









9月は個人的なイベントがいろいろあります。自分の誕生日と、その前日の結婚記念日がまずあって、まあそれはもう誰も祝う人がいないので一人でケーキを買ってきたり英国リバプールの郷土料理であるスカウスを、クックパッドに残された妻のレシピで作ったりしています。
9月はもう一つ、記念日があるのですが、そちらの方はすっかり忘れていました。
妻が遺してくれた歌声の断片から合成したUTAU音源である「妻音源とりちゃん」による最初の楽曲「ひこうき雲」をニコニコ動画で公開したのが2013年9月1日だったのです。「あれから10年が過ぎたのだなあ」と感慨に浸るのも忘れてやっていたことといえば、やはりAI妻音源による楽曲と生成AIによるミュージックビデオ制作でした。土日はずっとこれにかかりきり。
それが出来上がったので先ほどYouTube公開しました。
曲はユーミン作曲の「時をかける少女」。原田知世バージョンを、妻音源とりちゃん[AI]に歌ってもらいました。仮歌は自分がやって、それをもとに、妻の歌声など1時間分の音源から生成したAIモデルによって声質変換を行うという仕組みです。現在は、最初に使ったDiff-SVCではなくRVCという技術を使っています。

オケはGarageBandで制作。2021年6月にNHKの番組に出演したとき、ライブハウスで演奏した曲なので、オケはほぼそのときのままです。下のビデオの4分ちょっと過ぎあたり。このときはAIを使うとか予想してませんでした。
自分で投稿したミュージックビデオはこちら。数少ない写真を使い回ししています。
今回のバージョンは、リードボーカルだけではなく、ミュージックビデオも違います。とりちゃん(妻のニックネーム)が歌っているかのような、リップシンクを全編にわたって取り入れてみました。
そのときに使ったやり方を紹介します。
写真や画像をもとに、音声に合わせてリップシンク(口パク)させる手法は昔からありました。iPhoneアプリのMotion PortraitやPC/MacアプリのCrazyTalkといったものが10年以上前から使われています。しかし、動きが自然ではなかったので、妻の歌唱に使うことはしませんでした。
・増毛、眼鏡、福笑いまで 顔写真が動いてしゃべる「MotionPortrait」のこんな使い道
希望が持てるようになったのは、D-IDという生成AIサービス会社が「Creative Reality Studio」というサービスを提供していることを知ってからです。有償のサービスですが、1枚の写真と音声ファイルから高品質なリップシンク動画を生成できます。さらに、Stable Diffusionなどと組み合わせるオープンソースのプラグインで「SadTalker」というソフトも登場しました。こちらは全くの無料で、ローカルマシンで生成できます。
この2つをうまく組み合わせたら1曲丸ごとリップシンクできるのではと考えてやってみたのですが、実は両方とも短所があって、実用にはなりませんでした。
D-IDの方は、画像は綺麗なのですが、顔を傾けたときに顔に大きな歪みが生じるという致命的な欠点があります。顔を大きく動かさないというオプションもないので、長い時間喋りっぱなし、歌いっぱなしにすることはできません。この欠点はいつまで経っても修正されません。
SadTalkerの方は、顔を動かし過ぎてしまうという問題があって、普通そこまでは動かさないでしょ、というくらい小刻みにあちこち動きます。この動きを止めて、口元だけ動かすというオプションもあるのですが、それだとまた不自然。その中間地点くらいがいいんですけど。

