







おいおいまたかよ、驚き屋かお前はと言われそうですが、またゲームチェンジャーなんですよ。ほんとすいません。全部AIが悪いんです。
AI関連はちょっと目を離すと取り残されてしまいます。後から来たのに追い越され、泣くのが嫌なら歩いていくしかないのです。今回、それが再びAI音声合成で起きました。
筆者はAIアートグランプリを受賞したおかげでいろいろなところから取材を受けたり自分でも解説記事を書いたりしていますが、その中で、Diffusion(拡散)モデルを使ったDiff-SVCというAI声質変換によってリアルな元音声を再現できると説明してきました。ですが、これからは「実は今は新しいAI技術を使っているんですよ」と付け加えなければいけません。

妻の歌声を合成するのに使っていたDiff-SVCから別の新しい技術に乗り換えてしまったのです。
Diff-SVCが出た後に、So-VITS-SVC(SoftVC VITS Singing Voice Conversion)、Fish-SVCという競合技術が発表されたため、それを試さなければならないなあと思いつつ、「でもGoogle Colabでちんたら学習するのも時間かかるし、かといってローカルマシンにインストールするのも大変な手間がかかるからなあ。誰か完パケのアプリ作ってくれないかしら」とのんびりしていたら、「RVC WebUI」という、ちょうどいいアプリが出ていました。
▲RVC WebUI
Stable Diffusionを自分のWindows PCで制限なしに動かせると人気の「Stable Diffusion Web UI」と同じく、PythonやPyTorchやもろもろが1つのWindows用のパッケージに収められていて、起動はバッチファイルで一発。UIはローカルのURLを叩けばよくてGUIで操作できます。
ただ、このソフトが使っている技術はSo-VITS-SVCでもFish-SVCでもなく、「RVC」という、それまで聞いたことのない代物だったのです。
Retrieval-based-Voice-Conversion
Retrieval-based-Voice-Conversionの略であるというRVCとは、基本が中国語で難易度が高いにもかかわらず多くの人が飛びついていて、ネットでも評判になりつつあります。サンプルを聞くとそれなりに良さそうだけど、Diff-SVCと比べていいのか悪いのかは判断がつかない。そんな状態でした。
「RVC」+「VC Client」で自分の声を任意の声にリアルタイム変換しよう!という記事やAI音声総合というDiscordサーバなどを参考にして動かせるようになったのが先週金曜日の夜ですから、まだ2日目くらいです。フロントエンドの日本語ローカライズが進行中のようですが、まだ不具合があるということで、有志の方々による解説記事を見ながら中国語のままでインストール。学習を終えて変換を試してみたところ、これが実に良い出来栄えなのです。
Diff-SVC版の「妻音源とりちゃん[AI]」(10年前に他界した妻の歌声と喋り声1時間分を学習させてできたAI音声モデル)は本人とかなり似ているのですが、一部で手直しが必要な部分、それでも直せないところがありました。
具体的には、低音部分。例えばカレン・カーペンターの低音くらいになると、声が掠れてしまい、うまく変換できません。また、ブレス部分のf0(ピッチ)をうまく取得できずにビープ音になったりもします。また、声質がちょっと男声よりになってしまい、もっと柔らかい女性らしい声にするにはフォルマントをいじったりする必要も部分的には出てきていました。
RVCではそうした問題は発生せず、ほとんどそのままで本人性の高い、これまででベストの(といっても試したのはUTAU-SynthとDiff-SVCだけですが)妻音源とりちゃんになりました。思わず微笑んでしまうくらい愛らしい感じが出ています。音の解像度は少し落ちる感じですが、全体的にはとても良いです。これからはRVCをメインにしようと決めました。
作例として、ピンポンパン版「雨に濡れても」、「レインドロップ」(Raindrops Keep Fallin' On My Head)を作ってみました。画像は例によってMemeplexで妻の写真から生成したイメージです。左チャンネルは筆者の元ボーカルで、右チャンネルが妻音源とりちゃん[AI] RVCとなっています。だいぶ自然だと思うのですが、どうでしょうか。
無音部分で少しだけホワイトノイズが乗るのが気にはなるのですが、難点はそのくらいで、簡単に消去できるし、大きな問題はありません。比較すると、ボーカル音域がDiff-SVCよりもかなり広範囲のようです。低音域だけでなく、高音域でもシャリシャリ音にならず、人間らしい発声になっているのはありがたいです。
いきなり変換後の話を書いてしまいましたが、実は学習もすごいのです。Diff-SVCは高い精度にするためには高速GPUによる長時間の計算が必要で、筆者はGoogle ColabのPro課金で17時間回したものを使っています。これより高性能なAIモデルを、RVCでは21分で学習しています。1時間分の音声ファイルの学習が実時間の3分の1で済んでしまうというのは驚異的と言わざるを得ません。ちなみに筆者のマシンは、ガレリアのNVIDIA RTX 4080搭載マシン(AIアートグランプリの賞品)で、早速活用しています。
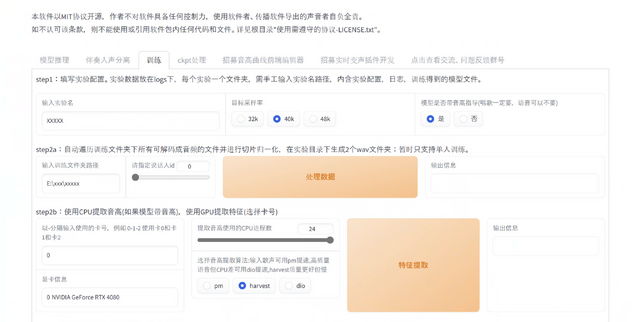

