





Stable Diffusion、ChatGPTなどの生成系AIと呼ばれるテクノロジーが生まれ、その派生技術やそれらを補完する技術が矢継ぎ早に登場しています。筆者はできるだけ早いタイミングでそれを試そうとしているのですが、それでも追いつかないくらいのスピードで事は進んでいます。
今日はその中の、フェイシャルアニメーション技術について紹介します。
まず、以前作ったミュージックビデオをちょっと見てください。
ここでは、筆者の歌声をDiff-SVCというAI音声変換技術を使って妻の歌声に変換した音声と、妻の写真からStable Diffusionのカスタム学習によって生成した静止画を使っています。Memeplexで可能になったGIFアニメーションを自然に動かすためにTopaz Video AIというAIベースの超解像ソフトで動きをできるだけ滑らかにし、それをスローモーションにすることで不自然さを低減しようと試みたものです。結構な手間がかかりますが、少しでも動いているように見せるための苦肉の策です。
では次に、先ほど作ったカーペンターズの楽曲「雨の日と月曜日は」のミュージックビデオをどうぞ。オケさえあれば、こういうものを数時間でできるのが最新のAI技術のパワーによるもので、とてもありがたいことです。ちなみに以前はGoogle Colabを使わなければならなかったAI音声変換のDiff-SVCはWindowsアプリでローカルマシンで実行できるようになりました。
こちらは、Memeplexで生成した静止画の3枚を使って、リップシンクして歌っているように見せています。ここで使っているフェイシャルアニメーション技術は、D-IDという会社の「Creative Reality Studio」というサービスによるもの。
実はちょっと前からStable Diffusionにより生成された誰でもない人物像とChatGPTによるスクリプト、AI音声変換を組み合わせ、D-IDでしゃべらせるおもしろい事例があちこちから出ていて、それを試したいと思っていたのでした。
D-IDの技術は、基本的にはAIを使って人物の静止画と音声を同期させるリップシンクなのですが、そこではChatGPTによるスクリプトを生成し、それを読ませることも、音声データに合わせることもできます。元になっている静止画はリアルな写真でも、Stable Diffusionで生成したものでも可能。D-IDは静止画とオーディオデータから動画を生成する機能も提供しています。
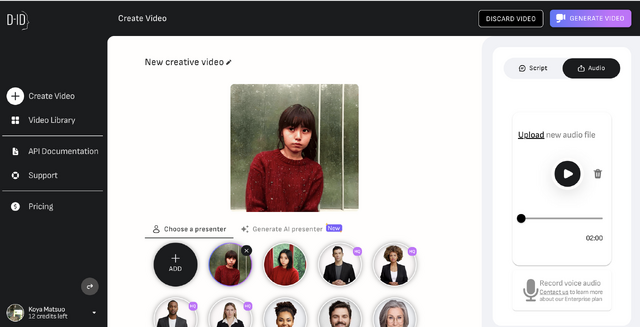
▲写真と音声を指定し、動画を生成する
さきほどの動画は、Diff-SVCで生成した歌声に同期させる機能を使ったものです。無料でも使えますが、利用できる分数に制限があり、ウォーターマークも入ります。月額プランでこれらの制限が緩くなります。自分は月額49.99ドルのProプランに入りました。それでも1カ月で15分までしか使えないのが残念なところです。
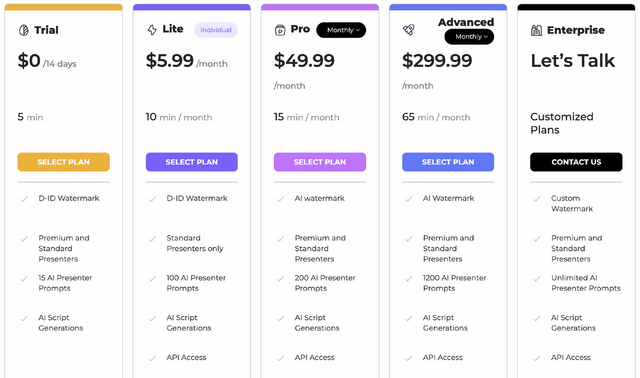
▲無料プランもあるが、5分まで
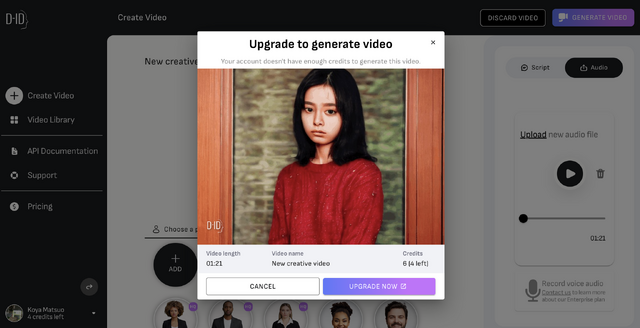
▲制限に達すると「上のプランにしないと動画が生成できないよ」とアラートができる
勝手にしゃべらせる動画を作るのは「フェイクビデオを手軽に生み出せる危険な技術だ」という議論は当然あると思いますが、実は、この種の技術はだいぶ前からあります。例えばMotion Portraitという技術はもともとソニー木原研究所で開発され、その後モーションポートレートという新会社に引き継がれました。iPhoneが登場した2007年にアプリ化され、現在も提供が続けられています。フェイシャルアニメーションソフトとしてはReallutionのCrazyTalkが有名ですし、Adobeも同様の技術を提供しています。
筆者は妻の写真を使ってフェイシャルアニメーションができないかと新しい技術が出るたびに試してみましたが、なかなか満足できるレベルには至りませんでした。
ただ、D-IDの技術はこれまでの技術とはリアルさ、自然さという点で抜きん出ていると思います。ちょっと口の開き方が大げさなので不自然さは残りますが、そのあたりの調整ができるようになれば、本物と見分けがつかないレベルの動画が作成できると考えます。
ジェネレーティブAIが開けたパンドラの箱からは次々と新しい技術が飛び出していますが、それらを組み合わせることでできることがさらに広がっています。願わくばこうした技術が悪用されず、人々の役に立てるようにと考えます。
あまりに手軽に動画が作成できるので、もう1つ作ってみました。先日紹介した、2万円以下のピアノをiPadのGarageBandにBluetooth MIDIで接続して伴奏を弾いたものに、筆者が仮歌を重ねて録音。そのボーカルトラックをDiff-SVCで妻の歌声に変換しました。そこに、Memeplexで生成した妻の写真をD-IDのCreative Reality Studioでリップシンクしたものです。

Creative Reality Studioで筆者がサブスクしているProプランでは、1点生成するたびにポイントの残高が減っていく仕組みで、おそらく1分の生成につき3ポイントが減っていくようです。あまり無駄遣いはできないのですが、出てきた口パクがあまりに不自然だとベースの写真を変更して再出力したいので、なかなか難しいところです。
そしたら、Twitterで@koguさんが便利そうな技術を教えてくれました。
これはThin-Plate-Spline-Motionという、256×256という低解像度という欠点はあるものの、アップスケールさえできればリアルな表情が作れる、表情転写のAIモデルです。歌に合わせて録画も残しておいて、仮歌だけでなく、フェイシャルモーションキャプチャもやってしまう感じですね。
こちらも折を見て試してみたいです。