▲SadTalkerの例
といった感じで悩んでいるという話をXに投稿していたら、識者の方からいいサービスがあると教えてもらったのが、今回のミュージックビデオで使った「HeyGen」です。
既存のオーディオファイルと静止画があれば、そこからリップシンク動画を作成できるというのはD-IDと同様で、同じくサブスクリプション制の有償サービスなのですが、何よりその動きが圧倒的に自然なのです。
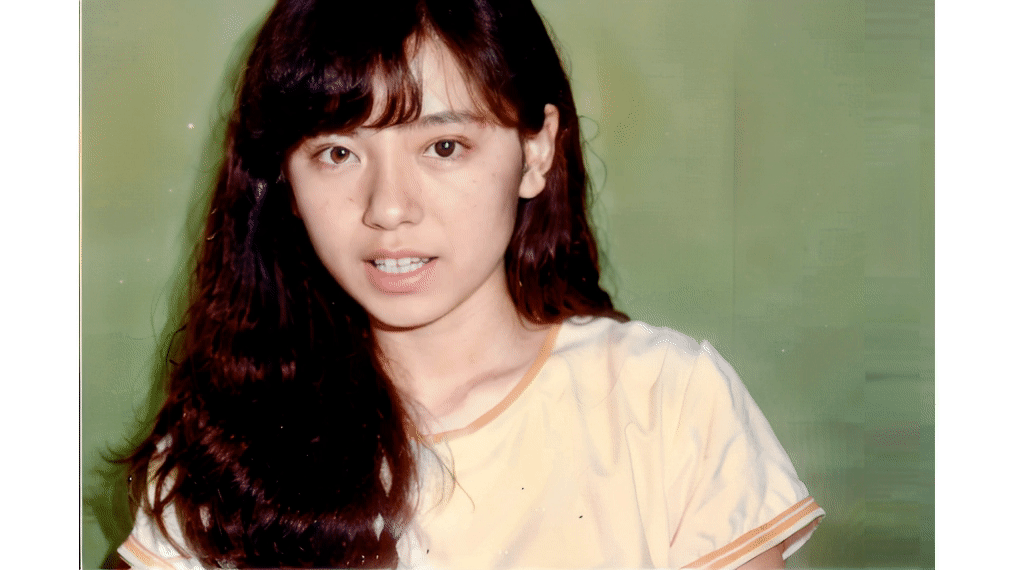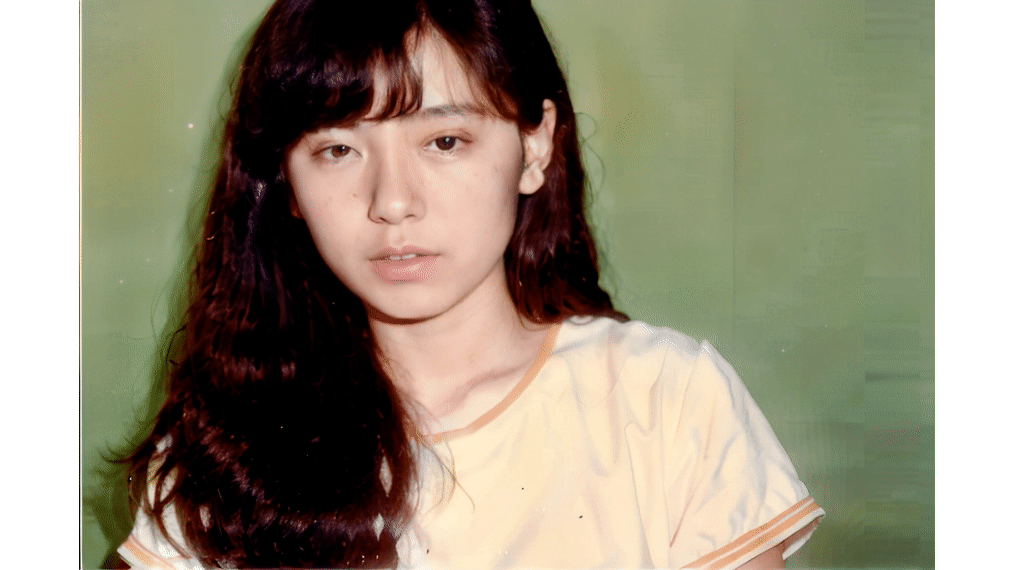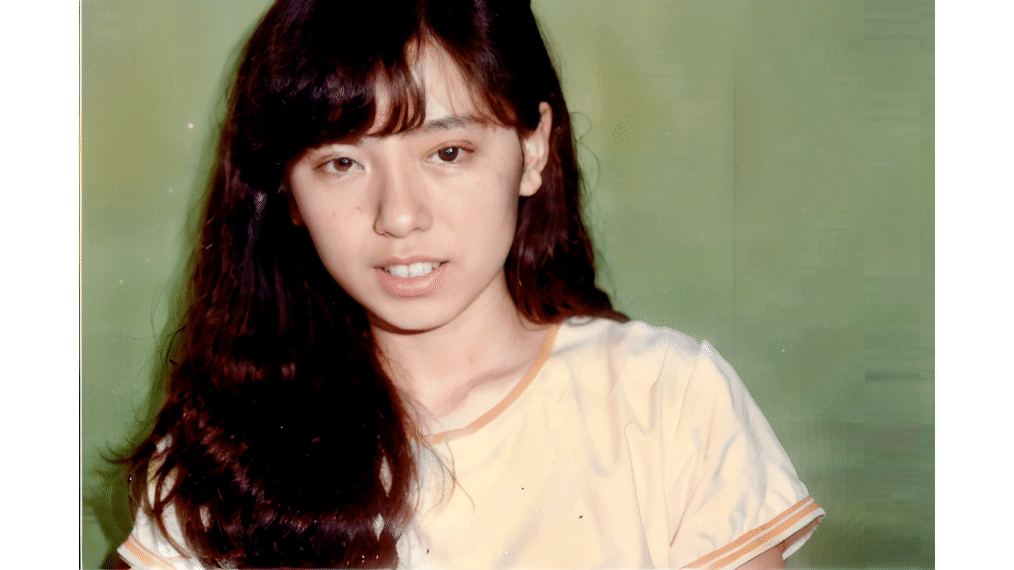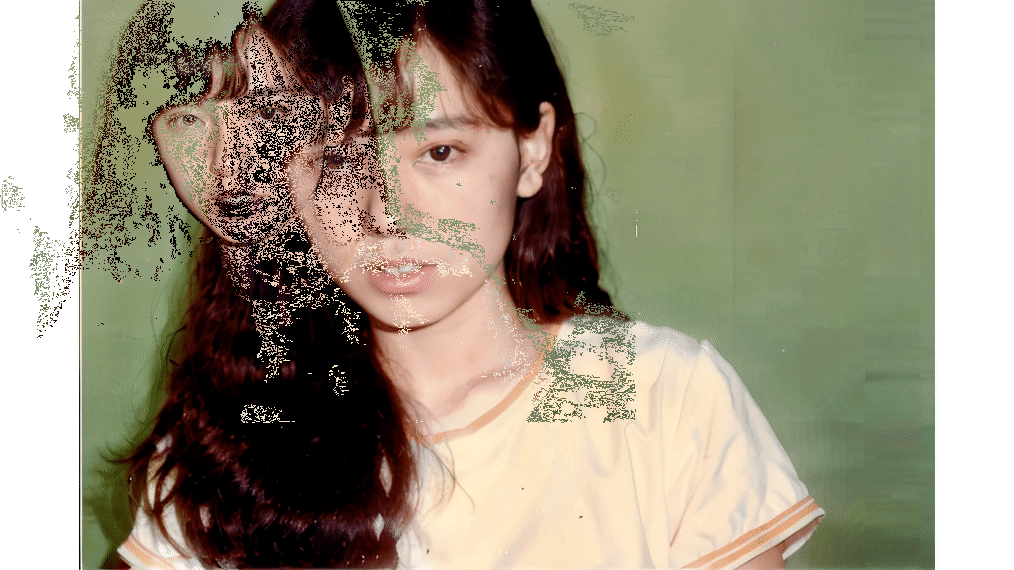
▲HeyGenの例
もちろんリアルな人間と比べれば微妙におかしい部分はあるでしょうが、許容範囲に収まっていると思います。もうD-IDは見限ってサブスクはやめようと思います。
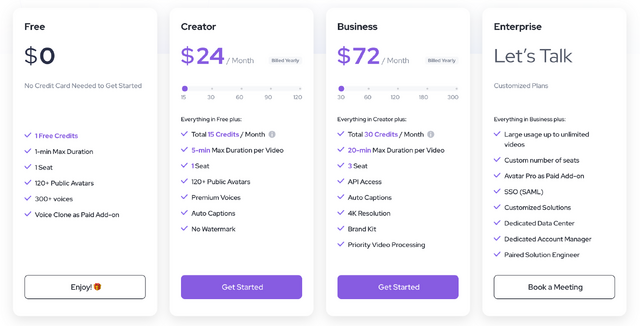
HeyGenの料金体系はこんな感じ。自分は月額24ドルのCreatorプランをサブスクしています。このプランでは月に15ポイント使えるのですが、今回のミュージックビデオ制作ではちょうどそのくらいのポイントを使いました。もっと頻繁に制作するのであれば、上位のBusinessプランが必要になりそうです。