▲上が学習の、下が推論の画面。タブで切り替える
推論(変換)も高速です。3分43秒の変換が50秒を切ります。Diff-SVCでは同じマシンで2分以上はかかっていたので、数倍は高速化されています。
このくらい推論が高速だと何が期待できるかというと、自分の声をそのまま別の声にリアルタイムで置き換える、リアルタイムボイチェン(ボイスチェンジャー)です。
リアルタイムボイチェンは、例えばVRChatで使いたいという人は多いみたいです。VRChatなどのVR環境では自分とは異なるアバターになることが多いので、見た目に合わせた音声にしたいというニーズはあるようで、そういった人たちにとってはとても良いソリューションとなりそうです。VTuberのバ美肉勢にもニーズがあるようです。
AI声質変換によるリアルタイムボイチェンは、3月28日に開催されたバンダイナムコ研究所のデモ「ELMIRAIVE | VOX」で試させてもらいました。「最近So-Vits-SVCってのがリアルタムボイチェンできるらしいですよ」と担当者の人と話していたんですが、それから10日くらいしか経ってないのに世の中がどんどん進んでいっている、恐ろしい世界です。

▲バンダイナムコ研究所のAIリアルタイムボイチェンデモ
リアルタイムAIボイチェンの世界へようこそ
では、リアルタイムボイチェンをRVCでどうやるかというと、リアルタイムボイチェンに特化した専用ソフトがあるので、そちらを使います。「VC Client for RVC」というソフトです。
言い忘れましたが、RVCで学習させるにはNVIDIAのビデオカードでVRAMが6GB以上ないといけないそうなのです。じゃあ、外出先でそれを使うとなるとParsecなどのリモートデスクトップか、ゲーミングノートPCが必要だよね、ということで手頃なゲーミングノートを探していました。4月8日のポッドキャストbackspace.fm放送中に、「いいのないですかね? ただで」と西川善司さんとドリキンに相談をしていて「やる気のないやつは帰れ」とか言われていました。
ところがギッチョン。4月9日、VC Client開発者であるwok!さんによるこんなツイートがあったのです。
RVCのリアルタイムボイチェンは、Apple Silicon MacであればCPUのみで可能……。CUDAなくてもいいのか。これは歓喜せざるを得ません。
NVIDIA製GPUを積んだWindowsマシンで学習したAIモデルの必要ファイル3個をMacにコピーして、ソフトを走らせれば普通に動きます。Discordで試してみたところ、ちゃんと会話が成立するくらいの性能であることが実証されました。遅延は500msを切るくらい。ゲーミングノートいらなかった。
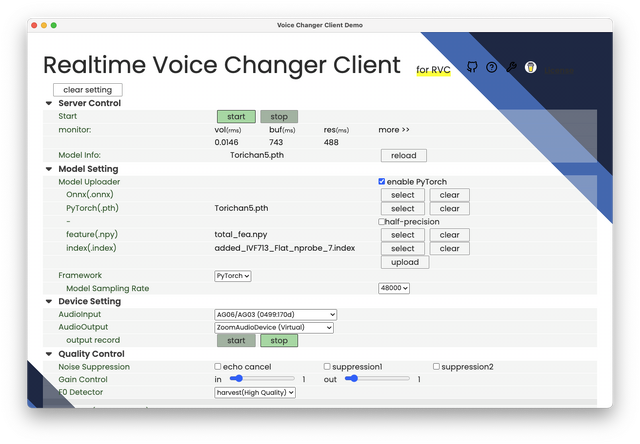
▲M1 Mac miniで動作させたVC Client for RVC
外出中に突然、別人の声で発声したいというニーズにも対応できます。蝶ネクタイ型ボイチェンマイクはまだ現実世界に登場していないようですが、Shiftallのmutalkで自分の声を消音し、M2 MacBook Airで自分の音声をリアルタイムで別人の声に変換してスピーカーから流せば、コナンくんごっこも可能です。あとは殺人事件と名推理さえあれば。


▲これなら怪しまれないはず
学習対象の声を権利的に問題ないものにしておくのは当然のこと。そして、ここまで手軽に学習・変換できてしまうと、特殊詐欺に使われることも十分に考えられます。その声は本物か?ということを常に疑うとか、そもそも声で重要なことを判断してはいけないとか、そんな時代に突入しているのかもしれません。
著作権侵害した音声モデルの登場で一時期公開を見合わせていたDiff-SVCのGoogle Colabも現在は公開を再開しています。複数の技術が登場している以上、この流れを止めるのは非常に難しいでしょう。

そして、この記事を書いてるそばから新しい技術が出てきてます。DDSP-SVCというAIリアルタイムボイチェンは、100msという低遅延を実現しているそうです。現状、音質は良くないらしいので自分は使わないと思いますが、実に凄まじい状況です。


