトレーニングするためのオープンソースPythonツールキット「olmOCR」。PDFや手書きメモなどからテキストを効率的に抽出します。
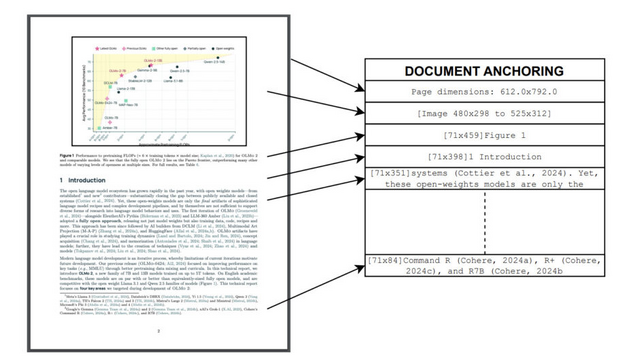
PDFには価値あるトークンが含まれていますが、その多様な形式や視覚的レイアウトがテキスト抽出を困難にしています。olmOCRはこの課題に対して、「document-anchoring」と呼ばれる独自の技術を採用しています。この技術は、PDFの視覚情報とメタデータの両方を活用し、文書の構造を保持したままテキストを自然な順で抽出することを可能にしています。
研究チームは26万ページ以上の多様なPDFから収集したデータを使用して、7B規模の視覚言語モデルを微調整しました。このモデルは、セクション、表、リスト、数式などの構造化されたコンテンツを正確に識別し、Markdown形式で表現することができます。
評価実験では、olmOCRが他の一般的なPDF抽出ツールよりも高品質な結果を生成することが示されました。
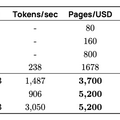
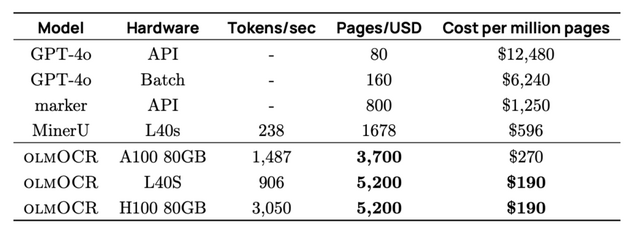
特筆すべきは、その処理効率の高さです。100万ページのPDFを約190米ドルで変換できるとされており、GPT-4oのAPIを使用した場合(1万2480米ドル)と比べて約56分の1のコストで処理が可能です。



olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models
Jake Poznanski, Jon Borchardt, Jason Dunkelberger, Regan Huff, Daniel Lin, Aman Rangapur, Christopher Wilhelm, Kyle Lo, Luca Soldaini
Paper | GitHub
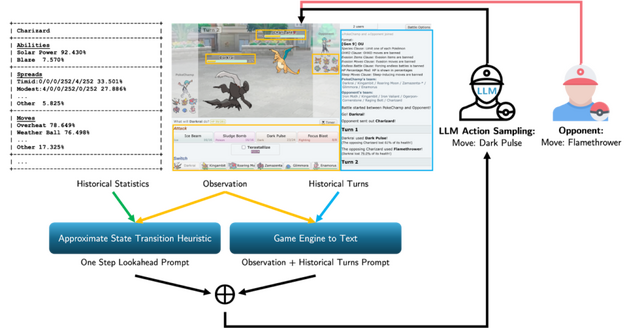
GPT-4o搭載ポケモンバトル向けAIエージェント「PokéChamp」、人間プレイヤーの最大上位10%の精度
「PokéChamp」は、大規模言語モデル(LLM)を活用したポケモンバトルのAIエージェントです。
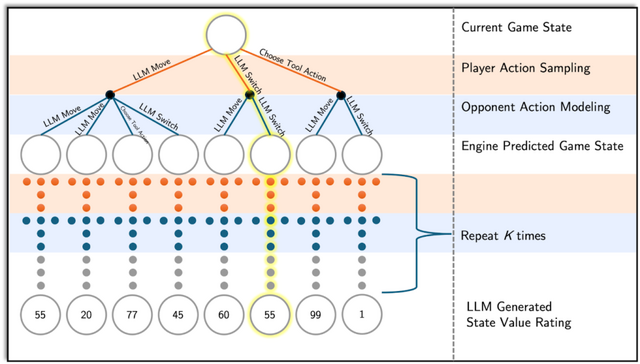
PokéChampは、チェスや将棋などの2人対戦型ゲームで使われる意思決定アルゴリズム「ミニマックスツリー探索」の3つの部分をLLMで置き換えています。具体的には、(1)プレイヤーの行動の選択肢生成、(2)対戦相手の行動予測、(3)ゲーム状況の評価を行っています。これにより、LLMの追加訓練を必要とせずに複雑なポケモンバトルの状況を効率的に分析できるようになりました。
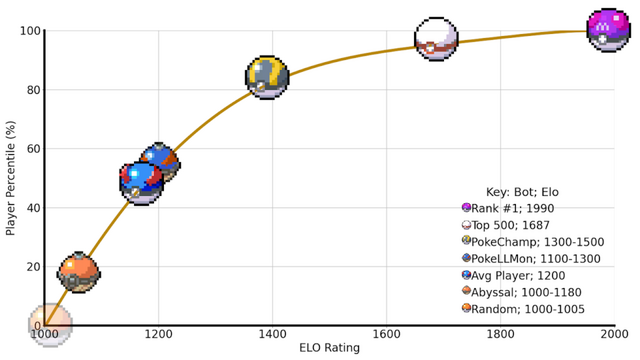
研究チームはGen 9 OU形式の評価を行い、GPT-4oを搭載したPokéChampは最強のLLMベースボットに対して76%、最強のルールベースボットに対して84%の勝率を達成しました。さらに、小規模なLlama 3.1モデルを使用した場合でも、GPT-4o搭載の従来最強ボットより64%の勝率を示しています。
オンラインのPokémon Showdownでは、PokéChampは専門家レベルの予測Eloレーティング1300-1500を獲得し、人間プレイヤーの上位30%-10%に位置しています。
PokéChamp: an Expert-level Minimax Language Agent
Seth Karten, Andy Luu Nguyen, Chi Jin
Project | Paper
マイクロソフトが小規模言語モデル「Phi-4-Mini」と小型マルチモーダルモデル「Phi-4-Multimodal」を発表
マイクロソフトが小規模言語モデル「Phi-4-Mini」と小型マルチモーダルモデル「Phi-4-Multimodal」を発表しました。