今回は、妻の写真をもとに生成した画像をベースにして、RVCで自分の仮歌から妻の歌声に変換した音声ファイルを組み合わせて約20本の動画をHeyGenで作成。それをトランジションさせて、音楽と合わせました。それぞれの動画フレームを少しずつ動かすことで、より自然になるようにしたつもりです。
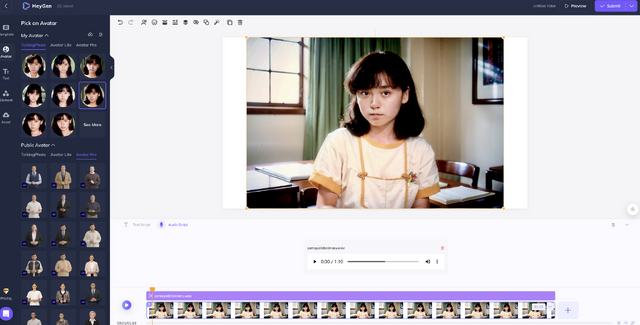

1月末に第一回AIアートグランプリに応募したときは、まだ間に合っていなかった動画も、リップシンクだけですが、このくらいまではきています。他の動画生成技術も、AnimateDiff、FaceFusion、Runway Gen-2など、有望なものが多数あります。


8月31日にスタートして9月20日まで申し込める第二回AIアートグランプリは、こうした最新AI動画生成技術、大規模言語モデルやコード生成技術を上手く使ったものなど、いろんな作品が出てくることでしょう。楽しみです。
そして、その最終審査と、AIハッカソンを行う「第一回AIフェスティバル Powered by GALLERIA」なるイベントも11月3日と4日に開催されます。落合陽一さんをはじめとするすごいゲストの皆様に混じって、筆者も第一回グランプリ受賞者として何かプレゼンすることになっています。


まずはリップシンクでここまでというところは紹介するとして、残りは何をやるか、これから考えてみようと思います。第二回AIアートグランプリの締切まであと2週間。素晴らしいAIクリエイターのみなさんとリアルでお会いできるのが今から楽しみです。



