


ChatGPTなどAIチャットボットが基礎とするLLM(大規模言語モデル)は、特定の言葉の後に確率的に続きそうな言葉を並べてテキストを生成します。そのため、原理的には同じ質問に対して同じ回答を出力することは稀なはずです。
が、少し前のGPT-3.5を使ったChatGPTにジョークを言わせたところ、約90%が同じ25個のジョークに占められていたとの研究結果が発表されています。
ドイツ航空宇宙センター(DLR)とダルムシュタット工科大学に属する2人の研究者らは、OpenAIのChatGPTがどれだけユーモアを理解して生成する能力を持つかを検証する論文を発表。LLMの内部構造やデータセットにアクセスすることなく、純粋にプロンプトベース、つまり質問と応答を通じて、ChatGPTが人間のユーモアを把握し、自らがジョークを生み出す能力を探っています。
そのため、ジョークの出力、ジョークの説明、そしてジョークか否かの判定という三種類のテストを実施。
まず「出力」のタスクについて、ChatGPTのジョークがどれほど豊富か検証するため、1000回ジョークを言うように依頼したところ、すべての回答は文法的に正しく、ほぼ全てに1つずつジョークが含まれていました。複数のプロンプトで検証したものの、プロンプトによる回答の傾向には、" Jokes "と複数形で尋ねたものに複数のジョークを返す傾向を除けばほぼ変化がなかったとしています。
結果は同じジョークが頻出し、重複を除けば128種類のジョークを出力しました。うち上位25種が回答の約90%を占めています。そのトップが「Q: Why did the scarecrow win an award? A: Because he was outstanding in his field.」(Q:カカシはなぜ賞を取ったのでしょう?A:その分野で並外れていたからです)で140回、2位が「Q:Why did the tomato turn red? A: Because it saw the salad dressing.」(Q:トマトはなぜ赤くなったのでしょう?A:サラダのドレッシングを見たからです)の122回だったとのこと。
前者はカカシが「立っている(stand)」と「傑出している(outstanding)」「畑 / 分野 (field)」を引っかけたもの。後者は「トマトが赤くなる(turn red)」のが「サラダが着替えているところ(dressing)」を見たからだと擬人化した言葉遊びです。
ほか「Q: Why was the computer cold? A: Because it left its Windows open.」(コンピュータはなぜ冷えたのでしょう?A: Windowsを開いていたから)も23個あり。こちらはOSのWindowsと「窓を開けっ放しだったから」をかけています。
また「説明」のタスクについては、上位25の頻出ジョークにつき説明を求めたところ、大半は言葉遊びやダブルミーニングなどの要素を説明できることが示されました。しかし、人間からはジョークとして成立していないような出力について説明せよというと、一見もっともらしいが意味の通らない説明を作り上げています。
例えば「Why did the cookie go to the gym? To get a-cookie-dized.」との出力はどこが面白いのかを質問すると、ChatGPTは「このジョークは言葉遊びです。To get 'a-cookie-dized' は、'to get categorized' の駄洒落で、'cookie' が 'categorized' に置き換えられています。クッキーを人に見立てて、より健康的になるようジムに通っているというジョークであり、クッキーが特定のカテゴリーや型にハマろうとしていることを暗示しているのです」と返しました。
最後の「判定」のタスクとしては、ChatGPTが出力するジョークが文体的な構造(Q&A形式)、コミカルな要素(「言葉遊び」)、話題(日常的でない状況、たとえば物体の擬人化等)の3要素を備えることに着目。
ChatGPTが出力した、人間からも成立しているジョークについて、それぞれの要素を意図的に取り除き、一見したところジョークのように見えるが肝心の部分が抜けているサンプル文を用意し、ChatGPTにどのような種類の文章か回答を求めました。
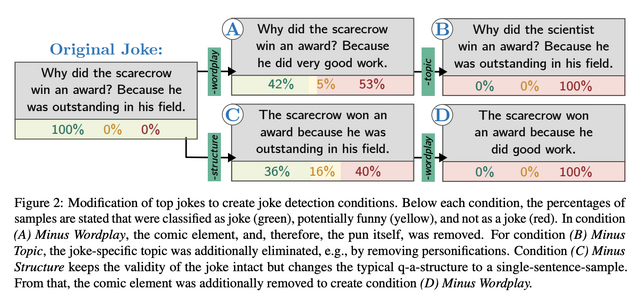
三要素のうちひとつが抜けたサンプルについてはジョークである、ジョークでないとの回答がほぼ半々。二つの要素を抜いたサンプルについては、ジョークであると判定することはありませんでした。つまり、一見ジョークの定形のような出だしと落ちの形式だけ備えていても、ジョークだと誤判定しない程度の判断能力を備えていることになります。
今回の研究はGPT-3.5のジョーク生成と説明の限界を検証したかっこうですが、一方ではジョークかどうかを上記の3要素を総合して識別していることを「ユーモア要素に一定の理解があると示している」と肯定的に捉えています。
研究者らは、今後もLLMにおけるユーモアの研究を続け、特にOpenAIのGPT-4を評価すると予告しています。AIチャットボットがユーモアを深く理解して、オリジナルの秀逸なジョークを生み出せるようになれば、人間の作家などの存在意義がますます脅かされるのかもしれません。
Sophie Jentzsch, Kristian Kersting, " ChatGPT is fun, but it is not funny! Humor is still challenging Large Language Models " (2023)
https://doi.org/10.48550/arXiv.2306.04563