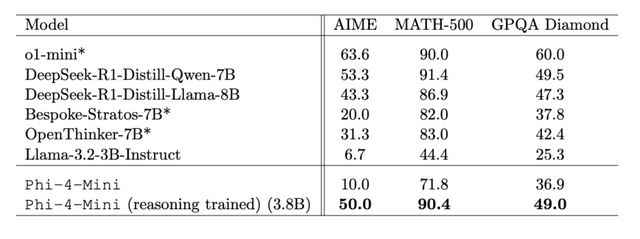
Phi-4-Miniは3.8Bパラメータという小型サイズながら、高品質なウェブデータと合成データで訓練されており、同サイズの最近のオープンソースモデルを大きく上回る性能を示しています。特に複雑な推論を必要とする数学やコーディング分野では、2倍のサイズのモデルと同等の性能を達成しています。
また、語彙サイズは20万トークンに拡張され、多言語処理能力が向上しました。さらに、Grouped-Query Attention(GQA)技術を採用し、最大128Kトークンまでの長い文脈での効率的な処理を可能にしています。
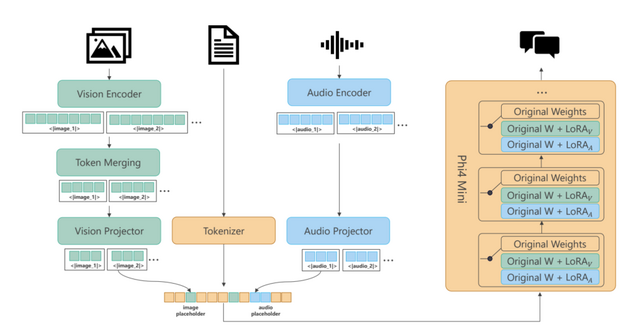
一方、Phi-4-Multimodalは5.6Bパラメータで、「mixture of LoRAs」という技術を採用しています。この技術により、基本となる言語モデルを変更せずに、画像や音声の処理能力を追加することができます。これによって本来の言語処理能力を損なうことなく、マルチモーダル機能を実現しています。
音声認識性能においては、Phi-4-MultimodalはOpenASRリーダーボードで1位を獲得し、エラー率を従来のトップモデルより5.5%改善しました。日本語を含む8つの言語での音声認識と翻訳に対応しており、30分までの長い音声の要約機能も備えています。この音声要約機能では、GPT-4oに近い水準の品質を示しています。
視覚機能においても、13の単一画像理解ベンチマークと複数画像・動画理解タスクで評価され、同サイズの他モデルを上回る結果を示しています。特にチャート理解や科学的推論タスクでは、一部のクローズドソースモデルを上回る性能を発揮しています。
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Abdelrahman Abouelenin, Atabak Ashfaq, Adam Atkinson, Hany Awadalla, Nguyen Bach, Jianmin Bao, Alon Benhaim, Martin Cai, Vishrav Chaudhary, Congcong Chen, Dong Chen, Dongdong Chen, Junkun Chen, Weizhu Chen, Yen-Chun Chen, Yi-ling Chen, Qi Dai, Xiyang Dai, Ruchao Fan, Mei Gao, Min Gao, Amit Garg, Abhishek Goswami, Junheng Hao, Amr Hendy, Yuxuan Hu, Xin Jin, Mahmoud Khademi, Dongwoo Kim, Young Jin Kim, Gina Lee, Jinyu Li, Yunsheng Li, Chen Liang, Xihui Lin, Zeqi Lin, Mengchen Liu, Yang Liu, Gilsinia Lopez, Chong Luo, Piyush Madan, Vadim Mazalov, Ali Mousavi, Anh Nguyen, Jing Pan, Daniel Perez-Becker, Jacob Platin, Thomas Portet, Kai Qiu, Bo Ren, Liliang Ren, Sambuddha Roy, Ning Shang, Yelong Shen, Saksham Singhal, Subhojit Som, Xia Song, Tetyana Sych, Praneetha Vaddamanu, Shuohang Wang, Yiming Wang, Zhenghao Wang, Haibin Wu, Haoran Xu, Weijian Xu, Yifan Yang, Ziyi Yang, Donghan Yu, Ishmam Zabir, Jianwen Zhang, Li Lyna Zhang, Yunan Zhang, Xiren Zhou
Paper